Volume Cluster Profile [VCP] (Zeiierman)█ Overview
Volume Cluster Profile (Zeiierman) is a volume profile tool that builds cluster-enhanced volume-by-price maps for both the current market window and prior swing segments.
Instead of treating the profile as a raw histogram only, VCP detects the dominant volume peaks (clusters) inside the profile, then uses a Gaussian spread model to “radiate” those peaks into surrounding price bins. This produces a smoother, more context-aware profile that highlights where volume is most meaningfully concentrated, not just where it happened to print.
On top of the live profile, VCP automatically records historical swing profiles between pivots, wraps each segment for clarity, and can project the most recent segment’s High/Low Value extensions (VA/LV) forward to the current bar to keep key structure visible as price evolves.
█ How It Works
⚪ 1) Profile Construction (Volume-by-Price)
VCP builds a volume profile histogram over a chosen window (current lookback, or a swing segment):
Range Scan
The script finds the full min → max price range inside the window.
Bin the Range
That range is divided into a user-defined number of Price Bins (rows). More bins = finer detail, but heavier computation.
Accumulate Volume into Bins
For each bar inside the window, the script takes the bar’s close price, determines which price bin it belongs to, and adds the bar’s volume to that bin.
float step = (maxPrice - minPrice) / binsCount
for i = 0 to barsToUse - 1
int b = f_clamp(int(math.floor((close - minPrice) / step)), 0, binsCount - 1)
volBins += volume
Result: volBins becomes a standard volume-by-price histogram (close-based binning).
⚪ 2) Cluster Detection (Finding Dominant Peaks)
Once the raw histogram is built, VCP identifies cluster centers as the most meaningful volume “hills”:
Local Peak Test
A bin becomes a cluster candidate if its volume is greater than or equal to its immediate neighbors (left/right).
Filter Weak Peaks
Peaks must also be above a basic activity threshold (relative to the average bin volume) to avoid noise.
bool isPeak = v >= left and v >= right
if isPeak and v > avgVol
array.push(clusterIdxs, b)
Keep the Best Peaks Only
If too many peaks exist, the script keeps only the strongest ones, capped by: Max Cluster Centers
Result: clusterIdxs = the set of dominant profile peaks (cluster centers).
⚪ 3) Cluster Enhancement (Gaussian Spread Model)
This is what makes VCP different from a raw profile.
Instead of using volBins directly, the script builds an enhanced profile where each cluster center influences nearby price bins using a Gaussian curve:
Distance from each bin to each cluster center is computed in “bin units”
A Gaussian weight is applied so that bins near the center receive stronger influence, while bins farther away decay smoothly.
Cluster Spread (sigma) controls how wide this influence reaches: low sigma produces tight, sharp clusters, while high sigma results in wider, smoother structure zones.
enhanced += centerV * math.exp(-(dist*dist) / (2.0 * clusterSigma * clusterSigma))
volBinsAI := enhanced / szClFinal
Result: volBinsAI = the cluster-enhanced volume value for each bin.
In practice, VCP turns the profile into a structure map of dominant volume concentrations, rather than a simple “where volume printed” histogram.
⚪ 4) POC from the Enhanced Profile
After enhancement:
The bin with the highest volBinsAI becomes the POC (Point of Control)
POC is plotted at the midpoint price of that bin
if volBinsAI > maxVol
maxVol := volBinsAI , pocBin := b
So the POC reflects the cluster-enhanced profile rather than the raw histogram.
█ How to Use
⚪ Read Cluster Structure (Default = 2 Clusters)
By default, the Volume Cluster Profile (VCP) is configured to detect up to 2 dominant volume clusters within the profile. These clusters represent price zones where the market accepted trading activity, not just where volume printed randomly.
⚪ When TWO Clusters Appear
When VCP detects two distinct clusters, it usually indicates:
Two competing areas of value
Ongoing auction between higher and lower acceptance zones
Treat each cluster as an acceptance zone
Expect slower price action and rotation inside clusters
Expect faster movement in the low-volume space between clusters
Use cluster-to-cluster movement as:
rotation targets
range boundaries
acceptance vs rejection tests
Typical behavior:
Price enters a cluster → stalls, consolidates, rotates
Price rejects at cluster edge → moves toward the opposite cluster
⚪ When ONLY ONE Cluster Appears
If VCP detects only one cluster, or if two clusters visually merge into one:
Volume is no longer split
The market has formed a single dominant value area
Price consensus is strong
Treat the cluster as the primary value anchor
Expect pullbacks and reactions around this zone
Bias becomes directional:
Above the cluster → bullish context
Below the cluster → bearish context
Inside the cluster → balance/chop
This structure often appears during clean trends or stable equilibria.
⚪ VA/LV Extensions
VCP projects two zones from the end of the most recent swing segment:
VA extension = the segment’s highest enhanced-volume bin (dominant zone)
LV extension = the segment’s lowest enhanced-volume bin (thin/weak zone)
A breakout of the VA extension signals acceptance and potential continuation. A retest of the VA or LV extension is used to confirm acceptance or rejection, while rejection from either zone often leads to rotation back toward value.
█ Settings
Cluster Volume Profile
Lookback Bars – how many recent bars build the current profile
Price Bins – profile resolution (more bins = more detail, heavier CPU)
Cluster Spread – Gaussian sigma; higher values widen/smooth cluster influence
Max Cluster Centers – cap on detected peaks used in enhancement
Historical Swing Cluster Volume Profile
Pivot Length – swing sensitivity (larger = fewer, broader segments)
Max Profiles – how many historical segments to retain
Profile Width – thickness of each historical profile
High & Low Value Area
Profile VA/LV – extend the last segment’s top-bin and low-bin zones forward
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
Göstergeler ve stratejiler

DeeptestDeeptest: Quantitative Backtesting Library for Pine Script
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ OVERVIEW
Deeptest is a Pine Script library that provides quantitative analysis tools for strategy backtesting. It calculates over 100 statistical metrics including risk-adjusted return ratios (Sharpe, Sortino, Calmar), drawdown analysis, Value at Risk (VaR), Conditional VaR, and performs Monte Carlo simulation and Walk-Forward Analysis.
█ WHY THIS LIBRARY MATTERS
Pine Script is a simple yet effective coding language for algorithmic and quantitative trading. Its accessibility enables traders to quickly prototype and test ideas directly within TradingView. However, the built-in strategy tester provides only basic metrics (net profit, win rate, drawdown), which is often insufficient for serious strategy evaluation.
Due to this limitation, many traders migrate to alternative backtesting platforms that offer comprehensive analytics. These platforms require other language programming knowledge, environment setup, and significant time investment—often just to test a simple trading idea.
Deeptest bridges this gap by bringing institutional-level quantitative analytics directly to Pine Script. Traders can now perform sophisticated analysis without leaving TradingView or learning complex external platforms. All calculations are derived from strategy.closedtrades.* , ensuring compatibility with any existing Pine Script strategy.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ ORIGINALITY AND USEFULNESS
This library is original work that adds value to the TradingView community in the following ways:
1. Comprehensive Metric Suite: Implements 112+ statistical calculations in a single library, including advanced metrics not available in TradingView's built-in tester (p-value, Z-score, Skewness, Kurtosis, Risk of Ruin).
2. Monte Carlo Simulation: Implements trade-sequence randomization to stress-test strategy robustness by simulating 1000+ alternative equity curves.
3. Walk-Forward Analysis: Divides historical data into rolling in-sample and out-of-sample windows to detect overfitting by comparing training vs. testing performance.
4. Rolling Window Statistics: Calculates time-varying Sharpe, Sortino, and Expectancy to analyze metric consistency throughout the backtest period.
5. Interactive Table Display: Renders professional-grade tables with color-coded thresholds, tooltips explaining each metric, and period analysis cards for drawdowns/trades.
6. Benchmark Comparison: Automatically fetches S&P 500 data to calculate Alpha, Beta, and R-squared, enabling objective assessment of strategy skill vs. passive investing.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ KEY FEATURES
Performance Metrics
Net Profit, CAGR, Monthly Return, Expectancy
Profit Factor, Payoff Ratio, Sample Size
Compounding Effect Analysis
Risk Metrics
Sharpe Ratio, Sortino Ratio, Calmar Ratio (MAR)
Martin Ratio, Ulcer Index
Max Drawdown, Average Drawdown, Drawdown Duration
Risk of Ruin, R-squared (equity curve linearity)
Statistical Distribution
Value at Risk (VaR 95%), Conditional VaR
Skewness (return asymmetry)
Kurtosis (tail fatness)
Z-Score, p-value (statistical significance testing)
Trade Analysis
Win Rate, Breakeven Rate, Loss Rate
Average Trade Duration, Time in Market
Consecutive Win/Loss Streaks with Expected values
Top/Worst Trades with R-multiple tracking
Advanced Analytics
Monte Carlo Simulation (1000+ iterations)
Walk-Forward Analysis (rolling windows)
Rolling Statistics (time-varying metrics)
Out-of-Sample Testing
Benchmark Comparison
Alpha (excess return vs. benchmark)
Beta (systematic risk correlation)
Buy & Hold comparison
R-squared vs. benchmark
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ QUICK START
Basic Usage
//@version=6
strategy("My Strategy", overlay=true)
// Import the library
import Fractalyst/Deeptest/1 as *
// Your strategy logic
fastMA = ta.sma(close, 10)
slowMA = ta.sma(close, 30)
if ta.crossover(fastMA, slowMA)
strategy.entry("Long", strategy.long)
if ta.crossunder(fastMA, slowMA)
strategy.close("Long")
// Run the analysis
DT.runDeeptest()
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ METRIC EXPLANATIONS
The Deeptest table displays 23 metrics across the main row, with 23 additional metrics in the complementary row. Each metric includes detailed tooltips accessible by hovering over the value.
Main Row — Performance Metrics (Columns 0-6)
Net Profit — (Final Equity - Initial Capital) / Initial Capital × 100
— >20%: Excellent, >0%: Profitable, <0%: Loss
— Total return percentage over entire backtest period
Payoff Ratio — Average Win / Average Loss
— >1.5: Excellent, >1.0: Good, <1.0: Losses exceed wins
— Average winning trade size relative to average losing trade. Breakeven win rate = 100% / (1 + Payoff)
Sample Size — Count of closed trades
— >=30: Statistically valid, <30: Insufficient data
— Number of completed trades. Includes 95% confidence interval for win rate in tooltip
Profit Factor — Gross Profit / Gross Loss
— >=1.5: Excellent, >1.0: Profitable, <1.0: Losing
— Ratio of total winnings to total losses. Uses absolute values unlike payoff ratio
CAGR — (Final / Initial)^(365.25 / Days) - 1
— >=10%: Excellent, >0%: Positive growth
— Compound Annual Growth Rate - annualized return accounting for compounding
Expectancy — Sum of all returns / Trade count
— >0.20%: Excellent, >0%: Positive edge
— Average return per trade as percentage. Positive expectancy indicates profitable edge
Monthly Return — Net Profit / (Months in test)
— >0%: Profitable month average
— Average monthly return. Geometric monthly also shown in tooltip
Main Row — Trade Statistics (Columns 7-14)
Avg Duration — Average time in position per trade
— Mean holding period from entry to exit. Influenced by timeframe and trading style
Max CW — Longest consecutive winning streak
— Maximum consecutive wins. Expected value = ln(trades) / ln(1/winRate)
Max CL — Longest consecutive losing streak
— Maximum consecutive losses. Important for psychological risk tolerance
Win Rate — Wins / Total Trades
— Higher is better
— Percentage of profitable trades. Breakeven win rate shown in tooltip
BE Rate — Breakeven Trades / Total Trades
— Lower is better
— Percentage of trades that broke even (neither profit nor loss)
Loss Rate — Losses / Total Trades
— Lower is better
— Percentage of unprofitable trades. Together with win rate and BE rate, sums to 100%
Frequency — Trades per month
— Trading activity level. Displays intelligently (e.g., "12/mo", "1.5/wk", "3/day")
Exposure — Time in market / Total time × 100
— Lower = less risk
— Percentage of time the strategy had open positions
Main Row — Risk Metrics (Columns 15-22)
Sharpe Ratio — (Return - Rf) / StdDev × sqrt(Periods)
— >=3: Excellent, >=2: Good, >=1: Fair, <1: Poor
— Measures risk-adjusted return using total volatility. Annualized using sqrt(252) for daily
Sortino Ratio — (Return - Rf) / DownsideDev × sqrt(Periods)
— >=2: Excellent, >=1: Good, <1: Needs improvement
— Similar to Sharpe but only penalizes downside volatility. Can be higher than Sharpe
Max DD — (Peak - Trough) / Peak × 100
— <5%: Excellent, 5-15%: Moderate, 15-30%: High, >30%: Severe
— Largest peak-to-trough decline in equity. Critical for risk tolerance and position sizing
RoR — Risk of Ruin probability
— <1%: Excellent, 1-5%: Acceptable, 5-10%: Elevated, >10%: Dangerous
— Probability of losing entire trading account based on win rate and payoff ratio
R² — R-squared of equity curve vs. time
— >=0.95: Excellent, 0.90-0.95: Good, 0.80-0.90: Moderate, <0.80: Erratic
— Coefficient of determination measuring linearity of equity growth
MAR — CAGR / |Max Drawdown|
— Higher is better, negative = bad
— Calmar Ratio. Reward relative to worst-case loss. Negative if max DD exceeds CAGR
CVaR — Average of returns below VaR threshold
— Lower absolute is better
— Conditional Value at Risk (Expected Shortfall). Average loss in worst 5% of outcomes
p-value — Binomial test probability
— <0.05: Significant, 0.05-0.10: Marginal, >0.10: Likely random
— Probability that observed results are due to chance. Low p-value means statistically significant edge
Complementary Row — Extended Metrics
Compounding — (Compounded Return / Total Return) × 100
— Percentage of total profit attributable to compounding (position sizing)
Avg Win — Sum of wins / Win count
— Average profitable trade return in percentage
Avg Trade — Sum of all returns / Total trades
— Same as Expectancy (Column 5). Displayed here for convenience
Avg Loss — Sum of losses / Loss count
— Average unprofitable trade return in percentage (negative value)
Martin Ratio — CAGR / Ulcer Index
— Similar to Calmar but uses Ulcer Index instead of Max DD
Rolling Expectancy — Mean of rolling window expectancies
— Average expectancy calculated across rolling windows. Shows consistency of edge
Avg W Dur — Avg duration of winning trades
— Average time from entry to exit for winning trades only
Max Eq — Highest equity value reached
— Peak equity achieved during backtest
Min Eq — Lowest equity value reached
— Trough equity point. Important for understanding worst-case absolute loss
Buy & Hold — (Close_last / Close_first - 1) × 100
— >0%: Passive profit
— Return of simply buying and holding the asset from backtest start to end
Alpha — Strategy CAGR - Benchmark CAGR
— >0: Has skill (beats benchmark)
— Excess return above passive benchmark. Positive alpha indicates genuine value-added skill
Beta — Covariance(Strategy, Benchmark) / Variance(Benchmark)
— <1: Less volatile than market, >1: More volatile
— Systematic risk correlation with benchmark
Avg L Dur — Avg duration of losing trades
— Average time from entry to exit for losing trades only
Rolling Sharpe/Sortino — Dynamic based on win rate
— >2: Good consistency
— Rolling metric across sliding windows. Shows Sharpe if win rate >50%, Sortino if <=50%
Curr DD — Current drawdown from peak
— Lower is better
— Present drawdown percentage. Zero means at new equity high
DAR — CAGR adjusted for target DD
— Higher is better
— Drawdown-Adjusted Return. DAR^5 = CAGR if max DD = 5%
Kurtosis — Fourth moment / StdDev^4 - 3
— ~0: Normal, >0: Fat tails, <0: Thin tails
— Measures "tailedness" of return distribution (excess kurtosis)
Skewness — Third moment / StdDev^3
— >0: Positive skew (big wins), <0: Negative skew (big losses)
— Return distribution asymmetry
VaR — 5th percentile of returns
— Lower absolute is better
— Value at Risk at 95% confidence. Maximum expected loss in worst 5% of outcomes
Ulcer — sqrt(mean(drawdown^2))
— Lower is better
— Ulcer Index - root mean square of drawdowns. Penalizes both depth AND duration
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ MONTE CARLO SIMULATION
Purpose
Monte Carlo simulation tests strategy robustness by randomizing the order of trades while keeping trade returns unchanged. This simulates alternative equity curves to assess outcome variability.
Method
Extract all historical trade returns
Randomly shuffle the sequence (1000+ iterations)
Calculate cumulative equity for each shuffle
Build distribution of final outcomes
Output
The stress test table shows:
Median Outcome: 50th percentile result
5th Percentile: Worst 5% of outcomes
95th Percentile: Best 95% of outcomes
Success Rate: Percentage of simulations that were profitable
Interpretation
If 95% of simulations are profitable: Strategy is robust
If median is far from actual result: High variance/unreliability
If 5th percentile shows large loss: High tail risk
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ WALK-FORWARD ANALYSIS
Purpose
Walk-Forward Analysis (WFA) is the gold standard for detecting strategy overfitting. It simulates real-world trading by dividing historical data into rolling "training" (in-sample) and "validation" (out-of-sample) periods. A strategy that performs well on unseen data is more likely to succeed in live trading.
Method
The implementation uses a non-overlapping window approach following AmiBroker's gold standard methodology:
Segment Calculation: Total trades divided into N windows (default: 12), IS = ~75%, OOS = ~25%, Step = OOS length
Window Structure: Each window has IS (training) followed by OOS (validation). Each OOS becomes the next window's IS (rolling forward)
Metrics Calculated: CAGR, Sharpe, Sortino, MaxDD, Win Rate, Expectancy, Profit Factor, Payoff
Aggregation: IS metrics averaged across all IS periods, OOS metrics averaged across all OOS periods
Output
IS CAGR: In-sample annualized return
OOS CAGR: Out-of-sample annualized return ( THE key metric )
IS/OOS Sharpe: In/out-of-sample risk-adjusted return
Success Rate: % of OOS windows that were profitable
Interpretation
Robust: IS/OOS CAGR gap <20%, OOS Success Rate >80%
Some Overfitting: CAGR gap 20-50%, Success Rate 50-80%
Severe Overfitting: CAGR gap >50%, Success Rate <50%
Key Principles:
OOS is what matters — Only OOS predicts live performance
Consistency > Magnitude — 10% IS / 9% OOS beats 30% IS / 5% OOS
Window count — More windows = more reliable validation
Non-overlapping OOS — Prevents data leakage
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ TABLE DISPLAY
Main Table — Organized into three sections:
Performance Metrics (Cols 0-6): Net Profit, Payoff, Sample Size, Profit Factor, CAGR, Expectancy, Monthly
Trade Statistics (Cols 7-14): Avg Duration, Max CW, Max CL, Win, BE, Loss, Frequency, Exposure
Risk Metrics (Cols 15-22): Sharpe, Sortino, Max DD, RoR, R², MAR, CVaR, p-value
Color Coding
🟢 Green: Excellent performance
🟠 Orange: Acceptable performance
⚪ Gray: Neutral / Fair
🔴 Red: Poor performance
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ IMPLEMENTATION NOTES
Data Source: All metrics calculated from strategy.closedtrades , ensuring compatibility with any Pine Script strategy
Calculation Timing: All calculations occur on barstate.islastconfirmedhistory to optimize performance
Limitations: Requires at least 1 closed trade for basic metrics, 30+ trades for reliable statistical analysis
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ QUICK NOTES
➙ This library has been developed and refined over two years of real-world strategy testing. Every calculation has been validated against industry-standard quantitative finance references.
➙ The entire codebase is thoroughly documented inline. If you are curious about how a metric is calculated or want to understand the implementation details, dive into the source code -- it is written to be read and learned from.
➙ This description focuses on usage and concepts rather than exhaustively listing every exported type and function. The library source code is thoroughly documented inline -- explore it to understand implementation details and internal logic.
➙ All calculations execute on barstate.islastconfirmedhistory to minimize runtime overhead. The library is designed for efficiency without sacrificing accuracy.
➙ Beyond analysis, this library serves as a learning resource. Study the source code to understand quantitative finance concepts, Pine Script advanced techniques, and proper statistical methodology.
➙ Metrics are their own not binary good/bad indicators. A high Sharpe ratio with low sample size is misleading. A deep drawdown during a market crash may be acceptable. Study each function and metric individually -- evaluate your strategy contextually, not by threshold alone.
➙ All strategies face alpha decay over time. Instead of over-optimizing a single strategy on one timeframe and market, build a diversified portfolio across multiple markets and timeframes. Deeptest helps you validate each component so you can combine robust strategies into a trading portfolio.
➙ Screenshots shown in the documentation are solely for visual representation to demonstrate how the tables and metrics will be displayed. Please do not compare your strategy's performance with the metrics shown in these screenshots -- they are illustrative examples only, not performance targets or benchmarks.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ HOW-TO
Using Deeptest is intentionally straightforward. Just import the library and call DT.runDeeptest() at the end of your strategy code in main scope. .
//@version=6
strategy("My Strategy", overlay=true)
// Import the library
import Fractalyst/Deeptest/1 as DT
// Your strategy logic
fastMA = ta.sma(close, 10)
slowMA = ta.sma(close, 30)
if ta.crossover(fastMA, slowMA)
strategy.entry("Long", strategy.long)
if ta.crossunder(fastMA, slowMA)
strategy.close("Long")
// Run the analysis
DT.runDeeptest()
And yes... it's compatible with any TradingView Strategy! 🪄
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ CREDITS
Author: @Fractalyst
Font Library: by @fikira - @kaigouthro - @Duyck
Community: Inspired by the @PineCoders community initiative, encouraging developers to contribute open-source libraries and continuously enhance the Pine Script ecosystem for all traders.
if you find Deeptest valuable in your trading journey, feel free to use it in your strategies and give a shoutout to @Fractalyst -- Your recognition directly supports ongoing development and open-source contributions to Pine Script.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
█ DISCLAIMER
This library is provided for educational and research purposes. Past performance does not guarantee future results. Always test thoroughly and use proper risk management. The author is not responsible for any trading losses incurred through the use of this code.

