OrdinaryLeastSquaresLibrary "OrdinaryLeastSquares"
One of the most common ways to estimate the coefficients for a linear regression is to use the Ordinary Least Squares (OLS) method.
This library implements OLS in pine. This implementation can be used to fit a linear regression of multiple independent variables onto one dependent variable,
as long as the assumptions behind OLS hold.
solve_xtx_inv(x, y) Solve a linear system of equations using the Ordinary Least Squares method.
This function returns both the estimated OLS solution and a matrix that essentially measures the model stability (linear dependence between the columns of 'x').
NOTE: The latter is an intermediate step when estimating the OLS solution but is useful when calculating the covariance matrix and is returned here to save computation time
so that this step doesn't have to be calculated again when things like standard errors should be calculated.
Parameters:
x : The matrix containing the independent variables. Each column is regarded by the algorithm as one independent variable. The row count of 'x' and 'y' must match.
y : The matrix containing the dependent variable. This matrix can only contain one dependent variable and can therefore only contain one column. The row count of 'x' and 'y' must match.
Returns: Returns both the estimated OLS solution and a matrix that essentially measures the model stability (xtx_inv is equal to (X'X)^-1).
solve(x, y) Solve a linear system of equations using the Ordinary Least Squares method.
Parameters:
x : The matrix containing the independent variables. Each column is regarded by the algorithm as one independent variable. The row count of 'x' and 'y' must match.
y : The matrix containing the dependent variable. This matrix can only contain one dependent variable and can therefore only contain one column. The row count of 'x' and 'y' must match.
Returns: Returns the estimated OLS solution.
standard_errors(x, y, beta_hat, xtx_inv) Calculate the standard errors.
Parameters:
x : The matrix containing the independent variables. Each column is regarded by the algorithm as one independent variable. The row count of 'x' and 'y' must match.
y : The matrix containing the dependent variable. This matrix can only contain one dependent variable and can therefore only contain one column. The row count of 'x' and 'y' must match.
beta_hat : The Ordinary Least Squares (OLS) solution provided by solve_xtx_inv() or solve().
xtx_inv : This is (X'X)^-1, which means we take the transpose of the X matrix, multiply that the X matrix and then take the inverse of the result.
This essentially measures the linear dependence between the columns of the X matrix.
Returns: The standard errors.
estimate(x, beta_hat) Estimate the next step of a linear model.
Parameters:
x : The matrix containing the independent variables. Each column is regarded by the algorithm as one independent variable. The row count of 'x' and 'y' must match.
beta_hat : The Ordinary Least Squares (OLS) solution provided by solve_xtx_inv() or solve().
Returns: Returns the new estimate of Y based on the linear model.
"one一季度财报" için komut dosyalarını ara
Delta Volume Candles [LucF]█ OVERVIEW
This indicator plots on-chart volume delta information using candles that can replace your normal candles, tops and bottoms appended to normal candles, optional MAs of those tops and bottoms levels, a divergence channel and a chart background. The indicator calculates volume delta using intrabar analysis, meaning that it uses the lower timeframe bars constituting each chart bar.
█ CONCEPTS
Volume Delta
The volume delta concept divides a bar's volume in "up" and "down" volumes. The delta is calculated by subtracting down volume from up volume. Many calculation techniques exist to isolate up and down volume within a bar. The simplest use the polarity of interbar price changes to assign their volume to up or down slots, e.g., On Balance Volume or the Klinger Oscillator . Others such as Chaikin Money Flow use assumptions based on a bar's OHLC values. The most precise calculation method uses tick data and assigns the volume of each tick to the up or down slot depending on whether the transaction occurs at the bid or ask price. While this technique is ideal, it requires huge amounts of data on historical bars, which considerably limits the historical depth of charts and the number of symbols for which tick data is available. Furthermore, historical tick data is not yet available on TradingView.
This indicator uses intrabar analysis to achieve a compromise between the simplest and most precise methods of calculating volume delta. It is currently the most precise method usable on TradingView charts. TradingView's Volume Profile built-in indicators use it, as do the CVD - Cumulative Volume Delta Candles and CVD - Cumulative Volume Delta (Chart) indicators published from the TradingView account . My Delta Volume Channels and Volume Delta Columns Pro indicators also use intrabar analysis. Other volume delta indicators such as my Realtime 5D Profile use realtime chart updates to calculate volume delta without intrabar analysis, but that type of indicator only works in real time; they cannot calculate on historical bars.
