Volume Weighted Intra Bar LR SkewnessThis indicator analyzes market character by decomposing total
skewness (asymmetry) of a SINGLE BAR into four distinct,
interpretable components based on a Linear Regression model.
Key Features:
1. **Intra-Bar LR Skewness Decomposition:** For each bar on the chart,
the indicator analyzes the underlying price action on a smaller
timeframe ('Intra-Bar Timeframe'). It fits a Linear Regression
line through the intra-bar data to decompose the 3rd Moment:
- **Trend Skewness (Green/Red):** Asymmetry originating from
the slope of the intra-bar regression line. Indicates if the
price path within the bar is geometrically trend-driven.
- **Residual Skewness (Yellow):** Asymmetry of the noise
around the regression line. Captures "Tail Risk" or sudden
shocks within the bar that deviate from the main path.
- **Within-Bar Skewness (Blue):** Asymmetry derived from the
microstructure of individual intra-bar candles.
- **Interaction Skewness (Dark Grey):** Asymmetry caused by
the correlation between price levels and volatility within
the bar (e.g., volatility expanding as price drops).
2. **Visual Decomposition Logic:** Total Skewness is the
primary metric displayed. Since statistical moments are additive,
this indicator calculates the *exact* Total Skewness and partitions
the columns based on the Law of Total Moments.
3. **Dual Display Modes:** The indicator offers two modes to
visualize this decomposition:
- **Absolute Mode:** Plots the *total* skewness as a
stacked column chart. Stacking logic groups components with
the same sign to ensure visual clarity.
- **Relative Mode:** Plots the direct *contribution ratio*
(proportion) of each component relative to the total sum,
ideal for identifying the dominant driver (Trend vs. Noise).
4. **Calculation Options:**
- **Normalization:** An optional 'Normalize' setting
transforms inputs into logarithmic space, analyzing the
skewness of *returns* rather than absolute prices.
- **Volume Weighting:** An option (`Volume weighted`) applies
volume weighting to all regression and moment calculations,
emphasizing high-participation moves.
5. **Skewness Cycle Analysis:**
- **Pivot Detection:** Includes a built-in pivot detector
that identifies significant turning points (peaks/valleys) in
the *total* skewness line. (Note: This is only visible
in 'Absolute Mode').
- **Flexible Pivot Algorithms:** Supports various underlying
mathematical models for pivot detection provided by the
core library.
6. **Note on Confirmation (Lag):** Pivot signals are confirmed
using a lookback method. A pivot is only plotted *after*
the `Pivot Right Bars` input has passed, which introduces
an inherent lag.
7. **Multi-Timeframe (MTF) Capability:**
- **MTF Analysis Lines:** The entire intra-bar analysis can be
run on a higher timeframe (using the `Timeframe` input),
with standard options to handle gaps (`Fill Gaps`) and
prevent repainting (`Wait for...`).
- **Limitation:** The Pivot detection (`Calculate Pivots`) is
**disabled** if a Higher Timeframe (HTF) is selected.
8. **Integrated Alerts:** Includes comprehensive alerts for:
- Skewness magnitude (High Positive / High Negative).
- Character changes (Trend vs. Noise dominance).
- Total Skewness pivot (High/Low) detection.
**Caution: Real-Time Data Behavior (Intra-Bar Repainting)**
This indicator uses high-resolution intra-bar data. As a result, the
values on the **current, unclosed bar** (the real-time bar) will
update dynamically as new intra-bar data arrives. This behavior is
normal and necessary for this type of analysis. Signals should only
be considered final **after the main chart bar has closed.**
---
**DISCLAIMER**
1. **For Informational/Educational Use Only:** This indicator is
provided for informational and educational purposes only. It does
not constitute financial, investment, or trading advice, nor is
it a recommendation to buy or sell any asset.
2. **Use at Your Own Risk:** All trading decisions you make based on
the information or signals generated by this indicator are made
solely at your own risk.
3. **No Guarantee of Performance:** Past performance is not an
indicator of future results. The author makes no guarantee
regarding the accuracy of the signals or future profitability.
4. **No Liability:** The author shall not be held liable for any
financial losses or damages incurred directly or indirectly from
the use of this indicator.
5. **Signals Are Not Recommendations:** The alerts and visual signals
(e.g., crossovers) generated by this tool are not direct
recommendations to buy or sell. They are technical observations
for your own analysis and consideration.
Skewness

Volume Weighted Intra Bar SkewnessThis indicator analyzes market sentiment by providing a detailed
view of skewness (asymmetry). It uses data from a lower, intra-bar
timeframe to separate the total skewness of a single bar into
distinct, interpretable components.
Key Features:
1. **Intra-Bar Skewness Decomposition:** For each bar on the chart,
the indicator analyzes the underlying price action on a smaller
timeframe ('Intra-Bar Timeframe'). Unlike Variance, the Third
Central Moment (Skewness) decomposes into three parts:
- **Between-Bar Skewness (Gold):** Asymmetry of the price
path *between* the intra-bar candles. Indicates if the macro
movements within the bar accelerated in one direction.
- **Within-Bar Skewness (Blue):** Asymmetry of the
microstructure (wicks vs. tails) *inside* the intra-bar candles.
- **Interaction Skewness (Grey):** The component arising from
the comovement of local means and local variances (e.g.,
does volatility increase when price drops?).
2. **Visual Decomposition Logic:** Total Skewness is the
primary metric displayed. Since Skewness coefficients are not
linearly additive, this indicator calculates the *exact* Total
Skewness and partitions the columns based on the additive
Third Moment Decomposition (`M3Tot = M3Btw + M3Wtn + M3Int`).
3. **Dual Display Modes:** The indicator offers two modes to
visualize this information:
- **Absolute Mode:** Plots the *total* skewness as a
stacked column chart, showing the *absolute magnitude* of
asymmetry and the contribution of each component.
- **Relative Mode:** Plots the components as a 100% stacked
column chart (scaled from 0 to 1), focusing purely on the
*energy ratio* of the components.
4. **Calculation Options:**
- **Normalization:** An optional 'Normalize' setting
calculates an **Exponential Regression Curve** (log-space),
making the analysis suitable for comparing assets with
different scales (e.g., BTC vs EURUSD).
- **Volume Weighting:** An option (`Volume weighted`) applies
volume weighting to all mean and moment calculations.
5. **Skewness Cycle Analysis:**
- **Pivot Detection:** Includes a built-in pivot detector
that identifies significant turning points (highs and lows) in
the *total* skewness line. (Note: This is only visible
in 'Absolute Mode').
- **Flexible Pivot Algorithms:** Supports various underlying
mathematical models for pivot detection provided by the
core library.
6. **Note on Confirmation (Lag):** Pivot signals are confirmed
using a lookback method. A pivot is only plotted *after*
the `Pivot Right Bars` input has passed, which introduces
an inherent lag.