Arbitrage Detector [LuxAlgo]The Arbitrage Detector unveils hidden spreads in the crypto and forex markets. It compares the same asset on the main crypto exchanges and forex brokers and displays both prices and volumes on a dashboard, as well as the maximum spread detected on a histogram divided by four user-selected percentiles. This allows traders to detect unusual, high, typical, or low spreads.
This highly customizable tool features automatic source selection (crypto or forex) based on the asset in the chart, as well as current and historical spread detection. It also features a dashboard with sortable columns and a historical histogram with percentiles and different smoothing options.
🔶 USAGE
Arbitrage is the practice of taking advantage of price differences for the same asset across different markets. Arbitrage traders look for these discrepancies to profit from buying where it’s cheaper and selling where it’s more expensive to capture the spread.
For begginers this tool is an easy way to understand how prices can vary between markets, helping you avoid trading at a disadvantage.
For advanced traders it is a fast tool to spot arbitrage opportunities or inefficiencies that can be exploited for profit.
Arbitrage opportunities are often short‑lived, but they can be highly profitable. By showing you where spreads exist, this tool helps traders:
Understand market inefficiencies
Avoid trading at unfavorable prices
Identify potential profit opportunities across exchanges
As we can see in the image, the tool consists of two main graphics: a dashboard on the main chart and a histogram in the pane below.
Both are useful for understanding the behavior of the same asset on different crypto exchanges or forex brokers.
The tool's main goal is to detect and categorize spread activity across the major crypto and forex sources. The comparison uses data from up to 19 crypto exchanges and 13 forex brokers.
🔹 Forex or Crypto
The tool selects the appropriate sources (crypto exchanges or forex brokers) based on the asset in the chart. Traders can choose which one to use.
The image shows the prices and volumes for Bitcoin and the euro across the main sources, sorted by descending average price over the last 20 days.
🔹 Dashboard
The dashboard displays a list of all sources with four main columns: last price, average price, volume, and total volume.
All four columns can be sorted in ascending or descending order, or left unsorted. A background gradient color is displayed for the sorted column.
Price and volume delta information between the chart asset and each exchange can be enabled or disabled from the settings panel.
🔹 Histogram
The histogram is excellent for visualizing historical values and comparing them with the asset price.
In this case, we have the Euro/U.S. Dollar daily chart. As we can see, the unusual spread activity detected since 2016, with values at or above 98%, is usually a good indication of increased trader activity, which may result in a key price area where the market could turn around.
By default, the histogram has the gradient and smoothing auto features enabled.
The differences are visible in the chart above. On top is an adaptive moving average with higher values for unusual activity. At the bottom is an exponential moving average with a length of 9.
The differences between the gradient and solid colors are evident. In the first case, the colors are in sync with the data values, becoming more yellow with higher values and more green with lower values. In the second case, the colors are solid and only distinguish data above or below the defined percentiles.
🔶 SETTINGS
Sources: Choose between crypto exchanges, forex brokers, or automatic selection based on the asset in the chart.
Average Length: Select the length for the price and volume averages.
🔹 Percentiles
Percentile Length: Select the length for the percentile calculation, or enable the use of the full dataset. Enabling this option may result in runtime errors due to exceeding the allotted resources.
Unusual % >: Select the unusual percentile.
High % >: Select the high percentile.
Typical % >: Select the typical percentile.
🔹 Dashboard
Dashboard: Enable or disable the dashboard.
Sorting: Select the sorting column and direction.
Position: Select the dashboard location.
Size: Select the dashboard size.
Price Delta: Show the price difference between each exchange and the asset on the chart.
Volume Delta: Show the volume difference between each exchange and the asset on the chart.
🔹 Style
Unusual: Enable the plot of the unusual percentile and select its color.
High: Enable the plot of the high percentile and select its color.
Typical: Enable the plot of the typical percentile and select its color.
Low: Select the color for the low percentile.
Percentiles Auto Color: Enable auto color for all plotted percentiles.
Histogram Gradient: Enable the gradient color for the histogram.
Histogram Smoothing: Select the length of the EMA smoothing for the histogram or enable the Auto feature. The Auto feature uses an adaptive moving average with the data percent rank as the efficiency ratio.

Multi-Distribution Volume Profile (Zeiierman)█ Overview
Multi-Distribution Volume Profile (Zeiierman) is a flexible, structure-first volume profile tool that lets you reshape how volume is distributed across price, from classic uniform profiles to advanced statistical curves like Gaussian, Lognormal, Student-t, and more.
Instead of forcing every market into a single "one-size-fits-all" profile, this tool lets you model how volume is likely concentrated inside each bar (body vs wicks, midpoint, tails, center bias, right-skew, heavy tails, etc.) and then stacks that behavior across a whole lookback window to build a rich, multi-distribution map of traded activity.
On top of that, it overlays a dynamic Center Band (value area) and a fade/gradient model that can color each price row by volume, hits, recency, volatility, reversals, or even liquidity voids, turning a plain profile into a multi-dimensional context map.
Highlights
Choose from multiple Profile Build Modes , including uniform, body-only, wick-only, midpoint/close/open, center-weighted, and a suite of probability-style distributions (Gaussian, Lognormal, Weibull, Student-t, etc.)
Flexible anchor layout: draw the profile on Right/Left (horizontal) or Bottom/Top (vertical) to fit any chart layout
Value Area / Center Band computed from volume quantiles around the POC.
Gradient-based Fade Metrics: volume, price hits, freshness (time decay), volatility impact, dwell time, reversal density, compression, and liquidity voids
Separate bullish vs bearish volume at each price row for directional structure insights
█ How It Works
⚪ Profile Construction
The script scans a user-defined Bars Included window and finds the full high–low span of that zone. It then divides this range into a user-controlled number of Price Levels (rows).
For each historical bar within the window:
It measures the candle’s price range, body, and wicks.
It assigns volume to rows according to the selected Profile Build Mode, for example:
* Range Uniform – volume spread evenly across the full high–low range.
* Range Body Only / Range Wick Only – concentrate volume inside the body or wicks only.
* Midpoint / Close / Open Only – allocate volume entirely into one price row (pinpoint modeling).
HL2 / Body Center Weighted – center weights around the middle of the range/body.
Recent-Weighted Volume – amplify newer bars using exponential time decay.
Volume Squared (Hard) – aggressively boost bars with large volume.
Up Bars Only / Down Bars Only – filter volume to only bullish or bearish bars.
For more advanced shapes, the script uses continuous distributions across the bar’s span:
Linear, Triangular, Exponential to High
Cosine Centered, PERT
Gaussian, Lognormal, Cauchy, Laplace
Pareto, Weibull, Logistic, Gumbel
Gamma, Beta, Chi-Square, Student-t, F-Shape
Each distribution produces a weight for each row within the bar’s range, normalized so the total volume remains consistent, but the shape of where that volume lands changes.
⚪ POC & Center Band (Value Area)
Once all rows are accumulated:
The row with the highest total volume becomes the Point of Control (POC)
The script computes cumulative volume and finds the band that wraps a user-defined Center of Profile % (e.g., 68%) around the center of distribution.
This range is displayed as a central band, often treated like a value area where price has spent the most “effort” trading.
⚪ Gradient Fade Engine
Each row also gets a fade metric, chosen in Fade Metric:
Volume – opacity based on relative volume.
Price Hits – how frequently that row was touched.
Blended (Vol+Hits) – average of volume & hits.
Freshness – emphasizes recent activity, controlled by Decay.
Volatility Impact – rows that saw larger ranges contribute more.
Dwell Time – where price “camped” the longest.
Reversal Density – where direction changes cluster.
Compression – tight-range compression zones.
Liquidity Void – inverse of volume (thin liquidity zones).
When Apply Gradient is enabled, the row’s bullish/bearish colors are tinted from faint to strong based on this chosen metric, effectively turning the profile into a heatmap of your chosen structural property.
█ How to Use
⚪ Explore Different Distribution Assumptions
Switch between multiple Profile Build Modes to see how your assumptions about intrabar volume affect structure:
Use Range Uniform for classical profile reading.
Deploy Gaussian, Logistic, or Cosine shapes to emphasize central clustering.
Try Pareto, Lognormal, or F-Shape to focus on tail / extremal activity.
Use Recent-Weighted Volume to prioritize the most recent structural behavior.
This is especially useful for traders who want to test how different modeling assumptions change perceived value areas and levels of interest.
⚪ Identify Value, Acceptance & Rejection Zones
Use the POC and Center of Profile (%) band to distinguish:
High-acceptance zones – wide central band, thick rows, strong gradient → fair value areas
Rejection zones & tails – thin extremes, low dwell time, high volatility or reversal density
These regions can be used as:
Targets and origin zones for mean reversion
Context for breakout validation (leaving value)
Bias reference for intraday rotations or swing rotations
⚪ Read Directional Structure Within the Profile
Because each row is split into bullish vs bearish contributions, you can visually read:
Where buyers dominated a price region (large bullish slice)
Where sellers absorbed or defended (large bearish slice)
Combining this with Fade Metrics like Reversal Density, Dwell Time, or Freshness turns the profile into a structural order-flow map, without needing raw tick-by-tick volume data.
⚪ Use Fade Metrics for Contextual Heatmaps
Each Fade Metric can be used for a different analytical lens:
Volume / Blended – emphasize where volume and activity are concentrated.
Freshness – highlight the most recently active zones that still matter.
Volatility Impact & Compression – spot areas of explosive moves vs coiled ranges.
Reversal Density – locate micro turning points and battle zones.
Liquidity Void – visually pop out thin regions that may act as speedways or magnets.
█ Settings
Profile Build Mode – Selects how each bar’s volume is distributed across its price range (uniform, body/wick, midpoint/close/open, center-weighted, or statistical distribution families).
Bars Included – Number of bars used to build the profile from the current bar backward.
Price Levels – Vertical resolution of the profile: more levels = smoother but heavier.
Anchor Side – Where the profile is drawn on the chart: Right, Left, Bottom, or Top.
Offset (bars) – Horizontal offset from the last bar to the profile when using Right/Left modes.
Apply Gradient – Toggles the fade/heatmap coloring based on the selected metric.
Fade Metric – Chooses the property driving row opacity (Volume, Hits, Freshness, Volatility Impact, Dwell Time, Reversal Density, Compression, Liquidity Void).
Decay – Time-decay factor for Freshness (values close to 1 keep older activity relevant for longer).
Profile Thickness – Relative thickness of the profile along the time axis, as a % of the lookback window.
Center of Profile (%) – Volume percentage used to define the central band (value area) around the POC.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