This is the logic I use to determine the polarity of intrabars, which determines the up or down slot where its volume is added:
• If the intrabar's open and close values are different, their relative position is used.
• If the intrabar's open and close values are the same, the difference between the intrabar's close and the previous intrabar's close is used.
• As a last resort, when there is no movement during an intrabar, and it closes at the same price as the previous intrabar, the last known polarity is used.
Once all intrabars making up a chart bar have been analyzed and the up or down property of each intrabar's volume determined, the up volumes are added, and the down volumes subtracted. The resulting value is volume delta for that chart bar, which can be used as an estimate of the buying/selling pressure on an instrument. Not all markets have volume information. Without it, this indicator is useless.
Intrabar analysis
Intrabars are chart bars at a lower timeframe than the chart's. The timeframe used to access intrabars determines the number of intrabars accessible for each chart bar. On a 1H chart, each chart bar of an active market will, for example, usually contain 60 bars at the lower timeframe of 1min, provided there was market activity during each minute of the hour.
This indicator automatically calculates an appropriate lower timeframe using the chart's timeframe and the settings you use in the script's "Intrabars" section of the inputs. As it can access lower timeframes as small as seconds when available, the indicator can be used on charts at relatively small timeframes such as 1min, provided the market is active enough to produce bars at second timeframes.
The quantity of intrabars analyzed in each chart bar determines:
• The precision of calculations (more intrabars yield more precise results).
• The chart coverage of calculations (there is a 100K limit to the quantity of intrabars that can be analyzed on any chart,
so the more intrabars you analyze per chart bar, the less chart bars can be calculated by the indicator).
The information box displayed at the bottom right of the chart shows the lower timeframe used for intrabars, as well as the average number of intrabars detected for chart bars and statistics on chart coverage.
Balances
This indicator calculates five balances from volume delta values. The balances are oscillators with a zero centerline; positive values are bullish, and negative values are bearish. It is important to understand the balances as they can be used to:
• Color candle bodies.
• Calculate body and top and bottom divergences.
• Color an EMA channel.
• Color the chart's background.
• Configure markers and alerts.
The five balances are:
1 — Bar Balance : This is the only balance using instant values; it is simply the subtraction of the down volume from the up volume on the bar, so the instant volume delta for that bar.
2 — Average Balance : Calculates a distinct EMA for both the up and down volumes, and subtracts the down EMA from the up EMA.
The result is akin to MACD's histogram because it is the subtraction of two moving averages.
3 — Momentum Balance : Starts by calculating, separately for both up and down volumes, the difference between the same EMAs used in "Average Balance" and
an SMA of twice the period used for the "Average Balance" EMAs. The difference for the up side is subtracted from the difference for the down side,
and an RSI of that value is calculated and brought over the −50/+50 scale.
4 — Relative Balance : The reference values used in the calculation are the up and down EMAs used in the "Average Balance".
From those, we calculate two intermediate values using how much the instant up and down volumes on the bar exceed their respective EMA — but with a twist.
If the bar's up volume does not exceed the EMA of up volume, a zero value is used. The same goes for the down volume with the EMA of down volume.
Once we have our two intermediate values for the up and down volumes exceeding their respective MA, we subtract them. The final value is an ALMA of that subtraction.
The rationale behind using zero values when the bar's up/down volume does not exceed its EMA is to only take into account the more significant volume.
If both instant volume values exceed their MA, then the difference between the two is the signal's value.
The signal is called "relative" because the intermediate values are the difference between the instant up/down volumes and their respective MA.
This balance flatlines when the bar's up/down volumes do not exceed their EMAs, which makes it useful to spot areas where trader interest dwindles, such as consolidations.
The smaller the period of the final value's ALMA, the more easily it will flatline. These flat zones should be considered no-trade zones.
5 — Percent Balance : This balance is the ALMA of the ratio of the "Bar Balance" over the total volume for that bar.
From the balances and marker conditions, two more values are calculated:
1 — Marker Bias : This sums the up/down (+1/‒1) occurrences of the markers 1 to 4 over a period you define, so it ranges from −4 to +4, times the period.
Its calculation will depend on the modes used to calculate markers 3 and 4.
2 — Combined Balances : This is the sum of the bull/bear (+1/−1) states of each of the five balances, so it ranges from −5 to +5.
The periods for all of these balances can be configured in the "Periods" section at the bottom of the script's inputs. As you cannot see the balances on the chart, you can use my Volume Delta Columns Pro indicator in a pane; it can plot the same balances, so you will be able to analyze them.