7. **Multi-Timeframe (MTF) Capability:**
- **MTF Analysis Lines:** The entire intra-bar analysis can be
run on a higher timeframe (using the `Timeframe` input),
with standard options to handle gaps (`Fill Gaps`) and
prevent repainting (`Wait for...`).
- **Limitation:** The Pivot detection (`Calculate Pivots`) is
**disabled** if a Higher Timeframe (HTF) is selected.
8. **Integrated Alerts:** Includes alerts for:
- Skewness magnitude (High Positive / High Negative).
- Skewness character changes/emerging/fading.
- Total Skewness pivot (High/Low) detection.
**Caution: Real-Time Data Behavior (Intra-Bar Repainting)**
This indicator uses high-resolution intra-bar data. As a result, the
values on the **current, unclosed bar** (the real-time bar) will
update dynamically as new intra-bar data arrives. This behavior is
normal and necessary for this type of analysis. Signals should only
be considered final **after the main chart bar has closed.**
---
**DISCLAIMER**
1. **For Informational/Educational Use Only:** This indicator is
provided for informational and educational purposes only. It does
not constitute financial, investment, or trading advice, nor is
it a recommendation to buy or sell any asset.
2. **Use at Your Own Risk:** All trading decisions you make based on
the information or signals generated by this indicator are made
solely at your own risk.
3. **No Guarantee of Performance:** Past performance is not an
indicator of future results. The author makes no guarantee
regarding the accuracy of the signals or future profitability.
4. **No Liability:** The author shall not be held liable for any
financial losses or damages incurred directly or indirectly from
the use of this indicator.
5. **Signals Are Not Recommendations:** The alerts and visual signals
(e.g., crossovers) generated by this tool are not direct
recommendations to buy or sell. They are technical observations
for your own analysis and consideration.

Volume Weighted LR SkewnessThis indicator analyzes market character by decomposing total
skewness (asymmetry) into four distinct, interpretable components
based on a Linear Regression model.
Key Features:
1. **Four-Component Skewness Decomposition:** The indicator
separates market asymmetry based on the 'Estimate Bar Statistics' option.
It leverages the Law of Total Moments to provide an additive
breakdown of the 3rd Statistical Moment:
- **Trend Skewness (Green/Red):** Asymmetry originating from
the slope of the regression line itself. Indicates if the
trend path is geometrically skewed.
- **Residual Skewness (Yellow):** Asymmetry of the noise
around the regression line. Captures "Tail Risk" (e.g.,
sudden spikes against the trend).
- **Within-Bar Skewness (Blue):** Asymmetry derived from the
microstructure of individual bars (requires 'Estimate Bar Statistics').
- **Interaction Skewness (Dark Grey):** Asymmetry caused by the
correlation between price levels and volatility (e.g.,
volatility expanding as price moves in one direction).
*Dominance of this component indicates an unstable, emotional market.*
2. **Visual Decomposition Logic:** Total Skewness is the
primary metric displayed. Since statistical moments are additive,
this indicator calculates the *exact* Total Skewness and partitions
the area to visualize the contribution (weight) of each
structural source to the overall market bias.
3. **Dual Display Modes:** The indicator offers two modes to
visualize this decomposition:
- **Absolute Mode:** Displays the *total* skewness as a
stacked area chart, allowing to see the magnitude of tail risk.
Stacking logic groups components with the same sign to ensure
visual clarity.
- **Relative Mode:** Displays the direct *contribution ratio*
(proportion) of each component relative to the total sum,
ideal for identifying the dominant driver of asymmetry.
4. **Calculation Options:**
- **Normalization:** An optional 'Normalize' setting
transforms inputs into logarithmic space, analyzing the
skewness of *returns* rather than absolute prices.
- **Volume Weighting:** An option (`Volume weighted`) applies
volume weighting to all regression and moment calculations,
emphasizing high-participation moves.
5. **Skewness Cycle Analysis:**
- **Pivot Detection:** Includes a built-in pivot detector
that identifies significant turning points (peaks/valleys) in
the *total* skewness line. This helps identify extremes in
market sentiment or structural bias.
- **Flexible Pivot Algorithms:** Supports various underlying
mathematical models for pivot detection provided by the
core library.
6. **Note on Confirmation (Lag):** Pivot signals are confirmed
using a lookback method. A pivot is only plotted *after*
the `Pivot Right Bars` input has passed, which introduces
an inherent lag.
7. **Multi-Timeframe (MTF) Capability:**
- **MTF Skewness Lines:** The skewness lines can be
calculated on a higher timeframe, with standard options
to handle gaps (`Fill Gaps`) and prevent repainting
(`Wait for...`).
- **Limitation:** The Pivot detection (`Calculate Pivots`) is
**disabled** if a Higher Timeframe (HTF) is selected.
8. **Integrated Alerts:** Includes comprehensive alerts for:
- Skewness magnitude (High Positive / High Negative).
- Skewness character changes/emerging/fading.
- Total Skewness pivot (High/Low) detection.
---
**DISCLAIMER**
1. **For Informational/Educational Use Only:** This indicator is
provided for informational and educational purposes only. It does
not constitute financial, investment, or trading advice, nor is
it a recommendation to buy or sell any asset.
2. **Use at Your Own Risk:** All trading decisions you make based on
the information or signals generated by this indicator are made
solely at your own risk.
3. **No Guarantee of Performance:** Past performance is not an
indicator of future results. The author makes no guarantee
regarding the accuracy of the signals or future profitability.
4. **No Liability:** The author shall not be held liable for any
financial losses or damages incurred directly or indirectly from
the use of this indicator.
5. **Signals Are Not Recommendations:** The alerts and visual signals
(e.g., crossovers) generated by this tool are not direct
recommendations to buy or sell. They are technical observations
for your own analysis and consideration.

Volume Weighted SkewnessThis indicator analyzes market sentiment by decomposing total
skewness (asymmetry) into two distinct, interpretable components:
"Between-Bar" (Inter-Bar) and "Within-Bar" (Intra-Bar) skewness.
Key Features:
1. **Moment-Based Skewness decomposition:** The indicator
separates skewness based on the 'Estimate Bar Statistics' option.
It leverages the additive property of the Third Central Moment
to ensure mathematical rigor:
- **Standard Mode (`Estimate Bar Statistics` = OFF):** Calculates
simple skewness of the selected `Source`.
- **Decomposition Mode (`Estimate Bar Statistics` = ON):** The
indicator uses a statistical model ('Estimator') to
calculate *within-bar* skewness.
This separates the asymmetry into:
- **Between-Bar Skewness (Gold):** Asymmetry of the price
path itself. A positive value indicates that the trend
moves more aggressively upwards than downwards.
- **Within-Bar Skewness (Blue):** Asymmetry of the
microstructure (wicks vs. tails). A positive value implies
strong buying pressure within the bars (long tails).