Multi-Ticker Anchored CandlesMulti-Ticker Anchored Candles (MTAC) is a simple tool for overlaying up to 3 tickers onto the same chart. This is achieved by interpreting each symbol's OHLC data as percentages, then plotting their candle points relative to the main chart's open. This allows for a simple comparison of tickers to track performance or locate relationships between them.
> Background
The concept of multi-ticker analysis is not new, this type of analysis can be extremely helpful to get a gauge of the over all market, and it's sentiment. By analyzing more than one ticker at a time, relationships can often be observed between tickers as time progresses.
While seeing multiple charts on top of each other sounds like a good idea...each ticker has its own price scale, with some being only cents while others are thousands of dollars.
Directly overlaying these charts is not possible without modification to their sources.
By using a fixed point in time (Period Open) and percentage performance relative to that point for each ticker, we are able to directly overlay symbols regardless of their price scale differences.
The entire process used to make this indicator can be summed up into 2 keywords, "Scaling & Anchoring".
> Scaling
First, we start by determining a frame of reference for our analysis. The indicator uses timeframe inputs to determine sessions which are used, by default this is set to 1 day.
With this in place, we then determine our point of reference for scaling. While this could be any point in time, the most sensible for our application is the daily (or session) open.
Each symbol shares time, therefore, we can take a price point from a specified time (Opening Price) and use it to sync our analysis over each period.
Over the day, we track the percentage performance of each ticker's OHLC values relative to its daily open (% change from open).
Since each ticker's data is now tracked based on its opening price, all data is now using the same scale.
The scale is simply "% change from open".
> Anchoring
Now that we have our scaled data, we need to put it onto the chart.
Since each point of data is relative to it's daily open (anchor point), relatively speaking, all daily opens are now equal to each other.
By adding the scaled ticker data to the main chart's daily open, each of our resulting series will be properly scaled to the main chart's data based on percentages.
Congratulations, We have now accurately scaled multiple tickers onto one chart.
> Display
The indicator shows each requested ticker as different colored candlesticks plotted on top of the main chart.
Each ticker has an associated label in front of the current bar, each component of this label can be toggled on or off to allow only the desired information to be displayed.
To retain relevance, at the start of each session, a "Session Break" line is drawn, as well as the opening price for the session. These can also be toggled.
Note: The opening price is the opening price for ALL tickers, when a ticker crosses the open on the main chart, it is crossing its own opening price as well.
> Examples
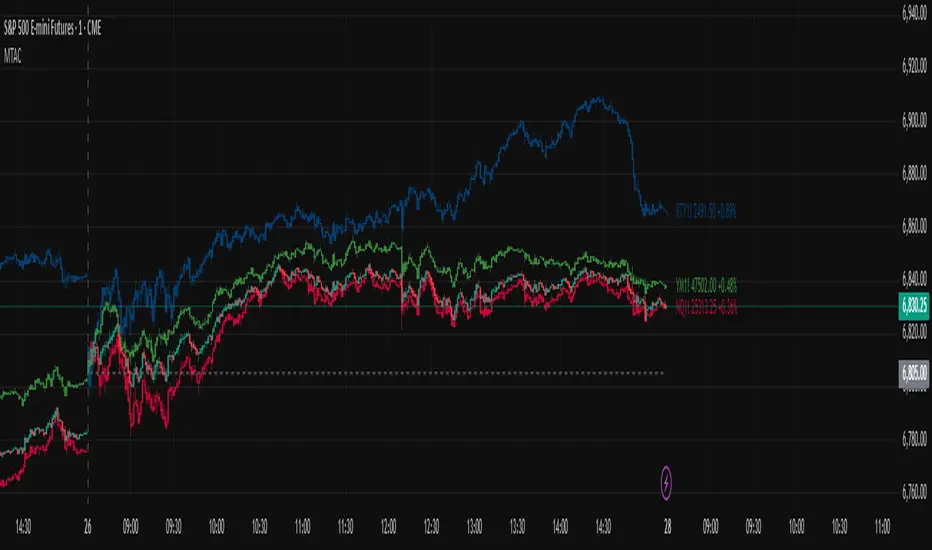
In the chart below, we can see NYSE:MCD NASDAQ:WEN and NASDAQ:JACK overlaid on a NASDAQ:SBUX chart.
From this, we can see NASDAQ:JACK was the top gainer on the day. While this was the case, it also fell roughly 4% from its peak near lunchtime. Unlike the top gainer, we can see the other 3 tickers ended their day near their daily high.
In the explanations above, the daily timeframe is used since it is the default; however, the analysis is not constrained to only days. The anchoring period can be set to any timeframe period.
In the chart below, you can observe the Daily, Weekly, and Monthly anchored charts side-by-side.
This can be used on all tickers, timeframes, and markets. While a typical application may be comparing relevant assets... the script is not limited.
Below we have a chart tracking COMEX:GCV2026 , FX:EURUSD , and COINBASE:DOGEUSD on the AMEX:SPY chart.
While these tickers are not typically compared side-by-side, here it is simply a display of the capabilities of the script.
Enjoy!
Vdubus Divergence Wave Pattern Generator V1The Vdubus Divergence Wave Theory
10 years in the making & now finally thanks to AI I have attempted to put my Trading strategy & logic into a visual representation of how I analyse and project market using Core price action & MacD. Enjoy :)
A Proprietary Structural & Momentum Confluence SystemPart 1: The Strategic Concept1. The Core Philosophy: "Geometry + Physics"Traditional technical analysis often fails because traders confuse location with timing.Geometry (Price Patterns): Tells us WHERE the market is likely to reverse (e.g., at a resistance level or harmonic D-point).Physics (Momentum): Tells us WHEN the energy driving the trend has actually shifted. The Vdubus Theory posits that a trade should never be taken based on Geometry alone. A valid signal requires a specific, fractal decay in momentum—a "Handshake" between price structure and energy exhaustion.2. The 3-Wave Momentum Filter (The Engine)Most traders look for simple divergence (2 points). The Vdubus Theory demands a 3-Wave Structure to confirm the true state of the market.A. The Standard Reversal (Exhaustion)This is the "Safe" entry, catching the slow death of a trend.Wave 1 $\rightarrow$ 2 (The Warning): Price pushes higher, but momentum is lower (Standard Divergence). This signals that the trend is tapping the brakes.Wave 2 $\rightarrow$ 3 (The Confirmation): Price pushes to a final extreme (often a stop-hunt), but momentum is flat or lower than Wave 2 ("No Divergence").The Logic: This confirms that the buyers have expended all remaining energy. The engine is dead.
B. The Climax Reversal (The Trap)This is the "Aggressive" entry, catching V-shape reversals.Wave 1 $\rightarrow$ 2 (The Bait): Price pushes higher, and momentum is Stronger/Higher (No Divergence). This sucks in retail traders who believe the trend is accelerating.Wave 2 $\rightarrow$ 3 (The Snap): Price pushes again, but momentum suddenly collapses (Divergence).The Logic: A "Strong to Weak" shift. The market traps traders with a show of strength before hitting a "concrete wall" of limit orders.C. The Predator (The Trend Continuation)The Logic: Trends rarely move in straight lines. The "Predator" looks for Hidden Divergence during a pullback.The Signal: Price makes a Higher Low (Trend Structure Intact), but Momentum makes a Lower Low (Oversold Trap). This signals the end of the correction and the resumption of the main trend.3. The "Clean Path" PrincipleA trade is only valid if there is no opposing force. If you are looking to Sell (Bearish Reversal), the opposing Bullish momentum must be weak or neutral. If the "Enemy" is strong, the trade is skipped.
Part 2: The Indicator Breakdown
Tool Name: Vdubus Divergence Wave Pattern Generator V1
This script automates your analysis by combining ZigZag Pattern Recognition (Geometry) with your Custom MACD Logic (Physics).
1. The "Golden" Settings
The physics engine is tuned to your specific discovery:
Fast Length: 8
Slow Length: 21
Signal Length: 5
Lookback: 3 (Sensitive enough to catch the exact pivot points).
2. Signal Generation Logic
The indicator scans for four distinct setups. Here is the exact logic code translated into English:
Signal 1: Standard Reversal (Green/Red Pattern)
Geometry: The ZigZag algorithm identifies a 5-point structure (X-A-B-C-D), such as a Gartley, Bat, or Butterfly.
Physics Check:
Finds the last 3 momentum peaks matching the price highs.
Rule: Momentum Peak 2 must be < Peak 1 (Divergence).
Rule: Momentum Peak 3 must be <= Peak 2 (Confirmation/No Div).
Output: Draws the colored pattern and labels it (e.g., "Bearish Gartley (Exhaustion)").
Signal 2: Climax Reversal (Orange Pattern)
Geometry: Identifies the same 5-point structures.
Physics Check:
Rule: Momentum Peak 2 is >= Peak 1 (Strength/No Div).
Rule: Momentum Peak 3 is < Peak 2 (Sudden Failure/Div).
Output: Draws the pattern in Orange labeled "⚠️ CLIMAX REVERSAL". This is your "Trap" detector.
Signal 3: Rounded Top/Bottom (Navy/Maroon Label)
Geometry: Price is compressing or rounding over.
Physics Check:
Scans for 4 consecutive waves of momentum decay.
Rule: Peak 1 > Peak 2 > Peak 3 > Peak 4.
Output: Places a label indicating a "Multi-Wave Decay," identifying turns that don't have sharp pivots.
Signal 4: The Predator (Purple Pattern)
Geometry: Identifies a trend pullback (Higher Low for Buys).
Physics Check:
Rule: Momentum makes a Lower Low while Price makes a Higher Low (Hidden Divergence).
Output: Draws a Purple pattern labeled "🦖 PREDATOR" to signal trend continuation.
3. The Confluence Dashboard
Located in the corner of the screen, this provides a final "Safety Check."
Logic: It compares the absolute value (strength) of the most recent Bearish Momentum Peak vs. the most recent Bullish Momentum Low.
Output:
Green (Bulls Strong): Buying pressure is dominant. Safe to Buy, Dangerous to Sell.
Red (Bears Strong): Selling pressure is dominant. Safe to Sell, Dangerous to Buy.
Grey (Neutral): Forces are balanced.
Summary of Potential
This system solves the "Trader's Dilemma" of entering too early or too late. By waiting for the 3rd Wave, you effectively filter out the market noise and only commit capital when the opposing side has structurally and physically collapsed. It transforms trading from a guessing game into a disciplined execution of identifying Geometric Exhaustion.
Logic 1 / PREVIOUS DIVERGENCE PROJECTS future TREND BREAKS / Reversals *Not in script*
Logic 2 / Wave 1 to 2 = Divergence / Wave 2 to 3 = NO divergence = Signal
Reverse logic: Wave 1 to 2 = NO Divergence / Wave 2 to 3 = Divergence = Signal

Per Bak Self-Organized CriticalityTL;DR: This indicator measures market fragility. It measures the system's vulnerability to cascade failures and phase transitions. I've added four independent stress vectors: tail risk, volatility regime, credit stress, and positioning extremes. This allows us to quantify how susceptible markets are to disproportionate moves from small shocks, similar to how a steep sandpile is primed for avalanches.
Avalanches, forest fires, earthquakes, pandemic outbreaks, and market crashes. What do they all have in common? They are not random.
These events follow power laws - stable systems that naturally evolve toward critical states where small triggers can unleash catastrophic cascades.
For example, if you are building a sandpile, there will be a point with a little bit additional sand will cause a landslide.
Markets build fragility grain by grain, like a sandpile approaching avalanche.
The Per Bak Self-Organized Criticality (SOC) indicator detects when the markets are a few grains away from collapse.
This indicator is highly inspired by the work of Per Bak related to the science of self-organized criticality .
As Bak said:
"The earthquake does not 'know how large it will become'. Thus, any precursor state of a large event is essentially identical to a precursor state of a small event."
For markets, this means:
We cannot predict individual crash size from initial conditions
We can predict statistical distribution of crashes
We can identify periods of increased systemic risk (proximity to critical state)
BTW, this is a forwarding looking indicator and doesn't reprint. :)
The Story of Per Bak
In 1987, Danish physicist Per Bak and his colleagues discovered an important pattern in nature: self-organized criticality.
Their sandpile experiment revealed something: drop grains of sand one by one onto a pile, and the system naturally evolves toward a critical state. Most grains cause nothing. Some trigger small slides. But occasionally a single grain triggers a massive avalanche.
The key insight is that we cannot predict which grain will trigger the avalanche, but you can measure when the pile has reached a critical state.
Why Markets Are the Ultimate SOC System?
Financial markets exhibit all the hallmarks of self-organized criticality:
Interconnected agents (traders, institutions, algorithms) with feedback loops
Non-linear interactions where small events can cascade through the system
Power-law distributions of returns (fat tails, not normal distributions)
Natural evolution toward fragility as leverage builds, correlations tighten, and positioning crowds
Phase transitions where calm markets suddenly shift to crisis regimes
Mathematical Foundation
Power Law Distributions
Traditional finance assumes returns follow a normal distribution. "Markets return 10% on average." But I disagree. Markets follow power laws:
P(x) ∝ x^(-α)
Where P(x) is the probability of an event of size x, and α is the power law exponent (typically 3-4 for financial markets).
What this means: Small moves happen constantly. Medium moves are less frequent. Catastrophic moves are rare but follow predictable probability distributions. The "fat tails" are features of critical systems.
Critical Slowing Down
As systems approach phase transitions, they exhibit critical slowing down—reduced ability to absorb shocks. Mathematically, this appears as:
τ ∝ |T - T_c|^(-ν)
Where τ is the relaxation time, T is the current state, T_c is the critical threshold, and ν is the critical exponent.
Translation: Near criticality, markets take longer to recover from perturbations. Fragility compounds.
Component Aggregation & Non-Linear Emergence
The Per Bak SOC our index aggregates four normalized components (each scaled 0-100) with tunable weights:
SOC = w₁·C_tail + w₂·C_vol + w₃·C_credit + w₄·C_position
Default weights (you can change this):
w₁ = 0.34 (Tail Risk via SKEW)
w₂ = 0.26 (Volatility Regime via VIX term structure)
w₃ = 0.18 (Credit Stress via HYG/LQD + TED spread)
w₄ = 0.22 (Positioning Extremes via Put/Call ratio)
Each component uses percentile ranking over a 252-day lookback combined with absolute thresholds to capture both relative regime shifts and extreme absolute levels.
The Four Pillars Explained
1. Tail Risk (SKEW Index)
Measures options market pricing of fat-tail events. High SKEW indicates elevated outlier probability.
C_tail = 0.7·percentrank(SKEW, 252) + 0.3·((SKEW - 115)/0.5)
2. Volatility Regime (VIX Term Structure)
Combines VIX level with term structure slope. Backwardation signals acute stress.
C_vol = 0.4·VIX_level + 0.35·VIX_slope + 0.25·VIX_ratio
3. Credit Stress (HYG/LQD + TED Spread)
Tracks high-yield deterioration versus investment-grade and interbank lending stress.
C_credit = 0.65·percentrank(LQD/HYG, 252) + 0.35·(TED/0.75)·100
4. Positioning Extremes (Put/Call Ratio)
Detects extreme hedging demand through percentile ranking and z-score analysis.
C_position = 0.6·percentrank(P/C, 252) + 0.4·zscore_normalized
What the Indicator Really Measures?
Not Volatility but Fragility
Markets Going Down ≠ Fragility Building (actually when markets go down, risk and fragility are released)
The 0-100 Scale & Regime Thresholds
The indicator outputs a 0-100 fragility score with four regimes:
🟢 Safe (0-39): System resilient, can absorb normal shocks
🟡 Building (40-54): Early fragility signs, watch for deterioration
🟠 Elevated (55-69): System vulnerable
🔴 Critical (70-100): Highly susceptible to cascade failures
Further Reading for Nerds
Bak, P., Tang, C., & Wiesenfeld, K. (1987). "Self-organized criticality: An explanation of 1/f noise." Physical Review Letters.
Bak, P. & Chen, K. (1991). "Self-organized criticality." Scientific American.
Bak, P. (1996). How Nature Works: The Science of Self-Organized Criticality. Copernicus.
Feedback is appreciated :)