2. **Visual Decomposition Logic:** Total Skewness is the
primary metric displayed. Since Skewness coefficients are not
linearly additive, this indicator calculates the *exact* Total
Skewness and partitions the area/ratios based on the additive
Third Moment Decomposition (`M3Tot = M3Btw + M3Wtn`). This
ensures the displayed total skewness remains mathematically accurate.
3. **Dual Display Modes:** The indicator offers two modes to
visualize this decomposition:
- **Absolute Mode:** Displays the *Total Skewness* as the main
line, with the background filled by the stacked components.
Shows the *magnitude* and direction of the tail risk.
- **Relative Mode:** Displays the **Contribution Ratios**
of each component (-1.0 to 1.0). This isolates the
*structure/quality* of the asymmetry (e.g., "Is the skewness
driven by the trend or by the candle shapes?").
4. **Calculation Options:**
- **Normalization:** An optional 'Normalize' setting
transforms inputs into logarithmic space, analyzing the
skewness of *returns* rather than absolute prices.
(Essential for correct statistical properties).
- **Volume Weighting:** An option (`Volume weighted`) applies
volume weighting to all moment calculations, emphasizing
high-participation moves.
5. **Skewness Cycle Analysis:**
- **Pivot Detection:** Includes a built-in pivot detector
that identifies significant turning points (peaks/valleys) in
the *Total Skewness* line. (Note: This is only visible
in 'Absolute Mode').
- **Flexible Pivot Algorithms:** Supports various underlying
mathematical models for pivot detection provided by the
core library.
6. **Note on Confirmation (Lag):** Pivot signals are confirmed
using a lookback method. A pivot is only plotted *after*
the `Pivot Right Bars` input has passed, which introduces
an inherent lag.
7. **Multi-Timeframe (MTF) Capability:**
- **MTF Skewness Lines:** The skewness lines can be
calculated on a higher timeframe, with standard options
to handle gaps (`Fill Gaps`) and prevent repainting
(`Wait for...`).
- **Limitation:** The Pivot detection (`Calculate Pivots`) is
**disabled** if a Higher Timeframe (HTF) is selected.
8. **Integrated Alerts:** Includes comprehensive alerts for:
- Skewness magnitude (High Positive / High Negative).
- Character changes (Inter-Bar vs. Intra-Bar dominance).
- Total Skewness pivot (High/Low) detection.
---
**DISCLAIMER**
1. **For Informational/Educational Use Only:** This indicator is
provided for informational and educational purposes only. It does
not constitute financial, investment, or trading advice, nor is
it a recommendation to buy or sell any asset.
2. **Use at Your Own Risk:** All trading decisions you make based on
the information or signals generated by this indicator are made
solely at your own risk.
3. **No Guarantee of Performance:** Past performance is not an
indicator of future results. The author makes no guarantee
regarding the accuracy of the signals or future profitability.
4. **No Liability:** The author shall not be held liable for any
financial losses or damages incurred directly or indirectly from
the use of this indicator.
5. **Signals Are Not Recommendations:** The alerts and visual signals
(e.g., crossovers) generated by this tool are not direct
recommendations to buy or sell. They are technical observations
for your own analysis and consideration.

Skewness Indicator偏態分佈指標Skewness Indicator
核心功能
偏度計算 - 測量價格分佈的不對稱性
正偏度:價格傾向於右偏,可能表示上漲趨勢
負偏度:價格傾向於左偏,可能表示下跌趨勢
可自定義參數
計算週期(預設20)
數據源(收盤價、開盤價等)
正負偏態閾值
視覺化元素
藍色線:即時偏度值
橙色線:偏度移動平均(平滑訊號)
背景顏色:綠色表示強正偏態,紅色表示強負偏態
信號標記:三角形標示潛在的交易機會
交易信號
看漲信號:當偏度向上突破負閾值
看跌信號:當偏度向下跌破正閾值
資訊面板 - 右上角顯示當前偏度值和狀態
功能
多時間週期(HTF) - 可選擇在更高時間框架上計算偏度(例如在5分鐘圖上顯示日線的偏度)
交易信號 - 三角形標記顯示潛在的交易機會
資訊面板 - 右上角顯示當前偏度值和市場狀態
視覺提示 - 閾值線和背景顏色提示極端狀態
使用建議
在參數中勾選「使用高時間週期」
選擇你想要的時間週期(如 D=日線, W=週線, 240=4小時)
這樣可以在短週期圖表上看到長週期的偏態趨勢
Core functions
Skewness calculation-Measuring the asymmetry of price distribution
Positive bias: The price tends to the right, which may indicate an upward trend
Negative bias: The price tends to the left, which may indicate a downward trend
Customizable parameters
Calculation cycle (default 20)
Data source (closing price, opening price, etc.)
Positive and negative bias threshold
Visual elements
Blue line: instant skewness value
Orange line: skewed moving average (smooth signal)
Background color: green indicates a strong positive bias, red indicates a strong negative bias
Signal mark: Triangle marks potential trading opportunities
Trading signals
Bullish signal: when the skewness breaks through the negative threshold upward
Bearish signal: when the bias falls below the positive threshold
Information panel-the upper right corner displays the current skewness value and status
function
Multi-time period (HTF)-you can choose to calculate the skewness on a higher time frame (for example, display the skewness of the daily line on a 5-minute chart)
Trading signals-Triangle marks show potential trading opportunities
Information panel-the upper right corner displays the current skewness value and market status
Visual cues-threshold lines and background colors indicate extreme states
Recommendations for use
Check "Use high time period" in the parameters
Choose the time period you want (e.g. D= daily, W= weekly, 240= 4 hours)
In this way, you can see the long-cycle bias trend on the short-cycle chart

RSI Distribution [Kodexius]RSI Distribution is a statistics driven visualization companion for the classic RSI oscillator. In addition to plotting RSI itself, it continuously builds a rolling sample of recent RSI values and projects their distribution as a forward drawn histogram, so you can see where RSI has spent most of its time over the selected lookback window.
The indicator is designed to add context to oscillator readings. Instead of only treating RSI as a single point estimate that is either “high” or “low”, you can evaluate the current RSI level relative to its own recent history. This makes it easier to recognize when the market is operating inside a familiar regime, and when RSI is pushing into rarer tail conditions that tend to appear during momentum bursts, exhaustion, or volatility expansion.
To complement the histogram, the script can optionally overlay a Gaussian curve fitted to the sample mean and standard deviation. It also runs a Jarque Bera normality check, based on skewness and excess kurtosis, and surfaces the result both visually and in a compact dashboard. On the oscillator panel itself, RSI is presented with a clean gradient line and standard overbought and oversold references, with fills that become more visible when RSI meaningfully extends beyond key thresholds.
🔹 Features
1. Distribution Histogram of Recent RSI Values
The script stores the last N RSI values in an internal sample and uses that rolling window to compute a frequency distribution across a user selected number of bins. The histogram is drawn into the future by a configurable width in bars, which keeps it readable and prevents it from colliding with the active RSI plot. The result is a compact visual summary of where RSI clusters most often, whether it is spending more time near the center, or shifting toward higher or lower regimes.
2. Gaussian Overlay for Shape Intuition
If enabled, a fitted bell curve is drawn on top of the histogram using the sample mean and standard deviation. This overlay is not intended as a direct trading signal. Its purpose is to provide a fast visual comparator between the empirical RSI distribution and a theoretical normal shape. When the histogram diverges strongly from the curve, you can quickly spot skew, heavy tails, or regime changes that often occur when market structure or volatility conditions shift.
3. Jarque Bera Normality Check With Clear PASS/FAIL Feedback
The script computes skewness and excess kurtosis from the RSI sample, then forms the Jarque Bera statistic and compares it to a fixed 95% critical value. When the distribution is closer to normal under this test, the status is marked as PASS, otherwise it is marked as FAIL. This result is displayed in the dashboard and can also influence the histogram styling, giving immediate feedback about whether the recent RSI behavior resembles a bell shaped distribution or a more distorted, regime driven profile.
Jarque Bera is a goodness of fit test that evaluates whether a dataset looks consistent with a normal distribution by checking two shape properties: skewness (asymmetry) and kurtosis (tail heaviness, expressed here as excess kurtosis where a perfect normal has 0). Under the null hypothesis of normality, skewness should be near 0 and excess kurtosis should be near 0. The test combines deviations in both into a single statistic, which is then compared to a chi square threshold. A PASS in this script means the sample does not show strong evidence against normality at the chosen threshold, while a FAIL means the sample is meaningfully skewed, heavy tailed, or both. In practical trading terms, a FAIL often suggests RSI is behaving in a regime where extremes and asymmetry are more common, which is typical during strong trends, volatility expansions, or one sided market pressure. It is still a statistical diagnostic, not a prediction tool, and results can vary with lookback length and market conditions.
4. Integrated Stats Dashboard
A compact table in the top right summarizes key distribution moments and the normality result: Mean, StdDev, Skewness, Kurtosis, and the JB statistic with PASS/FAIL text. Skewness is color coded by sign to quickly distinguish right skew (more time at higher RSI) versus left skew (more time at lower RSI), which can be helpful when diagnosing trend bias and momentum persistence.
5. RSI Visual Quality and Context Zones
RSI is plotted with a gradient color scheme and standard overbought and oversold reference lines. The overbought and oversold areas are filled with a smart gradient so visual emphasis increases when RSI meaningfully extends beyond the 70 and 30 regions, improving readability without overwhelming the panel.
🔹 Calculations
This section summarizes the main calculations and transformations used internally.
1. RSI Series
RSI is computed from the selected source and length using the standard RSI function:
rsi_val = ta.rsi(rsi_src, rsi_len)
2. Rolling Sample Collection
A float array stores recent RSI values. Each bar appends the newest RSI, and if the array exceeds the configured lookback, the oldest value is removed. Conceptually:
rsi_history.push(rsi_val)
if rsi_history.size() > lookback
rsi_history.shift()
This maintains a fixed size window that represents the most recent RSI behavior.
3. Mean, Variance, and Standard Deviation
The script computes the sample mean across the array. Variance is computed as sample variance using (n - 1) in the denominator, and standard deviation is the square root of that variance. These values serve both the dashboard display and the Gaussian overlay parameters.
4. Skewness and Excess Kurtosis
Skewness is calculated from the standardized third central moment with a small sample correction. Kurtosis is computed as excess kurtosis (kurtosis minus 3), so the normal baseline is 0. These two metrics summarize asymmetry and tail heaviness, which are the core ingredients for the Jarque Bera statistic.
5. Jarque Bera Statistic and Decision Rule
Using skewness S and excess kurtosis K, the Jarque Bera statistic is computed as:
JB = (n / 6.0) * (S^2 + 0.25 * K^2)
Normality is flagged using a fixed critical value:
is_normal = JB < 5.991
This produces a simple PASS/FAIL classification suitable for fast chart interpretation.
6. Histogram Binning and Scaling
The RSI domain is treated as 0 to 100 and divided into a configurable number of bins. Bin size is:
bin_size = 100.0 / bins
Each RSI sample maps to a bin index via floor(rsi / bin_size), with clamping to ensure the index stays within valid bounds. The script counts occurrences per bin, tracks the maximum frequency, and normalizes each bar height by freq/max_freq so the histogram remains visually stable and comparable as the window updates.
7. Gaussian Curve Overlay (Optional)
The Gaussian overlay uses the normal probability density function with mu as the sample mean and sigma as the sample standard deviation:
normal_pdf(x) = (1 / (sigma * sqrt(2*pi))) * exp(-0.5 * ((x - mu)/sigma)^2)
For drawing, the script samples x across the histogram width, evaluates the PDF, and normalizes it relative to its peak so the curve fits within the same visual height scale as the histogram.

N-Degree Moment-Based Adaptive Detection🙏🏻 N-Degree Moment-Based Adaptive Detection (NDMBAD) method is a generalization of MBAD since the horizontal line fit passing through the data's mean can be simply treated as zero-degree polynomial regression. We can extend the MBAD logic to higher-degree polynomial regression.
I don't think I need to talk a lot about the thing there; the logic is really the same as in MBAD, just hit the link above and read if you want. The only difference is now we can gather cumulants not only from the horizontal mean fit (degree = 0) but also from higher-order polynomial regression fit, including linear regression (degree = 1).
Why?
Simply because residuals from the 0-degree model don't contain trend information, and while in some cases that's exactly what you need, in other cases, you want to model your trend explicitly. Imagine your underlying process trends in a steady manner, and you want to control the extreme deviations from the process's core. If you're going to use 0-degree, you'll be treating this beautiful steady trend as a residual itself, which "constantly deviates from the process mean." It doesn't make much sense.
How?
First, if you set the length to 0, you will end up with the function incrementally applied to all your data starting from bar_index 0. This can be called the expanding window mode. That's the functionality I include in all my scripts lately (where it makes sense). As I said in the MBAD description, choosing length is a matter of doing business & applied use of my work, but I think I'm open to talk about it.
I don't see much sense in using degree > 1 though (still in research on it). If you have dem curves, you can use Fourier transform -> spectral filtering / harmonic regression (regression with Fourier terms). The job of a degree > 0 is to model the direction in data, and degree 1 gets it done. In mean reversion strategies, it means that you don't wanna put 0-degree polynomial regression (i.e., the mean) on non-stationary trending data in moving window mode because, this way, your residuals will be contaminated with the trend component.
By the way, you can send thanks to @aaron294c , he said like mane MBAD is dope, and it's gonna really complement his work, so I decided to drop NDMBAD now, gonna be more useful since it covers more types of data.