Volatility Risk PremiumTHE INSURANCE PREMIUM OF THE STOCK MARKET
Every day, millions of investors face a fundamental question that has puzzled economists for decades: how much should protection against market crashes cost? The answer lies in a phenomenon called the Volatility Risk Premium, and understanding it may fundamentally change how you interpret market conditions.
Think of the stock market like a neighborhood where homeowners buy insurance against fire. The insurance company charges premiums based on their estimates of fire risk. But here is the interesting part: insurance companies systematically charge more than the actual expected losses. This difference between what people pay and what actually happens is the insurance premium. The same principle operates in financial markets, but instead of fire insurance, investors buy protection against market volatility through options contracts.
The Volatility Risk Premium, or VRP, measures exactly this difference. It represents the gap between what the market expects volatility to be (implied volatility, as reflected in options prices) and what volatility actually turns out to be (realized volatility, calculated from actual price movements). This indicator quantifies that gap and transforms it into actionable intelligence.
THE FOUNDATION
The academic study of volatility risk premiums began gaining serious traction in the early 2000s, though the phenomenon itself had been observed by practitioners for much longer. Three research papers form the backbone of this indicator's methodology.
Peter Carr and Liuren Wu published their seminal work "Variance Risk Premiums" in the Review of Financial Studies in 2009. Their research established that variance risk premiums exist across virtually all asset classes and persist over time. They documented that on average, implied volatility exceeds realized volatility by approximately three to four percentage points annualized. This is not a small number. It means that sellers of volatility insurance have historically collected a substantial premium for bearing this risk.
Tim Bollerslev, George Tauchen, and Hao Zhou extended this research in their 2009 paper "Expected Stock Returns and Variance Risk Premia," also published in the Review of Financial Studies. Their critical contribution was demonstrating that the VRP is a statistically significant predictor of future equity returns. When the VRP is high, meaning investors are paying substantial premiums for protection, future stock returns tend to be positive. When the VRP collapses or turns negative, it often signals that realized volatility has spiked above expectations, typically during market stress periods.
Gurdip Bakshi and Nikunj Kapadia provided additional theoretical grounding in their 2003 paper "Delta-Hedged Gains and the Negative Market Volatility Risk Premium." They demonstrated through careful empirical analysis why volatility sellers are compensated: the risk is not diversifiable and tends to materialize precisely when investors can least afford losses.
HOW THE INDICATOR CALCULATES VOLATILITY
The calculation begins with two separate measurements that must be compared: implied volatility and realized volatility.
For implied volatility, the indicator uses the CBOE Volatility Index, commonly known as the VIX. The VIX represents the market's expectation of 30-day forward volatility on the S&P 500, calculated from a weighted average of out-of-the-money put and call options. It is often called the "fear gauge" because it rises when investors rush to buy protective options.
Realized volatility requires more careful consideration. The indicator offers three distinct calculation methods, each with specific advantages rooted in academic literature.
The Close-to-Close method is the most straightforward approach. It calculates the standard deviation of logarithmic daily returns over a specified lookback period, then annualizes this figure by multiplying by the square root of 252, the approximate number of trading days in a year. This method is intuitive and widely used, but it only captures information from closing prices and ignores intraday price movements.
The Parkinson estimator, developed by Michael Parkinson in 1980, improves efficiency by incorporating high and low prices. The mathematical formula calculates variance as the sum of squared log ratios of daily highs to lows, divided by four times the natural logarithm of two, times the number of observations. This estimator is theoretically about five times more efficient than the close-to-close method because high and low prices contain additional information about the volatility process.
The Garman-Klass estimator, published by Mark Garman and Michael Klass in 1980, goes further by incorporating opening, high, low, and closing prices. The formula combines half the squared log ratio of high to low prices minus a factor involving the log ratio of close to open. This method achieves the minimum variance among estimators using only these four price points, making it particularly valuable for markets where intraday information is meaningful.
THE CORE VRP CALCULATION
Once both volatility measures are obtained, the VRP calculation is straightforward: subtract realized volatility from implied volatility. A positive result means the market is paying a premium for volatility insurance. A negative result means realized volatility has exceeded expectations, typically indicating market stress.
The raw VRP signal receives slight smoothing through an exponential moving average to reduce noise while preserving responsiveness. The default smoothing period of five days balances signal clarity against lag.
INTERPRETING THE REGIMES
The indicator classifies market conditions into five distinct regimes based on VRP levels.
The EXTREME regime occurs when VRP exceeds ten percentage points. This represents an unusual situation where the gap between implied and realized volatility is historically wide. Markets are pricing in significantly more fear than is materializing. Research suggests this often precedes positive equity returns as the premium normalizes.
The HIGH regime, between five and ten percentage points, indicates elevated risk aversion. Investors are paying above-average premiums for protection. This often occurs after market corrections when fear remains elevated but realized volatility has begun subsiding.
The NORMAL regime covers VRP between zero and five percentage points. This represents the long-term average state of markets where implied volatility modestly exceeds realized volatility. The insurance premium is being collected at typical rates.
The LOW regime, between negative two and zero percentage points, suggests either unusual complacency or that realized volatility is catching up to implied volatility. The premium is shrinking, which can precede either calm continuation or increased stress.
The NEGATIVE regime occurs when realized volatility exceeds implied volatility. This is relatively rare and typically indicates active market stress. Options were priced for less volatility than actually occurred, meaning volatility sellers are experiencing losses. Historically, deeply negative VRP readings have often coincided with market bottoms, though timing the reversal remains challenging.
TERM STRUCTURE ANALYSIS
Beyond the basic VRP calculation, sophisticated market participants analyze how volatility behaves across different time horizons. The indicator calculates VRP using both short-term (default ten days) and long-term (default sixty days) realized volatility windows.
Under normal market conditions, short-term realized volatility tends to be lower than long-term realized volatility. This produces what traders call contango in the term structure, analogous to futures markets where later delivery dates trade at premiums. The RV Slope metric quantifies this relationship.
When markets enter stress periods, the term structure often inverts. Short-term realized volatility spikes above long-term realized volatility as markets experience immediate turmoil. This backwardation condition serves as an early warning signal that current volatility is elevated relative to historical norms.
The academic foundation for term structure analysis comes from Scott Mixon's 2007 paper "The Implied Volatility Term Structure" in the Journal of Derivatives, which documented the predictive power of term structure dynamics.
MEAN REVERSION CHARACTERISTICS
One of the most practically useful properties of the VRP is its tendency to mean-revert. Extreme readings, whether high or low, tend to normalize over time. This creates opportunities for systematic trading strategies.
The indicator tracks VRP in statistical terms by calculating its Z-score relative to the trailing one-year distribution. A Z-score above two indicates that current VRP is more than two standard deviations above its mean, a statistically unusual condition. Similarly, a Z-score below negative two indicates VRP is unusually low.
Mean reversion signals trigger when VRP reaches extreme Z-score levels and then shows initial signs of reversal. A buy signal occurs when VRP recovers from oversold conditions (Z-score below negative two and rising), suggesting that the period of elevated realized volatility may be ending. A sell signal occurs when VRP contracts from overbought conditions (Z-score above two and falling), suggesting the fear premium may be excessive and due for normalization.
These signals should not be interpreted as standalone trading recommendations. They indicate probabilistic conditions based on historical patterns. Market context and other factors always matter.
MOMENTUM ANALYSIS
The rate of change in VRP carries its own information content. Rapidly rising VRP suggests fear is building faster than volatility is materializing, often seen in the early stages of corrections before realized volatility catches up. Rapidly falling VRP indicates either calming conditions or rising realized volatility eating into the premium.
The indicator tracks VRP momentum as the difference between current VRP and VRP from a specified number of bars ago. Positive momentum with positive acceleration suggests strengthening risk aversion. Negative momentum with negative acceleration suggests intensifying stress or rapid normalization from elevated levels.
PRACTICAL APPLICATION
For equity investors, the VRP provides context for risk management decisions. High VRP environments historically favor equity exposure because the market is pricing in more pessimism than typically materializes. Low or negative VRP environments suggest either reducing exposure or hedging, as markets may be underpricing risk.
For options traders, understanding VRP is fundamental to strategy selection. Strategies that sell volatility, such as covered calls, cash-secured puts, or iron condors, tend to profit when VRP is elevated and compress toward its mean. Strategies that buy volatility tend to profit when VRP is low and risk materializes.
For systematic traders, VRP provides a regime filter for other strategies. Momentum strategies may benefit from different parameters in high versus low VRP environments. Mean reversion strategies in VRP itself can form the basis of a complete trading system.
LIMITATIONS AND CONSIDERATIONS
No indicator provides perfect foresight, and the VRP is no exception. Several limitations deserve attention.
The VRP measures a relationship between two estimates, each subject to measurement error. The VIX represents expectations that may prove incorrect. Realized volatility calculations depend on the chosen method and lookback period.
Mean reversion tendencies hold over longer time horizons but provide limited guidance for short-term timing. VRP can remain extreme for extended periods, and mean reversion signals can generate losses if the extremity persists or intensifies.
The indicator is calibrated for equity markets, specifically the S&P 500. Application to other asset classes requires recalibration of thresholds and potentially different data sources.
Historical relationships between VRP and subsequent returns, while statistically robust, do not guarantee future performance. Structural changes in markets, options pricing, or investor behavior could alter these dynamics.
STATISTICAL OUTPUTS
The indicator presents comprehensive statistics including current VRP level, implied volatility from VIX, realized volatility from the selected method, current regime classification, number of bars in the current regime, percentile ranking over the lookback period, Z-score relative to recent history, mean VRP over the lookback period, realized volatility term structure slope, VRP momentum, mean reversion signal status, and overall market bias interpretation.
Color coding throughout the indicator provides immediate visual interpretation. Green tones indicate elevated VRP associated with fear and potential opportunity. Red tones indicate compressed or negative VRP associated with complacency or active stress. Neutral tones indicate normal market conditions.
ALERT CONDITIONS
The indicator provides alerts for regime transitions, extreme statistical readings, term structure inversions, mean reversion signals, and momentum shifts. These can be configured through the TradingView alert system for real-time monitoring across multiple timeframes.
REFERENCES
Bakshi, G., and Kapadia, N. (2003). Delta-Hedged Gains and the Negative Market Volatility Risk Premium. Review of Financial Studies, 16(2), 527-566.
Bollerslev, T., Tauchen, G., and Zhou, H. (2009). Expected Stock Returns and Variance Risk Premia. Review of Financial Studies, 22(11), 4463-4492.
Carr, P., and Wu, L. (2009). Variance Risk Premiums. Review of Financial Studies, 22(3), 1311-1341.
Garman, M. B., and Klass, M. J. (1980). On the Estimation of Security Price Volatilities from Historical Data. Journal of Business, 53(1), 67-78.
Mixon, S. (2007). The Implied Volatility Term Structure of Stock Index Options. Journal of Empirical Finance, 14(3), 333-354.
Parkinson, M. (1980). The Extreme Value Method for Estimating the Variance of the Rate of Return. Journal of Business, 53(1), 61-65.