I wanned to call it N-Order Moment Adaptive Detection because it abbreviates to NOMAD, which sounds cool and suits me well, because when I perform as a fire dancer, nomad style is one of my outfits. Burning Man stuff vibe, you know. But the problem is degree and order really mean two different things in the polynomial context, so gotta stay right & precise—that's the priority.
∞

Moment-Based Adaptive DetectionMBAD (Moment-Based Adaptive Detection) : a method applicable to a wide range of purposes, like outlier or novelty detection, that requires building a sensible interval/set of thresholds. Unlike other methods that are static and rely on optimizations that inevitably lead to underfitting/overfitting, it dynamically adapts to your data distribution without any optimizations, MLE, or stuff, and provides a set of data-driven adaptive thresholds, based on closed-form solution with O(n) algo complexity.
1.5 years ago, when I was still living in Versailles at my friend's house not knowing what was gonna happen in my life tomorrow, I made a damn right decision not to give up on one idea and to actually R&D it and see what’s up. It allowed me to create this one.
The Method Explained
I’ve been wandering about z-values, why exactly 6 sigmas, why 95%? Who decided that? Why would you supersede your opinion on data? Based on what? Your ego?
Then I consciously noticed a couple of things:
1) In control theory & anomaly detection, the popular threshold is 3 sigmas (yet nobody can firmly say why xD). If your data is Laplace, 3 sigmas is not enough; you’re gonna catch too many values, so it needs a higher sigma.
2) Yet strangely, the normal distribution has kurtosis of 3, and 6 for Laplace.
3) Kurtosis is a standardized moment, a moment scaled by stdev, so it means "X amount of something measured in stdevs."
4) You generate synthetic data, you check on real data (market data in my case, I am a quant after all), and you see on both that:
lower extension = mean - standard deviation * kurtosis ≈ data minimum
upper extension = mean + standard deviation * kurtosis ≈ data maximum
Why not simply use max/min?
- Lower info gain: We're not using all info available in all data points to estimate max/min; we just pick the current higher and lower values. Lol, it’s the same as dropping exponential smoothing with alpha = 0 on stationary data & calling it a day.
You can’t update the estimates of min and max when new data arrives containing info about the matter. All you can do is just extend min and max horizontally, so you're not using new info arriving inside new data.
- Mixing order and non-order statistics is a bad idea; we're losing integrity and coherence. That's why I don't like the Hurst exponent btw (and yes, I came up with better metrics of my own).
- Max & min are not even true order statistics, unlike a percentile (finding which requires sorting, which requires multiple passes over your data). To find min or max, you just need to do one traversal over your data. Then with or without any weighting, 100th percentile will equal max. So unlike a weighted percentile, you can’t do weighted max. Then while you can always check max and min of a geometric shape, now try to calculate the 56th percentile of a pentagram hehe.
TL;DR max & min are rather topological characteristics of data, just as the difference between starting and ending points. Not much to do with statistics.
Now the second part of the ballet is to work with data asymmetry:
1) Skewness is also scaled by stdev -> so it must represent a shift from the data midrange measured in stdevs -> given asymmetric data, we can include this info in our models. Unlike kurtosis, skewness has a sign, so we add it to both thresholds:
lower extension = mean - standard deviation * kurtosis + standard deviation * skewness
upper extension = mean + standard deviation * kurtosis + standard deviation * skewness
2) Now our method will work with skewed data as well, omg, ain’t it cool?
3) Hold up, but what about 5th and 6th moments (hyperskewness & hyperkurtosis)? They should represent something meaningful as well.
4) Perhaps if extensions represent current estimated extremums, what goes beyond? Limits, beyond which we expect data not to be able to pass given the current underlying process generating the data?
When you extend this logic to higher-order moments, i.e., hyperskewness & hyperkurtosis (5th and 6th moments), they measure asymmetry and shape of distribution tails, not its core as previous moments -> makes no sense to mix 4th and 3rd moments (skewness and kurtosis) with 5th & 6th, so we get:
lower limit = mean - standard deviation * hyperkurtosis + standard deviation * hyperskewness
upper limit = mean + standard deviation * hyperkurtosis + standard deviation * hyperskewness
While extensions model your data’s natural extremums based on current info residing in the data without relying on order statistics, limits model your data's maximum possible and minimum possible values based on current info residing in your data. If a new data point trespasses limits, it means that a significant change in the data-generating process has happened, for sure, not probably—a confirmed structural break.
And finally we use time and volume weighting to include order & process intensity information in our model.
I can't stress it enough: despite the popularity of these non-weighted methods applied in mainstream open-access time series modeling, it doesn’t make ANY sense to use non-weighted calculations on time series data . Time = sequence, it matters. If you reverse your time series horizontally, your means, percentiles, whatever, will stay the same. Basically, your calculations will give the same results on different data. When you do it, you disregard the order of data that does have order naturally. Does it make any sense to you? It also concerns regressions applied on time series as well, because even despite the slope being opposite on your reversed data, the centroid (through which your regression line always comes through) will be the same. It also might concern Fourier (yes, you can do weighted Fourier) and even MA and AR models—might, because I ain’t researched it extensively yet.
I still can’t believe it’s nowhere online in open access. No chance I’m the first one who got it. It’s literally in front of everyone’s eyes for centuries—why no one tells about it?
How to use
That’s easy: can be applied to any, even non-stationary and/or heteroscedastic time series to automatically detect novelties, outliers, anomalies, structural breaks, etc. In terms of quant trading, you can try using extensions for mean reversion trades and limits for emergency exits, for example. The market-making application is kinda obvious as well.
The only parameter the model has is length, and it should NOT be optimized but picked consciously based on the process/system you’re applying it to and based on the task. However, this part is not about sharing info & an open-access instrument with the world. This is about using dem instruments to do actual business, and we can’t talk about it.
∞

GaussianDistributionLibrary "GaussianDistribution"
This library defines a custom type `distr` representing a Gaussian (or other statistical) distribution.
It provides methods to calculate key statistical moments and scores, including mean, median, mode, standard deviation, variance, skewness, kurtosis, and Z-scores.
This library is useful for analyzing probability distributions in financial data.
Disclaimer:
I am not a mathematician, but I have implemented this library to the best of my understanding and capacity. Please be indulgent as I tried to translate statistical concepts into code as accurately as possible. Feedback, suggestions, and corrections are welcome to improve the reliability and robustness of this library.
mean(source, length)
Calculate the mean (average) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Mean (μ)
stdev(source, length)
Calculate the standard deviation (σ) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Standard deviation (σ)
skewness(source, length, mean, stdev)
Calculate the skewness (γ₁) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Skewness (γ₁)
skewness(source, length)
Overloaded skewness to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Skewness (γ₁)
mode(mean, stdev, skewness)
Estimate mode - Most frequent value in the distribution (approximation based on skewness)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Mode
mode(source, length)
Overloaded mode to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Mode
median(mean, stdev, skewness)
Estimate median - Middle value of the distribution (approximation)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Median
median(source, length)
Overloaded median to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Median
variance(stdev)
Calculate variance (σ²) - Square of the standard deviation
Parameters:
stdev (float) : the standard deviation (σ) of the distribution
@return Variance (σ²)
variance(source, length)
Overloaded variance to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Variance (σ²)
kurtosis(source, length, mean, stdev)
Calculate kurtosis (γ₂) - Degree of "tailedness" in the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Kurtosis (γ₂)
kurtosis(source, length)
Overloaded kurtosis to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Kurtosis (γ₂)
normal_score(source, mean, stdev)
Calculate Z-score (standard score) assuming a normal distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Z-Score
normal_score(source, length)
Overloaded normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
non_normal_score(source, mean, stdev, skewness, kurtosis)
Calculate adjusted Z-score considering skewness and kurtosis
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
kurtosis (float) : the "tailedness" in the distribution
@return Z-Score
non_normal_score(source, length)
Overloaded non_normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
method init(this)
Initialize all statistical fields of the `distr` type
Namespace types: distr
Parameters:
this (distr)
method init(this, source, length)
Overloaded initializer to set source and length
Namespace types: distr
Parameters:
this (distr)
source (float)
length (int)
distr
Custom type to represent a Gaussian distribution
Fields:
source (series float) : Distribution source (typically a price or indicator series)
length (series int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mode (series float) : Most frequent value in the distribution
median (series float) : Middle value separating the greater and lesser halves of the distribution
mean (series float) : μ (1st central moment) - Average of the distribution
stdev (series float) : σ or standard deviation (square root of the variance) - Measure of dispersion
variance (series float) : σ² (2nd central moment) - Squared standard deviation
skewness (series float) : γ₁ (3rd central moment) - Asymmetry of the distribution
kurtosis (series float) : γ₂ (4th central moment) - Degree of "tailedness" relative to a normal distribution
normal_score (series float) : Z-score assuming normal distribution
non_normal_score (series float) : Adjusted Z-score considering skewness and kurtosis
NormalDistributionFunctionsLibrary "NormalDistributionFunctions"
The NormalDistributionFunctions library encompasses a comprehensive suite of statistical tools for financial market analysis. It provides functions to calculate essential statistical measures such as mean, standard deviation, skewness, and kurtosis, alongside advanced functionalities for computing the probability density function (PDF), cumulative distribution function (CDF), Z-score, and confidence intervals. This library is designed to assist in the assessment of market volatility, distribution characteristics of asset returns, and risk management calculations, making it an invaluable resource for traders and financial analysts.
meanAndStdDev(source, length)
Calculates and returns the mean and standard deviation for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
length (int) : int: The lookback period for the calculation.
Returns: Returns an array where the first element is the mean and the second element is the standard deviation of the data series for the given period.
skewness(source, mean, stdDev, length)
Calculates and returns skewness for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns skewness value
kurtosis(source, mean, stdDev, length)
Calculates and returns kurtosis for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns kurtosis value
pdf(x, mean, stdDev)
pdf: Calculates the probability density function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the PDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the probability density function value for x.
cdf(x, mean, stdDev)
cdf: Calculates the cumulative distribution function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the CDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the cumulative distribution function value for x.
confidenceInterval(mean, stdDev, size, confidenceLevel)
Calculates the confidence interval for a data series mean.
Parameters:
mean (float) : float: The mean of the data series.
stdDev (float) : float: The standard deviation of the data series.
size (int) : int: The sample size.
confidenceLevel (float) : float: The confidence level (e.g., 0.95 for 95% confidence).
Returns: Returns the lower and upper bounds of the confidence interval.
Normal Distribution Asymmetry & Volatility ZonesNormal Distribution Asymmetry & Volatility Zones Indicator provides insights into the skewness of a price distribution and identifies potential volatility zones in the market. The indicator calculates the skewness coefficient, indicating the asymmetry of the price distribution, and combines it with a measure of volatility to define buy and sell zones.
The key features of this indicator include :
Skewness Calculation : It calculates the skewness coefficient, a statistical measure that reveals whether the price distribution is skewed to the left (negative skewness) or right (positive skewness).
Volatility Zones : Based on the skewness and a user-defined volatility threshold, the indicator identifies buy and sell zones where potential price movements may occur. Buy zones are marked when skewness is negative and prices are below a volatility threshold. Sell zones are marked when skewness is positive and prices are above the threshold.
Signal Source Selection : Traders can select the source of price data for analysis, allowing flexibility in their trading strategy.
Customizable Parameters : Users can adjust the length of the distribution, the volatility threshold, and other parameters to tailor the indicator to their specific trading preferences and market conditions.
Visual Signals : Buy and sell zones are visually displayed on the chart, making it easy to identify potential trade opportunities.
Background Color : The indicator changes the background color of the chart to highlight significant zones, providing a clear visual cue for traders.
By combining skewness analysis and volatility thresholds, this indicator offers traders a unique perspective on potential market movements, helping them make informed trading decisions. Please note that trading involves risks, and this indicator should be used in conjunction with other analysis and risk management techniques.
Rolling QuartilesThis script will continuously draw a boxplot to represent quartiles associated with data points in the current rolling window.
Description :
A quartile is a statistical term that refers to the division of a dataset based on percentiles.
Q1 : Quartile 1 - 25th percentile
Q2 : Quartile 2 - 50th percentile, as known as the median
Q3 : Quartile 3 - 75th percentile
Other points to note:
Q0: the minimum
Q4: the maximum
Other properties :
- Q1 to Q3: a range is known as the interquartile range ( IQR ). It describes where 50% of data approximately lie.
- Line segments connecting IQR to min and max (Q0→Q1, and Q3→Q4) are known as whiskers . Data lying outside the whiskers are considered as outliers. However, such extreme values will not be found in a rolling window because whenever new datapoints are introduced to the dataset, the oldest values will get dropped out, leaving Q0 and Q4 to always point to the observable min and max values.
Applications :
This script has a feature that allows moving percentiles (moving values of Q1, Q2, and Q3) to be shown. This can be applied for trading in ways such as:
- Q2: as alternative to a SMA that uses the same lookback period. We know that the Mean (SMA) is highly sensitive to extreme values. On the other hand, Median (Q2) is less affected by skewness. Putting it together, if the SMA is significantly lower than Q2, then price is regarded as negatively skewed; prices of a few candles are likely exceptionally lower. Vice versa when price is positively skewed.
- Q1 and Q3: as lower and upper bands. As mentioned above, the IQR covers approximately 50% of data within the rolling window. If price is normally distributed, then Q1 and Q3 bands will overlap a bollinger band configured with +/- 0.67x standard deviations (modifying default: 2) above and below the mean.