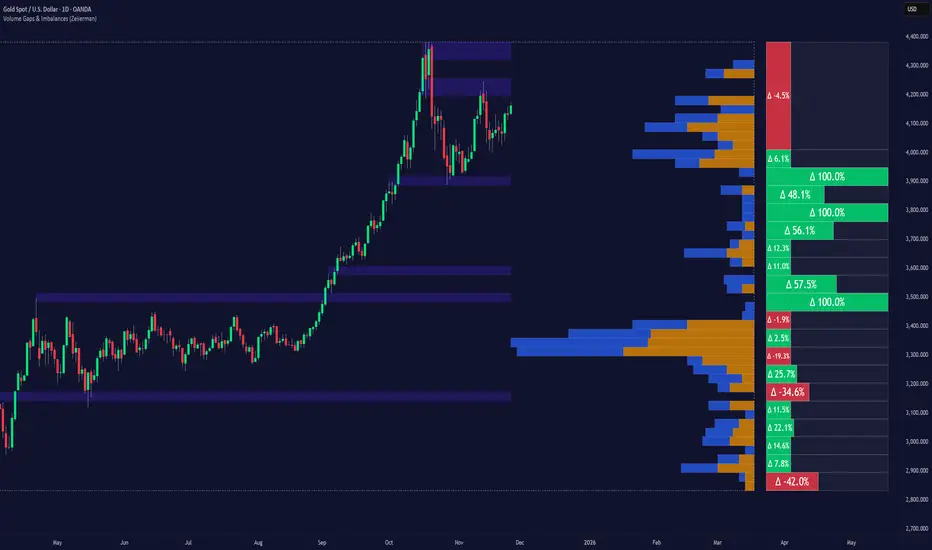
Volume Gaps & Imbalances (Zeiierman)█ Overview
Volume Gaps & Imbalances (Zeiierman) is an advanced market-structure and order-flow visualizer that maps where the market traded, where it did not, and how buyer-vs-seller pressure accumulated across the entire price range.
The core of the indicator is a price-by-price volume profile built from Bullish and Bearish volume assignments. The script highlights:
True zero-volume voids (regions of no traded volume)
Bull/Bear imbalance rows (horizontal volume slices)
A multi-section Delta Panel, showing aggregated Buy–Sell pressure per vertical sector
A clean separation between profile structure, volume efficiency, and delta flows
Together, these components reveal market inefficiencies, displacement zones, and fair-value regions that price tends to revisit — making it an exceptional tool for structural trading, order-flow analysis, and contextual confluence.
Highlights
Identifies true volume voids (untraded price regions), more precisely than standard FVG tools
Plots Bull vs Bear volume at each price row for fine-grained imbalance reading
Includes a sector-based Delta Grid that aggregates Buy–Sell dominance
█ How It Works
⚪ Profile Construction
The indicator scans a user-defined Lookback window and divides the full high–low range into Rows. Each bar's volume is allocated into the correct price bucket:
Bullish volume when close > open
Bearish volume when close <= open
This produces three values per price level:
Bull Volume
Bear Volume
Total Volume & Imbalance Profile
Rows where no volume at all occurred are marked as volume gaps — signaling true untraded zones, often produced by impulsive imbalanced moves.
⚪ Zero-Volume Gaps (True Voids)
Unlike candle-based Fair Value Gaps (FVGs), volume gaps identify the deeper, structural inefficiency: Price moved so fast through a region that no trades occurred at those prices. These areas often attract revisits because liquidity never exchanged hands there.
⚪ Bull/Bear Volume Imbalance
Every price row is drawn using two colored horizontal segments:
Bull segment proportional to bullish volume
Bear segment proportional to bearish volume
This reveals where buyers or sellers dominated individual price levels.
⚪ Delta Panel
The full volume profile is cut into Summary Sections. For each block, the script computes: Δ = (Bull Volume − Bear Volume) ÷ Total Volume × 100%
█ How to Use
⚪ Spot True Voids & Inefficiencies
Zero-volume zones highlight where the price moved without trading. These areas often behave like:
Refill zones during retracements
Targets during displacement
Thin regions price slices through quickly
Ideal for both SMC-style trading and structural mapping.
⚪ Identify Bull/Bear Control at Each Price Level
Broad bullish segments show zones of buyer absorption, while wide bearish slices reveal seller control.
This helps you interpret:
Where buyers supported the price
Where sellers defended a level
Which price levels matter for continuation or reversal
⚪ Use Delta Sectors for Contextual Direction
The delta panel shows where market pressure is accumulating, revealing whether the profile is dominated by:
Bullish flow (positive delta)
Bearish flow (negative delta)
Neutral flow (balanced or minimal delta)
█ Settings
Lookback – Number of bars scanned to build the profile.
Rows – Vertical resolution of price bins.
Source – Price source used to assign volume into rows.
Summary Sections – Number of vertical delta sectors.
Summary Width – Horizontal size of the delta bar panel.
Gap From Profile – Distance between profile and delta grid.
Show Delta Text – Toggle Δ% labels.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
Match Finder [theUltimator5]Match Finder is the dating app of indicators. It takes your current ticker and finds the most compatible match over a recent time period. The match may not be Mr. right, but it is Mr. right now. It doesn't forecast future connection, but it tells you current compatibility for today.
Jokes aside, it is a pattern–comparison tool that was designed to find the ticker that tracks most closely to the one you are currently looking at. It scans a user-defined list of 40 tickers (pre-set to a bunch of liquid ETFs) and finds which one most closely matches the recent price action of the current chart over a fixed lookback window.
LOGIC BEHIND THE SCENES
For each bar, the script:
Takes the last N bars (Correlation Window Length) of the current symbol.
Takes the last N bars of each selected comparison ticker.
Calculates the Pearson correlation between the current symbol and each comparison ticker.
Identifies the single best-matching ticker (highest positive correlation, excluding the current symbol itself).
Rescales and overlays that matched segment on the chart so you can visually compare shapes.
Optionally shows a correlation table with all tickers and their correlation values.
The use case of this indicator is to help you see which symbol has recently moved most similarly to your current chart, and how that shape looks when overlaid in the same panel. It helps you see which sectors it may be following most closely to.
Here is an image with arrows showing the elements of this indicator that will be mostly explained later.
USER INPUTS
1. Correlation Window Length
Default: 30
Range: 10–500
This is the number of bars used to compare the current symbol against each ticker.
Important - Larger values produce more “global” shape comparison but increase computational load and may cause the indicator to timeout if the length is too long
2. Drawing Mode
Options:
Scale Only - Adjusts min and max of the plotted line segment to match the chart over the range
Scale & Rotate - Scales as above, but matches the first and last point to the close of the chart over the range. This effectively rotates the pattern to force it to track the chart to an extent.
3. Show Correlation Table
When enabled (disabled by default), shows a table in the bottom-right of the chart that displays the correlation values over the lookback range for all 40 tickers. The best fit ticker is highlighted.
4. Best Fit Line Color
Color used to draw the overlaid best-match segment (yellow by default).
5. Ticker inputs (1–40)
Default set to a broad universe of major ETFs (e.g., SPY, QQQ, IWM, sector and bond ETFs, commodities, etc.).
You can replace these with any symbols supported by your data feed (stocks, ETFs, indexes, etc.).
The script always excludes the current chart’s symbol from being considered as its own best match.
NOTE: THIS INDICATOR IS EXTREMELY MEMORY INTENSIVE AND MAY TAKE SEVERAL SECONDS TO LOAD. PLEASE BE PATIENT AND GIVE THE INDICATOR UP TO 20 SECONDS FOR THE DATA TO DISPLAY

Trend Line Methods (TLM)Trend Line Methods (TLM)
Overview
Trend Line Methods (TLM) is a visual study designed to help traders explore trend structure using two complementary, auto-drawn trend channels. The script focuses on how price interacts with rising or falling boundaries over time. It does not generate trade signals or manage risk; its purpose is to support discretionary chart analysis.
Method 1 – Pivot Span Trendline
The Pivot Span Trendline method builds a dynamic channel from major swing points detected by pivot highs and pivot lows.
• The script tracks a configurable number of recent pivot highs and lows.
• From the oldest and most recent stored pivot highs, it draws an upper trend line.
• From the oldest and most recent stored pivot lows, it draws a lower trend line.
• An optional filled area can be drawn between the two lines to highlight the active trend span.
As new pivots form, the lines are recalculated so that the channel evolves with market structure. This method is useful for visualising how price respects a trend corridor defined directly by swing points.
Method 2 – 5-Point Straight Channel
The 5-Point Straight Channel method approximates a straight trend channel using five key points extracted from a fixed lookback window.
Within the selected window:
• The window is divided into five segments of similar length.
• In each segment, the highest high is used as a representative high point.
• In each segment, the lowest low is used as a representative low point.
• A straight regression-style line is fitted through the five high points to form the upper boundary.
• A second straight line is fitted through the five low points to form the lower boundary.
The result is a pair of straight lines that describe the overall directional channel of price over the chosen window. Compared to Method 1, this approach is less focused on the very latest swings and more on the broader slope of the market.
Inputs & Menus
Pivot Span Trendline group (Method 1)
• Enable Pivot Span Trendline – Turns Method 1 on or off.
• High trend line color / Low trend line color – Colors of the upper and lower trend lines.
• Fill color between trend lines – Base color used to shade the area between the two lines. Transparency is controlled internally.
• Trend line thickness – Line width for both high and low trend lines.
• Trend line style – Line style (solid, dashed, or dotted).
• Pivot Left / Pivot Right – Number of bars to the left and right used to confirm pivot highs and lows. Larger values produce fewer but more significant swing points.
• Pivot Count – How many historical pivot points are kept for constructing the trend lines.
• Lookback Length – Number of bars used to keep pivots in range and to extend the trend lines across the chart.
5-Point Straight Channel group (Method 2)
• Enable 5-Point Straight Channel – Turns Method 2 on or off.
• High channel line color / Low channel line color – Colors of the upper and lower channel lines.
• Channel line thickness – Line width for both channel lines.
• Channel line style – Line style (solid, dashed, or dotted).
• Channel Length (bars) – Lookback window used to divide price into five segments and build the straight high/low channel.
Using Both Methods Together
Both methods are designed to visualise the same underlying idea: price tends to move inside rising or falling channels. Method 1 emphasises the most recent swing structure via pivot points, while Method 2 summarises the broader channel over a fixed window.
When the Pivot Span Trendline corridor and the 5-Point Straight Channel boundaries align or intersect, they can highlight zones where multiple ways of drawing trend lines point to similar support or resistance areas. Traders can use these confluence zones as a visual reference when planning their own entries, exits, or risk levels, according to their personal trading plan.
Notes
• This script is meant as an educational and analytical tool for studying trend lines and channels.
• It does not generate trading signals and does not replace independent analysis or risk management.
• The behaviour of both methods is timeframe- and symbol-agnostic; they will adapt to whichever chart you apply them to.

Breakouts & Pullbacks [Trendoscope®]🎲 Breakouts & Pullbacks - All-Time High Breakout Analyzer
Probability-Based Post-Breakout Behavior Statistics | Real-Time Pullback & Runup Tracker
A professional-grade Pine Script v6 indicator designed specifically for analyzing the historical and real-time behavior of price after strong All-Time High (ATH) breakouts. It automatically detects significant ATH breakouts (with configurable minimum gap), measures the depth and duration of pullbacks, the speed of recovery, and the subsequent run-up strength — then turns all this data into easy-to-read statistical probabilities and percentile ranks.
Perfect for swing traders, breakout traders, and anyone who wants objective, data-driven insight into questions like:
“How deep do pullbacks usually get after a strong ATH breakout?”
“How many bars does it typically take to recover the breakout level?”
“What is the median run-up after recovery?”
“Where is the current pullback or run-up relative to historical ones?”
🎲 Core Concept & Methodology
Indicator is more suitable for indices or index ETFs that generally trade in all-time highs however subjected to regular pullbacks, recovery and runups.
For every qualified ATH breakout, the script identifies 4 distinct phases:
Breakout Point – The exact bar where price closes above the previous ATH after at least Minimum Gap bars.
Pullback Phase – From breakout candle high → lowest low before price recovers back above the breakout level.
Recovery Phase – From the pullback low → the bar where price first trades back above the original breakout price.
Post-Recovery Run-up Phase – From the recovery point → current price (or highest high achieved so far).
Each completed cycle is stored permanently and used to build a growing statistical database unique to the loaded chart and timeframe.
🎲 Visual Elements
Yellow polyline triangle connecting Previous ATH / Pullback point(start), New ATH Breakout point (end), Recovery point (lowest pullback price), and extends to recent ATH price.
Small green label at the pullback low showing detailed tooltip on hover with all measured values
Clean, color-coded statistics table in the top-right corner (visible only on the last bar)
Powerful Statistics Table – The Heart of the Indicator
The table constantly compares the current situation against all past qualified breakouts and shows details about pullbacks, and runups that help us calculate the probability of next pullback, recovery or runup.
🎲 Settings & Inputs
Minimum Gap
The minimum number of bars that must pass between breaking a new ATH and the previous one.
Higher values = stricter filter → only the strongest, cleanest breakouts are counted.
Lower values = more data points (useful on lower timeframes or very trending instruments).
Recommendation:
Daily charts: 30–50
4H charts: 40–80
1H charts: 100–200
🎲 How to Use It in Practice
This indicator helps investors to understand when to be bullish, bearish or cautious and anticipate regular pullbacks, recovery of markets using quantitative methods.
The indicator does not generate buy/sell signals. However, helps traders set expectations and anticipate market movements based on past behavior.

Count█ OVERVIEW
A library of functions for counting the number of times (frequency) that elements occur in an array or matrix.
█ USAGE
Import the Count library.
import joebaus/count/1 as c
Create an array or matrix that is a `float`, `int`, `string`, or `bool` type to count elements from, then call the count function on the array or matrix.
id = array.from(1.00, 1.50, 1.25, 1.00, 0.75, 1.25, 1.75, 1.25)
countMap = id.count() // Alternatively: countMap = c.count(id)
The "count map" will return a map with keys for each unique element in the array or matrix, and with respective values representing the number of times the unique element was counted. The keys will be the same type as the array or matrix counted. The values will always be an `int` type.
array mapKeys = countMap.keys() // Returns unique keys
array mapValues = countMap.values() // Returns counts
If an array is in ascending or descending order, then the keys of the map will also generate in the same order.
intArray = array.from(2, 2, 2, 3, 4, 4, 4, 4, 4, 6, 6) // Ascending order
map countMap = intArray.count() // Creates a "count map" of all unique elements
array mapKeys = countMap.keys() // Returns // Ascending order
array mapValues = countMap.values() // Returns count
Include a value to get the count of only that value in an array or matrix.
floatMatrix = matrix.new(3, 3, 0.0)
floatMatrix.set(0, 0, 1.0), floatMatrix.set(1, 0, 1.0), floatMatrix.set(2, 0, 1.0)
floatMatrix.set(0, 1, 1.5), floatMatrix.set(1, 1, 2.0), floatMatrix.set(2, 1, 2.5)
floatMatrix.set(0, 2, 1.0), floatMatrix.set(1, 2, 2.5), floatMatrix.set(2, 2, 1.5)
int countFloatMatrix = floatMatrix.count(1.0) // Counts all 1.0 elements, returns 5
// Alternatively: int countFloatMatrix = c.count(floatMatrix, 1.0)
The string method of count() can use strings or regular expressions like "bull*" to count all matching occurrences in a string array.
stringArray = array.from('bullish', 'bull', 'bullish', 'bear', 'bull', 'bearish', 'bearish')
int countString = stringArray.count('bullish') // Returns 2
int countStringRegex = stringArray.count('bull*') // Returns 4
To count multiple values, use an array of values instead of a single value. Returning a count map only of elements in the array.
countArray = array.from(1.0, 2.5)
map countMap = floatMatrix.count(countArray)
array mapKeys = countMap.keys() // Returns keys
array mapValues = countMap.values() // Returns counts
Multiple regex patterns or strings can be counted as well.
stringMatrix = matrix.new(3, 3, '')
stringMatrix.set(0, 0, 'a'), stringMatrix.set(1, 0, 'a'), stringMatrix.set(2, 0, 'a')
stringMatrix.set(0, 1, 'b'), stringMatrix.set(1, 1, 'c'), stringMatrix.set(2, 1, 'd')
stringMatrix.set(0, 2, 'a'), stringMatrix.set(1, 2, 'd'), stringMatrix.set(2, 2, 'b')
// Count the number of times the regex patterns `'^(a|c)$'` and `'^(b|d)$'` occur
array regexes = array.from('^(a|c)$', '^(b|d)$')
map countMap = stringMatrix.count(regexes)
array mapKeys = countMap.keys() // Returns
array mapValues = countMap.values() // Returns
An optional comparison operator can be specified to count the number of times an equality was satisfied for `float`, `int`, and `bool` methods of `count()`.
intArray = array.from(2, 2, 2, 3, 4, 4, 4, 4, 4, 6, 6)
// Count the number of times an element is greater than 4
countInt = intArray.count(4, '>') // Returns 2
When passing an array of values to count and a comparison operator, the operator will apply to each value.
intArray = array.from(2, 2, 2, 3, 4, 4, 4, 4, 4, 6, 6)
values = array.from(3, 4)
// Count the number of times and element is greater than 3 and 4
map countMap = intArray.count(values, '>')
array mapKeys = countMap.keys() // Returns
array mapValues = countMap.values() // Returns
Multiple comparison operators can be applied when counting multiple values.
intMatrix = matrix.new(3, 3, 0)
intMatrix.set(0, 0, 2), intMatrix.set(1, 0, 3), intMatrix.set(2, 0, 5)
intMatrix.set(0, 1, 2), intMatrix.set(1, 1, 4), intMatrix.set(2, 1, 2)
intMatrix.set(0, 2, 5), intMatrix.set(1, 2, 2), intMatrix.set(2, 2, 3)
values = array.from(3, 4)
comparisons = array.from('<', '>')
// Count the number of times an element is less than 3 and greater than 4
map countMap = intMatrix.count(values, comparisons)
array mapKeys = countMap.keys() // Returns
array mapValues = countMap.values() // Returns