- The boxplot, combined with TradingView's builtin bar replay feature, makes a great tool for studies purposes. This helps visualization of price at a chosen instance of time. Speaking of which, it can also be used in conjunction with a fixed volume profile to compare and contrast the effects (in terms of price range) with and without consideration of weights by volume.
Parameters :
- Lookback: The size of the rolling window.
- Offset: Location of boxplot, right hand side relative to recent bar.
- Source data: Data points for observation, default is closing price
- Other options such as color, and whether to show/hide various lines.
MomentsLibrary "Moments"
Based on Moments (Mean,Variance,Skewness,Kurtosis) . Rewritten for Pinescript v5.
logReturns(src) Calculates log returns of a series (e.g log percentage change)
Parameters:
src : Source to use for the returns calculation (e.g. close).
Returns: Log percentage returns of a series
mean(src, length) Calculates the mean of a series using ta.sma
Parameters:
src : Source to use for the mean calculation (e.g. close).
length : Length to use mean calculation (e.g. 14).
Returns: The sma of the source over the length provided.
variance(src, length) Calculates the variance of a series
Parameters:
src : Source to use for the variance calculation (e.g. close).
length : Length to use for the variance calculation (e.g. 14).
Returns: The variance of the source over the length provided.
standardDeviation(src, length) Calculates the standard deviation of a series
Parameters:
src : Source to use for the standard deviation calculation (e.g. close).
length : Length to use for the standard deviation calculation (e.g. 14).
Returns: The standard deviation of the source over the length provided.
skewness(src, length) Calculates the skewness of a series
Parameters:
src : Source to use for the skewness calculation (e.g. close).
length : Length to use for the skewness calculation (e.g. 14).
Returns: The skewness of the source over the length provided.
kurtosis(src, length) Calculates the kurtosis of a series
Parameters:
src : Source to use for the kurtosis calculation (e.g. close).
length : Length to use for the kurtosis calculation (e.g. 14).
Returns: The kurtosis of the source over the length provided.
skewnessStandardError(sampleSize) Estimates the standard error of skewness based on sample size
Parameters:
sampleSize : The number of samples used for calculating standard error.
Returns: The standard error estimate for skewness based on the sample size provided.
kurtosisStandardError(sampleSize) Estimates the standard error of kurtosis based on sample size
Parameters:
sampleSize : The number of samples used for calculating standard error.
Returns: The standard error estimate for kurtosis based on the sample size provided.
skewnessCriticalValue(sampleSize) Estimates the critical value of skewness based on sample size
Parameters:
sampleSize : The number of samples used for calculating critical value.
Returns: The critical value estimate for skewness based on the sample size provided.
kurtosisCriticalValue(sampleSize) Estimates the critical value of kurtosis based on sample size
Parameters:
sampleSize : The number of samples used for calculating critical value.
Returns: The critical value estimate for kurtosis based on the sample size provided.

ArrayStatisticsLibrary "ArrayStatistics"
Statistic Functions using arrays.
rms(sample) Root Mean Squared
Parameters:
sample : float array, data sample points.
Returns: float
skewness_pearson1(sample) Pearson's 1st Coefficient of Skewness.
Parameters:
sample : float array, data sample.
Returns: float
skewness_pearson2(sample) Pearson's 2nd Coefficient of Skewness.
Parameters:
sample : float array, data sample.
Returns: float
pearsonr(sample_a, sample_b) Pearson correlation coefficient measures the linear relationship between two datasets.
Parameters:
sample_a : float array, sample with data.
sample_b : float array, sample with data.
Returns: float p
kurtosis(sample) Kurtosis of distribution.
Parameters:
sample : float array, data sample.
Returns: float
range_int(sample, percent) Get range around median containing specified percentage of values.
Parameters:
sample : int array, Histogram array.
percent : float, Values percentage around median.
Returns: tuple with , Returns the range which containes specifies percentage of values.

Expected Range and SkewThis is an open source and updated version of my previous "Confidence Interval" script. This script provides you with the expected range over a given time period in the future and the skew of that range. For example, if you wanted to know the expected 1 standard deviation range of MSFT over the next 20 days, this will tell you that. Additionally, this script will also tell you the skew of the expected range.
How to use this script:
1) Enter the length, this will determine the number of data points used in the calculation of the expected range.
2) Enter the amount of time you want projected forward in minutes, hours, and days.
3) Input standard deviation of the expected range.
4) Pick the type of data you want shown from the dropdown menu. Your choices are either the expected range or the skew of the expected range.
5) Enter the x and y coordinates of the label (optional). This is useful so it doesn't impede your view of the plot.
Here are a few notes about this script:
First, the expected range line gives you the width of said range (upper bound - lower bound), and the label will tell you specifically what the upper and lower bounds of the expected range are.
Second, this script will work on any of the default timeframes, but you need to be careful with how far out you try to project the expected range depending on the timeframe you're using. For example, if you're using the 1min timeframe, it probably won't do you any good trying to project the expected range over the next 20 days; or if you're using the daily timeframe it doesn't make sense to try to project the expected range for the next 5 hours. You can tell if the time horizon you're trying to project doesn't work well with the chart timeframe you're using if the current price is outside of either the upper or lower bounds provided in the label. If the current price is within the upper and lower bounds provided in the label, then the time horizon that you're projecting over is reasonable for the chart timeframe you're using.
Third, this script does not countdown automatically, so the time provided in the label will stay the same. For example, in the picture above, the expected range of Dow Futures over the next 23 days from January 12th, 2021 is calculated. But when tomorrow comes it won't count down to 22 days, instead it will show the range over the next 23 days from January 13th, 2021. So if you want the time horizon to change as time goes on you will have to update this yourself manually.
Lastly, if you try to set an alert on this script, you will get a warning about it possibly repainting. This is because of the label, not the plot itself. The label constantly updates itself, which triggers the warning. I tested setting alerts on this script both with and without the inclusion of the label, and without the label the repainting warning did not occur. So remember, if you set an alert on this script you will get a warning about it possibly repainting, but this is because of the label constantly updating, not the plot itself.