Holographic Market Microstructure | AlphaNattHolographic Market Microstructure | AlphaNatt
A multidimensional, holographically-rendered framework designed to expose the invisible forces shaping every candle — liquidity voids, smart money footprints, order flow imbalances, and structural evolution — in real time.
---
📘 Overview
The Holographic Market Microstructure (HMS) is not a traditional indicator. It’s a visual architecture built to interpret the true anatomy of the market — a living data structure that fuses price, volume, and liquidity into one coherent holographic layer.
Instead of reacting to candles, HMS visualizes the market’s underlying micro-dynamics : where liquidity hides, where volume flows, and how structure morphs as smart money accumulates or distributes.
Designed for system-based traders, volume analysts, and liquidity theorists who demand to see the unseen — the invisible grid driving every price movement.
---
🔬 Core Analytical Modules
Microstructure Analysis
Deconstructs each bar’s internal composition to identify imbalance between aggressive buying and selling. Using a configurable Imbalance Ratio and Liquidity Threshold , the algorithm marks low-liquidity zones and price inefficiencies as “liquidity voids.”
• Detects hidden supply/demand gaps.
• Quantifies micro-level absorption and exhaustion.
• Reveals flow compression and expansion phases.
Smart Money Tracking
Applies advanced volume-rate-of-change and price momentum relationships to map institutional activity.
• Accumulation Zones – Where price rises on expanding volume.
• Distribution Zones – Where price declines on rising volume.
• Automatically visualized as glowing boxes, layered through time to simulate footprint persistence.
Fractal Structure Mapping
Reveals the recursive nature of price formation. HMS detects fractal highs/lows, then connects them into an evolving structure.
• Defines nested market structure across multiple scales.
• Maps trend progression and transition points.
• Renders with adaptive glow lines to reflect depth and strength.
Volume Heat Map
Transforms historical volume data into a 3D holographic heat projection.
• Each band represents a volume-weighted price level.
• Gradient brightness = relative participation intensity.
• Helps identify volume nodes, voids, and liquidity corridors.
HUD Display System
Real-time analytical dashboard summarizing the system’s internal metrics directly on the chart.
• Flow, Structure, Smart$, Liquidity, and Divergence — all live.
• Designed for both scalpers and swing traders to assess micro-context instantly.
---
🧠 Smart Money Intelligence Layer
The Smart Money Index dynamically evaluates the harmony (or conflict) between price momentum and volume acceleration. When institutions accumulate or distribute discreetly, volume surges ahead of price. HMS detects this divergence and overlays it as glowing smart money zones.
◈ ACCUM → Institutional absorption, early uptrend formation.
◈ DISTRIB → Distribution and top-heavy conditions.
○ IDLE → Neutral flow equilibrium.
Divergences between price and volume are signaled using holographic alerts ( ⚠ ALERT ) to highlight exhaustion or trap conditions — often precursors to structural reversals.
---
🌀 Fractal Market Structure Engine
The fractal subsystem recursively identifies local pivot symmetry, connecting micro-structural highs and lows into a holographic skeleton.
• Bullish Structure — Higher highs & higher lows align (▲ BULLISH).
• Bearish Structure — Lower highs & lower lows dominate (▼ BEARISH).
• Ranging — Fractal symmetry balance (◆ RANGING).
Each transition is visually represented through adaptive glow intensity, producing a living contour of market evolution .
---
🔥 Volume Heat Map Projection
The heatmap acts as a volumetric X-ray of the recent 100–300 bars. Each horizontal segment reflects liquidity density, rendered with gradient opacity from cold (inactive) to hot (highly active).
• Detects hidden accumulation shelves and distribution ridges.
• Identifies imbalanced liquidity corridors (voids).
• Reveals the invisible scaffolding of the order book.
When combined with smart money zones and structure lines, it creates a multi-layered holographic perspective — allowing traders to see liquidity clusters and their interaction with evolving structure in real time.
---
💎 Holographic Visual Engine
Every element of HMS is dynamically color-mapped to its visual theme . Each theme carries a distinct personality:
Aeon — Neon blue plasma aesthetic; futuristic and fluid.
Cyber — High-contrast digital energy; circuit-like clarity.
Quantum — Deep space gradients; reflective of non-linear flow.
Neural — Organic transitions; biological intelligence simulation.
Plasma — Vapor-bright gradients; high-energy reactive feedback.
Crystal — Minimalist, transparent geometry; pristine data visibility.
Optional Glow Effects and Pulse Animations create a living hologram that responds to real-time market conditions.
---
🧭 HUD Analytics Table
A live data matrix placed anywhere on-screen (top, middle, or side). It summarizes five critical systems:
Flow: Order flow bias — ▲ BUYING / ▼ SELLING / ◆ NEUTRAL.
Struct: Microstructure direction — ▲ BULLISH / ▼ BEARISH / ◆ RANGING.
Smart$: Institutional behavior — ◈ ACCUM / ◈ DISTRIB / ○ IDLE.
Liquid: Market efficiency — ⚡ VOID / ● NORMAL.
Diverg: Price/Volume correlation — ⚠ ALERT / ✓ CLEAR.
Each metric’s color dynamically adjusts according to live readings, effectively serving as a neural HUD layer for rapid interpretation.
---
🚨 Alert Conditions
Stay informed in real time with built-in alerts that trigger under specific structural or liquidity conditions.
Liquidity Void Detected — Market inefficiency or thin volume region identified.
Strong Order Flow Detected — Aggressive buying or selling momentum shift.
Smart Money Activity — Institutional accumulation or distribution underway.
Price/Volume Divergence — Volume fails to confirm price trend.
Market Structure Shift — Fractal structure flips directional bias.
---
⚙️ Customization Parameters
Adjustable Microstructure Depth (20–200 bars).
Configurable Imbalance Ratio and Liquidity Threshold .
Adaptive Smart Money Sensitivity via Accumulation Threshold (%).
Multiple Fractal Depth Layers for precise structural analysis.
Scalable Heatmap Resolution (5–20 levels) and opacity control.
Selectable HUD Position to suit personal layout preferences.
Each parameter adjusts the balance between visual clarity and data density , ensuring optimal performance across intraday and macro timeframes alike.
---
🧩 Trading Application
Identify early signs of institutional activity before breakouts.
Track structure transitions with fractal precision.
Locate hidden liquidity voids and high-value areas.
Confirm strength of trends using order-flow bias.
Detect volume-based divergences that often precede reversals.
HMS is designed not just for observation — but for contextual understanding . Its purpose is to help traders anchor strategies in liquidity and flow dynamics rather than surface-level price action.
---
🪞 Philosophy
Markets are holographic. Each candle contains a reflection of every other candle — a fractal within a fractal, a structure within a structure. The HMS is built to reveal that reflection, allowing traders to see through the market’s multidimensional fabric.
---
Developed by: AlphaNatt
Version: v6
Category: Market Microstructure | Volume Intelligence
Framework: PineScript v6 | Holographic Visualization System
Not financial advice

PriceFormatLibrary for automatically converting price values to formatted strings
matching the same format that TradingView uses to display open/high/low/close prices on the chart.
█ OVERVIEW
This library is intended for Pine Coders who are authors of scripts that display numbers onto a user's charts. Typically, 𝚜𝚝𝚛.𝚝𝚘𝚜𝚝𝚛𝚒𝚗𝚐() would be used to convert a number into a string which can be displayed in a label / box / table, but this only works well for values that are formatted as a simple decimal number. The purpose of this library is to provide an easy way to create a formatted string for values which use other types of formats besides the decimal format.
The main functions exported by this library are:
𝚏𝚘𝚛𝚖𝚊𝚝𝙿𝚛𝚒𝚌𝚎() - creates a formatted string from a price value
𝚖𝚎𝚊𝚜𝚞𝚛𝚎𝙿𝚛𝚒𝚌𝚎𝙲𝚑𝚊𝚗𝚐𝚎() - creates a formatted string from the distance between two prices
𝚝𝚘𝚜𝚝𝚛𝚒𝚗𝚐() - an alternative to the built-in 𝚜𝚝𝚛.𝚝𝚘𝚜𝚝𝚛𝚒𝚗𝚐(𝚟𝚊𝚕𝚞𝚎, 𝚏𝚘𝚛𝚖𝚊𝚝)
This library also exports some auxiliary functions which are used under the hood of the previously mentioned functions, but can also be useful to Pine Coders that need fine-tuned control for customized formatting of numeric values:
Functions that determine information about the current chart:
𝚒𝚜𝙵𝚛𝚊𝚌𝚝𝚒𝚘𝚗𝚊𝚕𝙵𝚘𝚛𝚖𝚊𝚝(), 𝚒𝚜𝚅𝚘𝚕𝚞𝚖𝚎𝙵𝚘𝚛𝚖𝚊𝚝(), 𝚒𝚜𝙿𝚎𝚛𝚌𝚎𝚗𝚝𝚊𝚐𝚎𝙵𝚘𝚛𝚖𝚊𝚝(), 𝚒𝚜𝙳𝚎𝚌𝚒𝚖𝚊𝚕𝙵𝚘𝚛𝚖𝚊𝚝(), 𝚒𝚜𝙿𝚒𝚙𝚜𝙵𝚘𝚛𝚖𝚊𝚝()
Functions that convert a 𝚏𝚕𝚘𝚊𝚝 value to a formatted string:
𝚊𝚜𝙳𝚎𝚌𝚒𝚖𝚊𝚕(), 𝚊𝚜𝙿𝚒𝚙𝚜(), 𝚊𝚜𝙵𝚛𝚊𝚌𝚝𝚒𝚘𝚗𝚊𝚕(), 𝚊𝚜𝚅𝚘𝚕𝚞𝚖𝚎()
█ EXAMPLES
• Simple Example
This example shows the simplest way to utilize this library.
//@version=6
indicator("Simple Example")
import n00btraders/PriceFormat/1
var table t = table.new(position.middle_right, 2, 1, bgcolor = color.new(color.blue, 90), force_overlay = true)
if barstate.isfirst
table.cell(t, 0, 0, "Current Price: ", text_color = color.black, text_size = 40)
table.cell(t, 1, 0, text_color = color.blue, text_size = 40)
if barstate.islast
string lastPrice = close.formatPrice() // Simple, easy way to format price
table.cell_set_text(t, 1, 0, lastPrice)
• Complex Example
This example calls all of the main functions and uses their optional arguments.
//@version=6
indicator("Complex Example")
import n00btraders/PriceFormat/1
// Enum values that can be used as optional arguments
precision = input.enum(PriceFormat.Precision.DEFAULT)
language = input.enum(PriceFormat.Language.ENGLISH)
// Main library functions used to create formatted strings
string formattedOpen = open.formatPrice(precision, language, allowPips = true)
string rawOpenPrice = PriceFormat.tostring(open, format.price)
string formattedClose = close.formatPrice(precision, language, allowPips = true)
string rawClosePrice = PriceFormat.tostring(close, format.price)
= PriceFormat.measurePriceChange(open, close, precision, language, allowPips = true)
// Labels to display formatted values on chart
string prices = str.format("Open: {0} ({1}) Close: {2} ({3})", formattedOpen, rawOpenPrice, formattedClose, rawClosePrice)
string change = str.format("Change (close - open): {0} / {1}", distance, ticks)
label.new(chart.point.now(high), prices, yloc = yloc.abovebar, textalign = text.align_left, force_overlay = true)
label.new(chart.point.now(low), change, yloc = yloc.belowbar, style = label.style_label_up, force_overlay = true)
█ NOTES
• Function Descriptions
The library source code uses Markdown for the exported functions. Hover over a function/method call in the Pine Editor to display formatted, detailed information about the function/method.
• Precision Settings
The Precision option in the chart settings can change the format of how prices are displayed on the chart. Since the user's selected choice cannot be known through any Pine built-in variable, this library provides a 𝙿𝚛𝚎𝚌𝚒𝚜𝚒𝚘𝚗 enum that can be used as an optional script input for the user to specify their selected choice.
• Language Settings
The Language option in the user menu can change the decimal/grouping separators in the prices that are displayed on the chart. Since the user's selected choice cannot be known through any Pine built-in variable, this library provides a 𝙻𝚊𝚗𝚐𝚞𝚊𝚐𝚎 enum that can be used as an optional script input for the user to specify their selected choice.
█ EXPORTED FUNCTIONS
method formatPrice(price, precision, language, allowPips)
Formats a price value to match how it would be displayed on the user's current chart.
Namespace types: series float, simple float, input float, const float
Parameters:
price (float) : The value to format.
precision (series Precision) : A Precision.* enum value.
language (series Language) : A Language.* enum value.
allowPips (simple bool) : Whether to allow decimal numbers to display as pips.
Returns: Automatically formatted price string.
measurePriceChange(startPrice, endPrice, precision, language, allowPips)
Measures a change in price in terms of both distance and ticks.
Parameters:
startPrice (float) : The starting price.
endPrice (float) : The ending price.
precision (series Precision) : A Precision.* enum value.
language (series Language) : A Language.* enum value.
allowPips (simple bool) : Whether to allow decimal numbers to display as pips.
Returns: A tuple of formatted strings: .
method tostring(value, format)
Alternative to the Pine `str.tostring(value, format)` built-in function.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : (series float) The value to format.
format (string) : (series string) The format string.
Returns: String in the specified format.
isFractionalFormat()
Determines if the default behavior of the chart's price scale is to use a fractional format.
Returns: True if the chart can display prices in fractional format.
isVolumeFormat()
Determines if the default behavior of the chart's price scale is to display prices as volume.
Returns: True if the chart can display prices as volume.
isPercentageFormat()
Determines if the default behavior of the chart's price scale is to display percentages.
Returns: True if the chart can display prices as percentages.
isDecimalFormat()
Determines if the default behavior of the chart's price scale is to use a decimal format.
Returns: True if the chart can display prices in decimal format.
isPipsFormat()
Determines if the current symbol's prices can be displayed as pips.
Returns: True if the chart can display prices as pips.
method asDecimal(value, precision, minTick, decimalSeparator, groupingSeparator, eNotation)
Converts a number to a string in decimal format.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : The value to format.
precision (int) : Number of decimal places.
minTick (float) : Minimum tick size.
decimalSeparator (string) : The decimal separator.
groupingSeparator (string) : The thousands separator, aka digit group separator.
eNotation (bool) : Whether the result should use E notation.
Returns: String in decimal format.
method asPips(value, priceScale, minMove, minMove2, decimalSeparator, groupingSeparator)
Converts a number to a string in decimal format with the last digit replaced by a superscript.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : The value to format.
priceScale (int) : Price scale.
minMove (int) : Min move.
minMove2 (int) : Min move 2.
decimalSeparator (string) : The decimal separator.
groupingSeparator (string) : The thousands separator, aka digit group separator.
Returns: String in decimal format with an emphasis on the pip value.
method asFractional(value, priceScale, minMove, minMove2, fractionalSeparator1, fractionalSeparator2)
Converts a number to a string in fractional format.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : The value to format.
priceScale (int) : Price scale.
minMove (int) : Min move.
minMove2 (int) : Min move 2.
fractionalSeparator1 (string) : The primary fractional separator.
fractionalSeparator2 (string) : The secondary fractional separator.
Returns: String in fractional format.
method asVolume(value, precision, minTick, decimalSeparator, groupingSeparator, spacing)
Converts a number to a string in volume format.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : The value to format.
precision (int) : Maximum number of decimal places.
minTick (float) : Minimum tick size.
decimalSeparator (string) : The decimal separator.
groupingSeparator (string) : The thousands separator, aka digit group separator.
spacing (string) : The whitespace separator.
Returns: String in volume format.
LogNormalLibrary "LogNormal"
A collection of functions used to model skewed distributions as log-normal.
Prices are commonly modeled using log-normal distributions (ie. Black-Scholes) because they exhibit multiplicative changes with long tails; skewed exponential growth and high variance. This approach is particularly useful for understanding price behavior and estimating risk, assuming continuously compounding returns are normally distributed.
Because log space analysis is not as direct as using math.log(price) , this library extends the Error Functions library to make working with log-normally distributed data as simple as possible.
- - -
QUICK START
Import library into your project
Initialize model with a mean and standard deviation
Pass model params between methods to compute various properties
var LogNorm model = LN.init(arr.avg(), arr.stdev()) // Assumes the library is imported as LN
var mode = model.mode()
Outputs from the model can be adjusted to better fit the data.
var Quantile data = arr.quantiles()
var more_accurate_mode = mode.fit(model, data) // Fits value from model to data
Inputs to the model can also be adjusted to better fit the data.
datum = 123.45
model_equivalent_datum = datum.fit(data, model) // Fits value from data to the model
area_from_zero_to_datum = model.cdf(model_equivalent_datum)
- - -
TYPES
There are two requisite UDTs: LogNorm and Quantile . They are used to pass parameters between functions and are set automatically (see Type Management ).
LogNorm
Object for log space parameters and linear space quantiles .
Fields:
mu (float) : Log space mu ( µ ).
sigma (float) : Log space sigma ( σ ).
variance (float) : Log space variance ( σ² ).
quantiles (Quantile) : Linear space quantiles.
Quantile
Object for linear quantiles, most similar to a seven-number summary .
Fields:
Q0 (float) : Smallest Value
LW (float) : Lower Whisker Endpoint
LC (float) : Lower Whisker Crosshatch
Q1 (float) : First Quartile
Q2 (float) : Second Quartile
Q3 (float) : Third Quartile
UC (float) : Upper Whisker Crosshatch
UW (float) : Upper Whisker Endpoint
Q4 (float) : Largest Value
IQR (float) : Interquartile Range
MH (float) : Midhinge
TM (float) : Trimean
MR (float) : Mid-Range
- - -
TYPE MANAGEMENT
These functions reliably initialize and update the UDTs. Because parameterization is interdependent, avoid setting the LogNorm and Quantile fields directly .
init(mean, stdev, variance)
Initializes a LogNorm object.
Parameters:
mean (float) : Linearly measured mean.
stdev (float) : Linearly measured standard deviation.
variance (float) : Linearly measured variance.
Returns: LogNorm Object
set(ln, mean, stdev, variance)
Transforms linear measurements into log space parameters for a LogNorm object.
Parameters:
ln (LogNorm) : Object containing log space parameters.
mean (float) : Linearly measured mean.
stdev (float) : Linearly measured standard deviation.
variance (float) : Linearly measured variance.
Returns: LogNorm Object
quantiles(arr)
Gets empirical quantiles from an array of floats.
Parameters:
arr (array) : Float array object.
Returns: Quantile Object
- - -
DESCRIPTIVE STATISTICS
Using only the initialized LogNorm parameters, these functions compute a model's central tendency and standardized moments.
mean(ln)
Computes the linear mean from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
median(ln)
Computes the linear median from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
mode(ln)
Computes the linear mode from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
variance(ln)
Computes the linear variance from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
skewness(ln)
Computes the linear skewness from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
kurtosis(ln, excess)
Computes the linear kurtosis from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
excess (bool) : Excess Kurtosis (true) or regular Kurtosis (false).
Returns: Between 0 and ∞
hyper_skewness(ln)
Computes the linear hyper skewness from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
hyper_kurtosis(ln, excess)
Computes the linear hyper kurtosis from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
excess (bool) : Excess Hyper Kurtosis (true) or regular Hyper Kurtosis (false).
Returns: Between 0 and ∞
- - -
DISTRIBUTION FUNCTIONS
These wrap Gaussian functions to make working with model space more direct. Because they are contained within a log-normal library, they describe estimations relative to a log-normal curve, even though they fundamentally measure a Gaussian curve.
pdf(ln, x, empirical_quantiles)
A Probability Density Function estimates the probability density . For clarity, density is not a probability .
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate for which a density will be estimated.
empirical_quantiles (Quantile) : Quantiles as observed in the data (optional).
Returns: Between 0 and ∞
cdf(ln, x, precise)
A Cumulative Distribution Function estimates the area under a Log-Normal curve between Zero and a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ccdf(ln, x, precise)
A Complementary Cumulative Distribution Function estimates the area under a Log-Normal curve between a linear X coordinate and Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
cdfinv(ln, a, precise)
An Inverse Cumulative Distribution Function reverses the Log-Normal cdf() by estimating the linear X coordinate from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
ccdfinv(ln, a, precise)
An Inverse Complementary Cumulative Distribution Function reverses the Log-Normal ccdf() by estimating the linear X coordinate from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
cdfab(ln, x1, x2, precise)
A Cumulative Distribution Function from A to B estimates the area under a Log-Normal curve between two linear X coordinates (A and B).
Parameters:
ln (LogNorm) : Object of log space parameters.
x1 (float) : First linear X coordinate .
x2 (float) : Second linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ott(ln, x, precise)
A One-Tailed Test transforms a linear X coordinate into an absolute Z Score before estimating the area under a Log-Normal curve between Z and Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 0.5
ttt(ln, x, precise)
A Two-Tailed Test transforms a linear X coordinate into symmetrical ± Z Scores before estimating the area under a Log-Normal curve from Zero to -Z, and +Z to Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ottinv(ln, a, precise)
An Inverse One-Tailed Test reverses the Log-Normal ott() by estimating a linear X coordinate for the right tail from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Half a normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
tttinv(ln, a, precise)
An Inverse Two-Tailed Test reverses the Log-Normal ttt() by estimating two linear X coordinates from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Linear space tuple :
- - -
UNCERTAINTY
Model-based measures of uncertainty, information, and risk.
sterr(sample_size, fisher_info)
The standard error of a sample statistic.
Parameters:
sample_size (float) : Number of observations.
fisher_info (float) : Fisher information.
Returns: Between 0 and ∞
surprisal(p, base)
Quantifies the information content of a single event.
Parameters:
p (float) : Probability of the event .
base (float) : Logarithmic base (optional).
Returns: Between 0 and ∞
entropy(ln, base)
Computes the differential entropy (average surprisal).
Parameters:
ln (LogNorm) : Object of log space parameters.
base (float) : Logarithmic base (optional).
Returns: Between 0 and ∞
perplexity(ln, base)
Computes the average number of distinguishable outcomes from the entropy.
Parameters:
ln (LogNorm)
base (float) : Logarithmic base used for Entropy (optional).
Returns: Between 0 and ∞
value_at_risk(ln, p, precise)
Estimates a risk threshold under normal market conditions for a given confidence level.
Parameters:
ln (LogNorm) : Object of log space parameters.
p (float) : Probability threshold, aka. the confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
value_at_risk_inv(ln, value_at_risk, precise)
Reverses the value_at_risk() by estimating the confidence level from the risk threshold.
Parameters:
ln (LogNorm) : Object of log space parameters.
value_at_risk (float) : Value at Risk.
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
conditional_value_at_risk(ln, p, precise)
Estimates the average loss beyond a confidence level, aka. expected shortfall.
Parameters:
ln (LogNorm) : Object of log space parameters.
p (float) : Probability threshold, aka. the confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
conditional_value_at_risk_inv(ln, conditional_value_at_risk, precise)
Reverses the conditional_value_at_risk() by estimating the confidence level of an average loss.
Parameters:
ln (LogNorm) : Object of log space parameters.
conditional_value_at_risk (float) : Conditional Value at Risk.
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
partial_expectation(ln, x, precise)
Estimates the partial expectation of a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and µ
partial_expectation_inv(ln, partial_expectation, precise)
Reverses the partial_expectation() by estimating a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
partial_expectation (float) : Partial Expectation .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
conditional_expectation(ln, x, precise)
Estimates the conditional expectation of a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between X and ∞
conditional_expectation_inv(ln, conditional_expectation, precise)
Reverses the conditional_expectation by estimating a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
conditional_expectation (float) : Conditional Expectation .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
fisher(ln, log)
Computes the Fisher Information Matrix for the distribution, not a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
log (bool) : Sets if the matrix should be in log (true) or linear (false) space.
Returns: FIM for the distribution
fisher(ln, x, log)
Computes the Fisher Information Matrix for a linear X coordinate, not the distribution itself.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
log (bool) : Sets if the matrix should be in log (true) or linear (false) space.
Returns: FIM for the linear X coordinate
confidence_interval(ln, x, sample_size, confidence, precise)
Estimates a confidence interval for a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
sample_size (float) : Number of observations.
confidence (float) : Confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: CI for the linear X coordinate
- - -
CURVE FITTING
An overloaded function that helps transform values between spaces. The primary function uses quantiles, and the overloads wrap the primary function to make working with LogNorm more direct.
fit(x, a, b)
Transforms X coordinate between spaces A and B.
Parameters:
x (float) : Linear X coordinate from space A .
a (LogNorm | Quantile | array) : LogNorm, Quantile, or float array.
b (LogNorm | Quantile | array) : LogNorm, Quantile, or float array.
Returns: Adjusted X coordinate
- - -
EXPORTED HELPERS
Small utilities to simplify extensibility.
z_score(ln, x)
Converts a linear X coordinate into a Z Score.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate.
Returns: Between -∞ and +∞
x_coord(ln, z)
Converts a Z Score into a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
z (float) : Standard normal Z Score.
Returns: Between 0 and ∞
iget(arr, index)
Gets an interpolated value of a pseudo -element (fictional element between real array elements). Useful for quantile mapping.
Parameters:
arr (array) : Float array object.
index (float) : Index of the pseudo element.
Returns: Interpolated value of the arrays pseudo element.