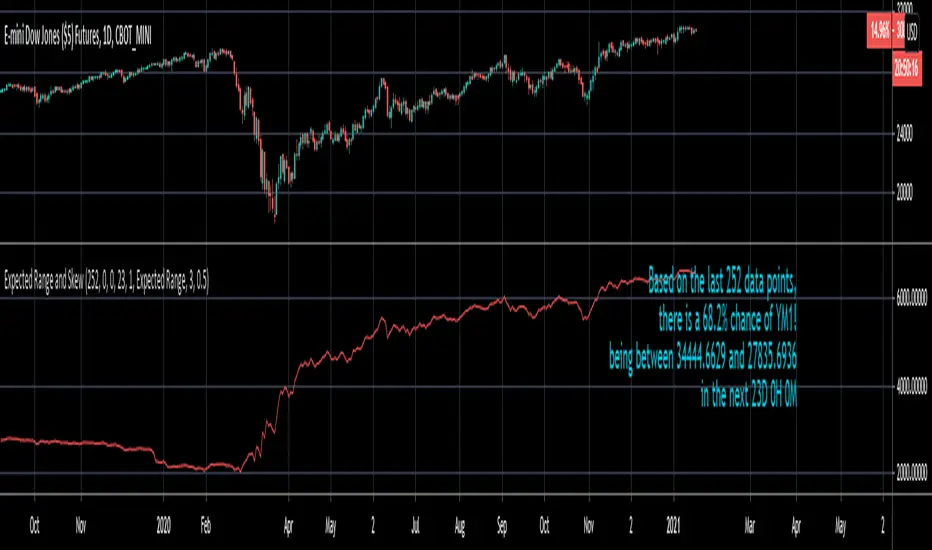
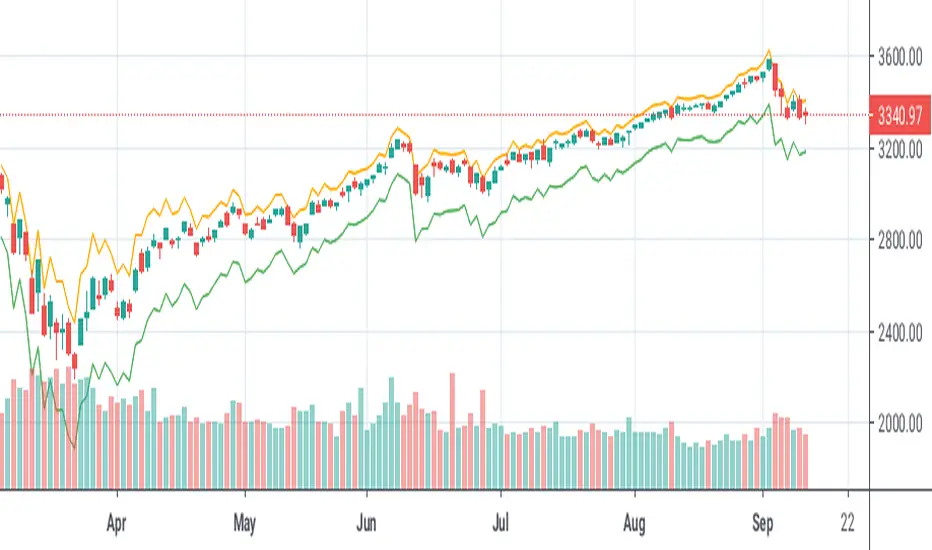
Risk RangeThis indicator creates risk ranges using implied volatility (VIX) or historical volatility, skewness ( Cboe SKEW or estimate ) and kurtosis.
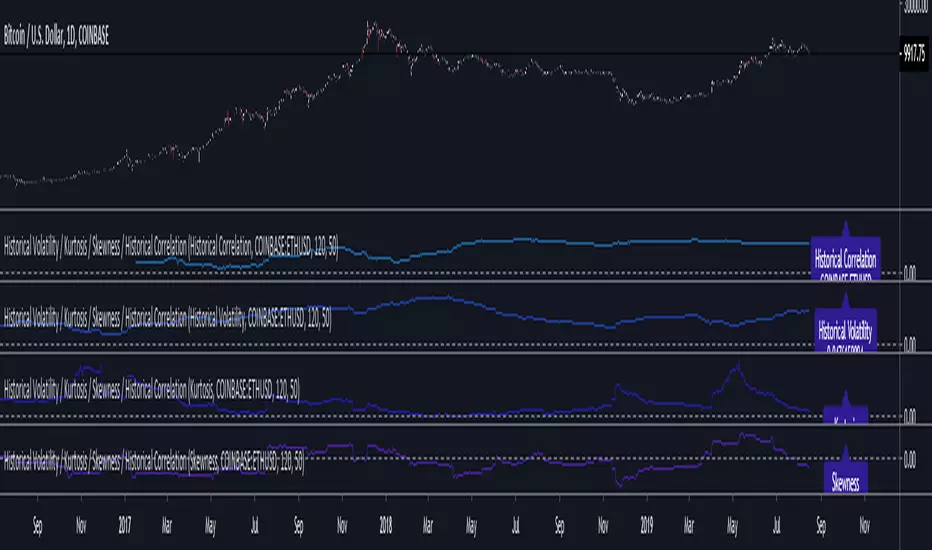
Volatility / Kurtosis / Skewness / CorrelationCalculations for Historical Volatility, Kurtosis, Skewness and Historical Correlation between two assets.
--------------------------------------
If you find it useful please consider a tip/donation :
BTC - 3BMEXEDyWJ58eXUEALYPadbn1wwWKmf6sA
--------------------------------------
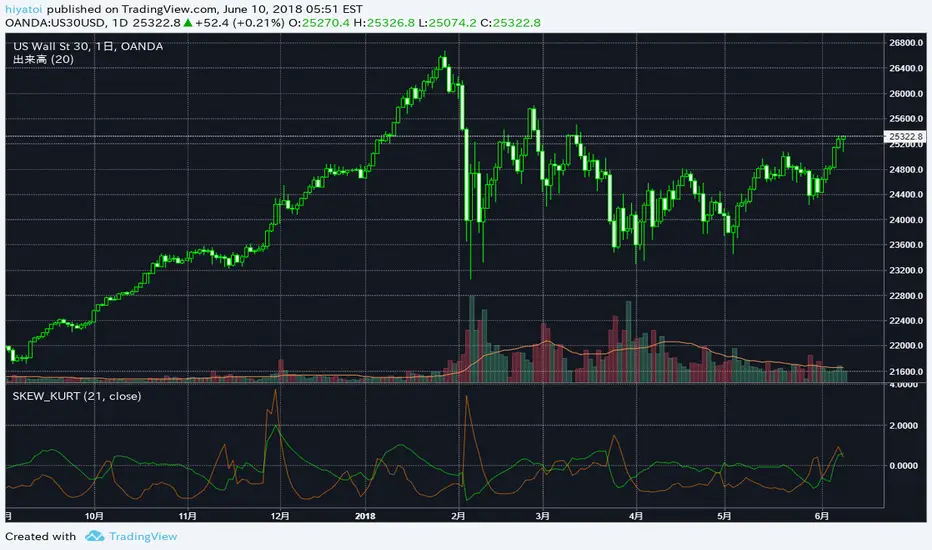
Rolling Skew (Returns) - Beasley SavageSkewness is a term in statistics used to describe asymmetry from the normal distribution in a set of statistical data. Skewness can come in the form of negative skewness or positive skewness, depending on whether data points are skewed to the left and negative, or to the right and positive of the data average. A dataset that shows this characteristic differs from a normal bell curve.