Range Oscillator (Zeiierman)█ Overview
Range Oscillator (Zeiierman) is a dynamic market oscillator designed to visualize how far the price is trading relative to its equilibrium range. Instead of relying on traditional overbought/oversold thresholds, it uses adaptive range detection and heatmap coloring to reveal where price is trading within a volatility-adjusted band.
The oscillator maps market movement as a heat zone, highlighting when the price approaches the upper or lower range boundaries and signaling potential breakout or mean-reversion conditions.
Highlights
Adaptive range detection based on ATR and weighted price movement.
Heatmap-driven coloring that visualizes volatility pressure and directional bias.
Clear transition zones for detecting trend shifts and equilibrium points.
█ How It Works
⚪ Range Detection
The indicator identifies a dynamic price range using two main parameters:
Minimum Range Length: The number of bars required to confirm that a valid range exists.
Range Width Multiplier: Expands or contracts the detected range proportionally to the ATR (Average True Range).
This approach ensures that the oscillator automatically adapts to both trending and ranging markets without manual recalibration.
⚪ Weighted Mean Calculation
Instead of a simple moving average, the script calculates a weighted equilibrium mean based on the size of consecutive candle movements:
Larger price changes are given greater weight, emphasizing recent volatility.
⚪ Oscillator Formula
Once the range and equilibrium mean are defined, the oscillator computes:
Osc = 100 * (Close - Mean) / RangeATR
This normalizes price distance relative to the dynamic range size — producing consistent readings across volatile and quiet periods.
█ Heatmap Logic
The Range Oscillator includes a built-in heatmap engine that color-codes each oscillator value based on recent price interaction intensity:
Strong Bullish Zones: Bright green — price faces little resistance upward.
Weak Bullish Zones: Muted green — uptrend continuation but with minor hesitation.
Transition Zones: Blue — areas of uncertainty or trend shift.
Weak Bearish Zones: Maroon — downtrend pressure but soft momentum.
Strong Bearish Zones: Bright red — strong downside continuation with low resistance.
Each color band adapts dynamically using:
Number of Heat Levels: Controls granularity of the heatmap.
Minimum Touches per Level: Defines how reactive or “sensitive” each color zone is.
█ How to Use
⚪ Trend & Momentum Confirmation
When the oscillator stays above +0 with green coloring, it suggests sustained bullish pressure.
Similarly, readings below –0 with red coloring, it suggests sustained bearish pressure.
⚪ Range Breakouts
When the oscillator line breaks above +100 or below –100, the price is exceeding its normal volatility range, often signaling breakout potential or exhaustion extremes.
⚪ Mean Reversion Trades
Look for the oscillator to cross back toward zero after reaching an extreme. These transitions (often marked by blue tones) can identify early reversals or range resets.
⚪ Divergence
Use oscillator peaks and troughs relative to price action to spot hidden strength or weakness before the next move.
█ Settings
Minimum Range Length: Number of bars needed to confirm a valid range.
Range Width Multiplier: Expands or contracts range width based on ATR.
Number of Heat Levels: Number of gradient bands used in the oscillator.
Minimum Touches per Level: Sensitivity threshold for when a zone becomes “hot.”
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

Volume Surprise [LuxAlgo]The Volume Surprise tool displays the trading volume alongside the expected volume at that time, allowing users to spot unexpected trading activity on the chart easily.
The tool includes an extrapolation of the estimated volume for future periods, allowing forecasting future trading activity.
🔶 USAGE
We define Volume Surprise as a situation where the actual trading volume deviates significantly from its expected value at a given time.
Being able to determine if trading activity is higher or lower than expected allows us to precisely gauge the interest of market participants in specific trends.
A histogram constructed from the difference between the volume and expected volume is provided to easily highlight the difference between the two and may be used as a standalone.
The tool can also help quantify the impact of specific market events, such as news about an instrument. For example, an important announcement leading to volume below expectations might be a sign of market participants underestimating the impact of the announcement.
Like in the example above, it is possible to observe cases where the volume significantly differs from the expected one, which might be interpreted as an anomaly leading to a correction.
🔹 Detecting Rare Trading Activity
Expected volume is defined as the mean (or median if we want to limit the impact of outliers) of the volume grouped at a specific point in time. This value depends on grouping volume based on periods, which can be user-defined.
However, it is possible to adjust the indicator to overestimate/underestimate expected volume, allowing for highlighting excessively high or low volume at specific times.
In order to do this, select "Percentiles" as the summary method, and change the percentiles value to a value that is close to 100 (overestimate expected volume) or to 0 (underestimate expected volume).
In the example above, we are only interested in detecting volume that is excessively high, we use the 95th percentile to do so, effectively highlighting when volume is higher than 95% of the volumes recorded at that time.
🔶 DETAILS
🔹 Choosing the Right Periods
Our expected volume value depends on grouping volume based on periods, which can be user-defined.
For example, if only the hourly period is selected, volumes are grouped by their respective hours. As such, to get the expected volume for the hour 7 PM, we collect and group the historical volumes that occurred at 7 PM and average them to get our expected value at that time.
Users are not limited to selecting a single period, and can group volume using a combination of all the available periods.
Do note that when on lower timeframes, only having higher periods will lead to less precise expected values. Enabling periods that are too low might prevent grouping. Finally, enabling a lot of periods will, on the other hand, lead to a lot of groups, preventing the ability to get effective expected values.
In order to avoid changing periods by navigating across multiple timeframes, an "Auto Selection" setting is provided.
🔹 Group Length
The length setting allows controlling the maximum size of a volume group. Using higher lengths will provide an expected value on more historical data, further highlighting recurring patterns.
🔹 Recommended Assets
Obtaining the expected volume for a specific period (time of the day, day of the week, quarter, etc) is most effective when on assets showing higher signs of periodicity in their trading activity.
This is visible on stocks, futures, and forex pairs, which tend to have a defined, recognizable interval with usually higher trading activity.
Assets such as cryptocurrencies will usually not have a clearly defined periodic trading activity, which lowers the validity of forecasts produced by the tool, as well as any conclusions originating from the volume to expected volume comparisons.
🔶 SETTINGS
Length: Maximum number of records in a volume group for a specific period. Older values are discarded.
Smooth: Period of a SMA used to smooth volume. The smoothing affects the expected value.
🔹 Periods
Auto Selection: Automatically choose a practical combination of periods based on the chart timeframe.
Custom periods can be used if disabling "Auto Selection". Available periods include:
- Minutes
- Hours
- Days (can be: Day of Week, Day of Month, Day of Year)
- Months
- Quarters
🔹 Summary
Method: Method used to obtain the expected value. Options include Mean (default) or Percentile.
Percentile: Percentile number used if "Method" is set to "Percentile". A value of 50 will effectively use a median for the expected value.
🔹 Forecast
Forecast Window: Number of bars ahead for which the expected volume is predicted.
Style: Style settings of the forecast.

Smooth Theil-SenI wanted to build a Theil-Sen estimator that could run on more than one bar and produce smoother output than the standard implementation. Theil-Sen regression is a non-parametric method that calculates the median slope between all pairs of points in your dataset, which makes it extremely robust to outliers. The problem is that median operations produce discrete jumps, especially when you're working with limited sample sizes. Every time the median shifts from one value to another, you get a step change in your regression line, which creates visual choppiness that can be distracting even though the underlying calculations are sound.
The solution I ended up going with was convolving a Gaussian kernel around the center of the sorted lists to get a more continuous median estimate. Instead of just picking the middle value or averaging the two middle values when you have an even sample size, the Gaussian kernel weights the values near the center more heavily and smoothly tapers off as you move away from the median position. This creates a weighted average that behaves like a median in terms of robustness but produces much smoother transitions as new data points arrive and the sorted list shifts.
There are variance tradeoffs with this approach since you're no longer using the pure median, but they're minimal in practice. The kernel weighting stays concentrated enough around the center that you retain most of the outlier resistance that makes Theil-Sen useful in the first place. What you gain is a regression line that updates smoothly instead of jumping discretely, which makes it easier to spot genuine trend changes versus just the statistical noise of median recalculation. The smoothness is particularly noticeable when you're running the estimator over longer lookback periods where the sorted list is large enough that small kernel adjustments have less impact on the overall center of mass.
The Gaussian kernel itself is a bell curve centered on the median position, with a standard deviation you can tune to control how much smoothing you want. Tighter kernels stay closer to the pure median behavior and give you more discrete steps. Wider kernels spread the weighting further from the center and produce smoother output at the cost of slightly reduced outlier resistance. The default settings strike a balance that keeps the estimator robust while removing most of the visual jitter.
Running Theil-Sen on multiple bars means calculating slopes between all pairs of points across your lookback window, sorting those slopes, and then applying the Gaussian kernel to find the weighted center of that sorted distribution. This is computationally more expensive than simple moving averages or even standard linear regression, but Pine Script handles it well enough for reasonable lookback lengths. The benefit is that you get a trend estimate that doesn't get thrown off by individual spikes or anomalies in your price data, which is valuable when working with noisy instruments or during volatile periods where traditional regression lines can swing wildly.
The implementation maintains sorted arrays for both the slope calculations and the final kernel weighting, which keeps everything organized and makes the Gaussian convolution straightforward. The kernel weights are precalculated based on the distance from the center position, then applied as multipliers to the sorted slope values before summing to get the final smoothed median slope. That slope gets combined with an intercept calculation to produce the regression line values you see plotted on the chart.
What this really demonstrates is that you can take classical statistical methods like Theil-Sen and adapt them with signal processing techniques like kernel convolution to get behavior that's more suited to real-time visualization. The pure mathematical definition of a median is discrete by nature, but financial charts benefit from smooth, continuous lines that make it easier to track changes over time. By introducing the Gaussian kernel weighting, you preserve the core robustness of the median-based approach while gaining the visual smoothness of methods that use weighted averages. Whether that smoothness is worth the minor variance tradeoff depends on your use case, but for most charting applications, the improved readability makes it a good compromise.

Fair Value Gaps by DGTFair Value Gaps
A refined, multi-timeframe Fair Value Gap (FVG) detection tool that brings institutional imbalance zones to life directly on your chart.
Designed for precision, it visualizes how price delivers into inefficiencies across chart, higher, and lower (intrabar) timeframes — offering a fluid, structural view of liquidity displacement and market flow.
The script continuously tracks unfilled, partially repaired, and fully resolved imbalances, revealing where liquidity inefficiencies concentrate and where price may seek rebalancing.
Overlapping zones naturally expose institutional footprints, potential liquidity targets, and key re-pricing regions within the broader market structure.
KEY FEATURES
⯌ Multi-Timeframe Detection
Detect and display FVGs from the current chart, higher timeframes (HTF), or lower timeframes (LTF)
⯌ Smart Fill Tracking
Automatic real-time monitoring of each FVG’s fill progress with live percentage updates
⯌ Custom Fill Logic
Choose your preferred definition of when a gap is considered filled: Any Touch
Midpoint Reached
Wick Sweep
Body Beyond
⯌ Dynamic Labels & Tooltips
Labels can be toggled on/off. Even when hidden, detailed tooltips remain available by hovering over the FVG midpoint.
⯌ Adaptive Lower-Timeframe Mode
When set to “Auto,” the script intelligently selects the optimal lower timeframe based on the chart resolution.
DISCLAIMER
This script is intended for informational and educational purposes only. It does not constitute financial, investment, or trading advice. All trading decisions made based on its output are solely the responsibility of the user.

TASC 2025.11 The Points and Line Chart█ OVERVIEW
This script implements the Points and Line Chart described by Mohamed Ashraf Mahfouz and Mohamed Meregy in the November 2025 edition of the TASC Traders' Tips , "Efficient Display of Irregular Time Series”. This novel chart type interprets regular time series chart data to create an irregular time series chart.
█ CONCEPTS
When formatting data for display on a price chart, there are two main categorizations of chart types: regular time series (RTS) and irregular time series (ITS).
RTS charts, such as a typical candlestick chart, collect data over a specified amount of time and display it at one point. A one-minute candle, for example, represents the entirety of price movements within the minute that it represents.
ITS charts display data only after certain conditions are met. Since they do not plot at a consistent time period, they are called “irregular”.
Typically, ITS charts, such as Point and Figure (P&F) and Renko charts, focus on price change, plotting only when a certain threshold of change occurs.
The Points and Line (P&L) chart operates similarly to a P&F chart, using price change to determine when to plot points. However, instead of plotting the price in points, the P&L chart (by default) plots the closing price from RTS data. In other words, the P&L chart plots its points at the actual RTS close, as opposed to (price) intervals based on point size. This approach creates an ITS while still maintaining a reference to the RTS data, allowing us to gain a better understanding of time while consolidating the chart into an ITS format.
█ USAGE
Because the P&L chart forms bars based on price action instead of time, it displays displays significantly more history than a typical RTS chart. With this view, we are able to more easily spot support and resistance levels, which we could use when looking to place trades.
In the chart below, we can see over 13 years of data consolidated into one single view.
To view specific chart details, hover over each point of the chart to see a list of information.
In addition to providing a compact view of price movement over larger periods, this new chart type helps make classic chart patterns easier to interpret. When considering breakouts, the closing price provides a clearer representation of the actual breakout, as opposed to point size plots which are limited.
Because P&L is a new charting type, this script still requires a standard RTS chart for proper calculations. However, the main price chart is not intended for interpretation alongside the P&L chart; users can hide the main price series to keep the chart clean.
█ DISPLAYS
This indicator creates two displays: the "Price Display" and the "Data Display".
With the "Price display" setting, users can choose between showing a line or OHLC candles for the P&L drawing. The line display shows the close price of the P&L chart. In the candle display, the close price remains the same, while the open, high, and low values depend on the price action between points.
With the "Data display" setting, users can enable the display of a histogram that shows either the total volume or days/bars between the points in the P&L chart. For example, a reading of 12 days would indicate that the time since the last point was 12 days.
Note: The "Days" setting actually shows the number of chart bars elapsed between P&L points. The displayed value represents days only if the chart uses the "1D" timeframe.
The "Overlay P&L on chart" input controls whether the P&L line or candles appear on the main chart pane or in a separate pane.
Users can deactivate either display by selecting "None" from the corresponding input.
Technical Note: Due to drawing limitations, this indicator has the following display limits:
The line display can show data to 10,000 P&L points.
The candle display and tooltips show data for up to 500 points.
The histograms show data for up to 3,333 points.
█ INPUTS
Reversal Amount: The number of points/steps required to determine a reversal.
Scale size Method: The method used to filter price movements. By default, the P&L chart uses the same scaling method as the P&F chart. Optionally, this scaling method can be changed to use ATR or Percent.
P&L Method: The prices to plot and use for filtering:
“Close” plots the closing price and uses it to determine movements.
“High/Low” uses the high price on upside moves and low price on downside moves.
"Point Size" uses the closing price for filtration, but locks the price to plot at point size intervals.
Simplified Percentile ClusteringSimplified Percentile Clustering (SPC) is a clustering system for trend regime analysis.
Instead of relying on heavy iterative algorithms such as k-means, SPC takes a deterministic approach: it uses percentiles and running averages to form cluster centers directly from the data, producing smooth, interpretable market state segmentation that updates live with every bar.
Most clustering algorithms are designed for offline datasets, they require recomputation, multiple iterations, and fixed sample sizes.
SPC borrows from both statistical normalization and distance-based clustering theory , but simplifies them. Percentiles ensure that cluster centers are resistant to outliers , while the running mean provides a stable mid-point reference.
Unlike iterative methods, SPC’s centers evolve smoothly with time, ideal for charts that must update in real time without sudden reclassification noise.
SPC provides a simple yet powerful clustering heuristic that:
Runs continuously in a charting environment,
Remains interpretable and reproducible,
And allows traders to see how close the current market state is to transitioning between regimes.
Clustering by Percentiles
Traditional clustering methods find centers through iteration. SPC defines them deterministically using three simple statistics within a moving window:
Lower percentile (p_low) → captures the lower basin of feature values.
Upper percentile (p_high) → captures the upper basin.
Mean (mid) → represents the central tendency.
From these, SPC computes stable “centers”:
// K = 2 → two regimes (e.g., bullish / bearish)
=
// K = 3 → adds a neutral zone
=
These centers move gradually with the market, forming live regime boundaries without ever needing convergence steps.
Two clusters capture directional bias; three clusters add a neutral ‘range’ state.
Multi-Feature Fusion
While SPC can cluster a single feature such as RSI, CCI, Fisher Transform, DMI, Z-Score, or the price-to-MA ratio (MAR), its real strength lies in feature fusion. Each feature adds a unique lens to the clustering system. By toggling features on or off, traders can test how each dimension contributes to the regime structure.
In “Clusters” mode, SPC measures how far the current bar is from each cluster center across all enabled features, averages these distances, and assigns the bar to the nearest combined center. This effectively creates a multi-dimensional regime map , where each feature contributes equally to defining the overall market state.
The fusion distance is computed as:
dist := (rsi_d * on_off(use_rsi) + cci_d * on_off(use_cci) + fis_d * on_off(use_fis) + dmi_d * on_off(use_dmi) + zsc_d * on_off(use_zsc) + mar_d * on_off(use_mar)) / (on_off(use_rsi) + on_off(use_cci) + on_off(use_fis) + on_off(use_dmi) + on_off(use_zsc) + on_off(use_mar))
Because each feature can be standardized (Z-Score), the distances remain comparable across different scales.
Fusion mode combines multiple standardized features into a single smooth regime signal.
Visualizing Proximity - The Transition Gradient
Most indicators show binary or discrete conditions (e.g., bullish/bearish). SPC goes further, it quantifies how close the current value is to flipping into the next cluster.
It measures the distances to the two nearest cluster centers and interpolates between them:
rel_pos = min_dist / (min_dist + second_min_dist)
real_clust = cluster_val + (second_val - cluster_val) * rel_pos
This real_clust output forms a continuous line that moves smoothly between clusters:
Near 0.0 → firmly within the current regime
Around 0.5 → balanced between clusters (transition zone)
Near 1.0 → about to flip into the next regime
Smooth interpolation reveals when the market is close to a regime change.
How to Tune the Parameters
SPC includes intuitive parameters to adapt sensitivity and stability:
K Clusters (2–3): Defines the number of regimes. K = 2 for trend/range distinction, K = 3 for trend/neutral transitions.
Lookback: Determines the number of past bars used for percentile and mean calculations. Higher = smoother, more stable clusters. Lower = faster reaction to new trends.
Lower / Upper Percentiles: Define what counts as “low” and “high” states. Adjust to widen or tighten cluster ranges.
Shorter lookbacks react quickly to shifts; longer lookbacks smooth the clusters.
Visual Interpretation
In “Clusters” mode, SPC plots:
A colored histogram for each cluster (red, orange, green depending on K)
Horizontal guide lines separating cluster levels
Smooth proximity transitions between states
Each bar’s color also changes based on its assigned cluster, allowing quick recognition of when the market transitions between regimes.
Cluster bands visualize regime structure and transitions at a glance.
Practical Applications
Identify market regimes (bullish, neutral, bearish) in real time
Detect early transition phases before a trend flip occurs
Fuse multiple indicators into a single consistent signal
Engineer interpretable features for machine-learning research
Build adaptive filters or hybrid signals based on cluster proximity
Final Notes
Simplified Percentile Clustering (SPC) provides a balance between mathematical rigor and visual intuition. It replaces complex iterative algorithms with a clear, deterministic logic that any trader can understand, and yet retains the multidimensional insight of a fusion-based clustering system.
Use SPC to study how different indicators align, how regimes evolve, and how transitions emerge in real time. It’s not about predicting; it’s about seeing the structure of the market unfold.
Disclaimer
This indicator is intended for educational and analytical use.
It does not generate buy or sell signals.
Historical regime transitions are not indicative of future performance.
Always validate insights with independent analysis before making trading decisions.

Adaptive Volume Delta Map---
📊 Adaptive Volume Delta Map (AVDM)
What is Adaptive Volume Delta Map (AVDM)?
The Adaptive Volume Delta Map (AVDM) is a smart, multi-timeframe indicator that visualizes buy and sell volume imbalances directly on the chart.
It adapts automatically to the best available data resolution (tick, second, minute, or daily), allowing traders to analyze market activity with micro-level precision .
In addition to calculating volume delta (the difference between buying and selling pressure), AVDM can display a Volume Distribution Map — a per-price-level visualization showing how volume is split between buyers and sellers.
Key Features
✅ Adaptive Resolution Selection — Automatically chooses the highest possible data granularity — from tick to daily timeframe.
✅ Volume Delta Visualization — Displays delta candles reflecting the dominance of buyers (green), sellers (red), and delta (orange).
✅ Per-Level Volume Map (optional) — Shows detailed buy/sell volume distribution per price level, grouped by `Ticks Per Row`.
✅ Bid/Ask Classification — When enabled, AVDM uses bid/ask logic to classify trade direction with greater accuracy.
✅ Smart Auto-Disable Protection — Automatically disables volume map if too many price levels (>50) are detected — preventing performance degradation.
Inputs Overview
Use Seconds Resolution — Enables use of second-level data (if your TradingView subscription allows it).
Use Tick Resolution — Enables tick-based analysis for the most detailed view. If available, enable both tick and seconds resolution.
Use Bid/Ask Calculated — Uses bid/ask midpoint logic to classify trades.
Show Volume Distribution — Toggles per-price-level buy/sell volume visualization.
Ticks Per Row — Controls how many ticks are grouped per volume level. Reduce this value for finer detail, or increase it to reduce visual load.
Calculated Bars — Sets how many historical bars the indicator should process. Higher value increases accuracy but may impact performance.
How to Use
1. Add the indicator to your chart.
2. Ensure that your symbol provides volume data (and preferably tick or second-level data).
3. The indicator will automatically select the optimal timeframe for detailed calculation.
4. If your TradingView subscription allows second-level data , enable “Use Seconds Resolution.”
5. If your subscription allows tick-level data , enable both “Use Tick Resolution” and “Use Seconds Resolution.”
6. Adjust the “Calculated Bars” input to set how many historical bars the indicator should process.
7. Observe the Volume Delta Candles :
* Green = Buy pressure dominates
* Red = Sell pressure dominates
8. To see buy/sell clustering by price, enable “Show Volume Distribution.”
9. If the indicator disables the map and shows:
" Volume Distribution disabled: Too many price levels detected (>50). Try decreasing 'Ticks Per Row' or using a lower chart resolution. If you don’t care about the map, just turn off 'Show Volume Distribution'. "
— follow the instructions to reduce chart load.
Notes
* Automatically adapts to your chart’s resolution and data availability.
* If your symbol doesn’t provide volume data, a runtime warning will appear.
* Works best on futures , FX , and crypto instruments with high-frequency volume streams.
Why Traders Love It
AVDM combines adaptive resolution , volume delta analysis , and visual distribution mapping into one clean, efficient tool.
Perfect for traders studying:
* Market microstructure
* Aggressive vs. passive participation
* Volume absorption
* Order flow imbalance zones
* Delta-based divergence signals
Technical Highlights
* Built with Pine Script v6
* Adaptive resolution logic (`security_lower_tf`)
* Smart memory-safe map rendering
* Dynamic bid/ask classification
* Automatic overload protection
---