Divergences
In the context of this indicator, a divergence is any bar where the bear/bull state of a balance (above/below its zero centerline) diverges from the polarity of a chart bar. No directional bias is assigned to divergences when they occur. Candle bodies and tops/bottoms can each be colored differently on divergences detected from distinct balances.
Divergence Channel
The divergence channel is the space between two levels (by default, the bar's open and close ) saved when divergences occur. When price (by default the close ) has breached a channel and a new divergence occurs, a new channel is created. Until that new channel is breached, bars where additional divergences occur will expand the channel's levels if the bar's price points are outside the channel.
Prices breaches of the divergence channel will change its state. Divergence channels can be in one of three different states:
• Bull (green): Price has breached the channel to the upside.
• Bear (red): Price has breached the channel to the downside.
• Neutral (gray): The channel has not yet been breached.
█ HOW TO USE THE INDICATOR
I do not make videos to explain how to use my indicators. I do, however, try hard to include in their description everything one needs to understand what they do. From there, it's up to you to explore and figure out if they can be useful in your trading practice. Communicating in videos what this description and the script's tooltips contain would make for very long videos that would likely exceed the attention span of most people who find this description too long. There is no quick way to understand an indicator such as this one because it uses many different concepts and has quite a bit of settings one can use to modify its visuals and behavior — thus how one uses it. I will happily answer questions on the inner workings of the indicator, but I do not answer questions like "How do I trade using this indicator?" A useful answer to that question would require an in-depth analysis of who you are, your trading methodology and objectives, which I do not have time for. I do not teach trading.
Start by loading the indicator on an active chart containing volume information. See here if you need help.
The default configuration displays:
• Normal candles where the bodies are only colored if the bar's volume has increased since the last bar.
If you want to use this indicator's candles, you may want to disable your chart's candles by clicking the eye icon to the right of the symbol's name in the top left of the chart.
• A top or bottom appended to the normal candles. It represents the difference between up and down volume for that bar
and is positioned at the top or bottom, depending on its polarity. If up volume is greater than down volume, a top is displayed. If down volume is greater, a bottom is plotted.
The size of tops and bottoms is determined by calculating a factor which is the proportion of volume delta over the bar's total volume.
That factor is then used to calculate the top or bottom size relative to a baseline of the average candle body size of the last 100 bars.
• An information box in the bottom right displaying intrabar and chart coverage information.
• A light red background when the intrabar volume differs from the chart's volume by more than 1%.
The script's inputs contain tooltips explaining most of the fields. I will not repeat them here. Following is a brief description of each section of the indicator's inputs which will give you an idea of what the indicator can do:
Normal Candles is where you configure the replacement candles plotted by the script. You can choose from different coloring schemes for their bodies and specify a unique color for bodies where a divergence calculated using the method you choose occurs.
Volume Tops & Botttoms is where you configure the display of tops and bottoms, and their EMAs. The EMAs are calculated from the high point of tops and the low point of bottoms. They can act as a channel to evaluate price, and you can choose to color the channel using a gradient reflecting the advances/declines in the balance of your choice.
Divergence Channel is where you set up the appearance and behavior of the divergence channel. These areas represent levels where price and volume delta information do not converge. They can be interpreted as regions with no clear direction from where one will look for breaches. You can configure the channel to take into account one or both types of divergences you have configured for candle bodies and tops/bottoms.
Background allows you to configure a gradient background color that reflects the advances/declines in the balance of your choice. You can use this to provide context to the volume delta values from bars. You can also control the background color displayed on volume discrepancies between the intrabar and the chart's timeframe.
Intrabars is where you choose the calculation mode determining the lower timeframe used to access intrabars. The indicator uses the chart's timeframe and the type of market you are on to calculate the lower timeframe. Your setting there should reflect which compromise you prefer between the precision of calculations and chart coverage. This is also where you control the display of the information box in the lower right corner of the chart.
Markers allows you to control the plotting of chart markers on different conditions. Their configuration determines when alerts generated from the indicator will fire. Note that in order to generate alerts from this script, they must be created from your chart. See this Help Center page to learn how. Only the last 500 markers will be visible on the chart, but this will not affect the generation of alerts.
Periods is where you configure the periods for the balances and the EMAs used in the indicator.
The raw values calculated by this script can be inspected using the Data Window.
█ INTERPRETATION
Rightly or wrongly, volume delta is considered by many a useful complement to the interpretation of price action. I use it extensively in an attempt to find convergence between my read of volume delta and price movement — not so much as a predictor of future price movement. No system or person can predict the future. Accordingly, I consider people who speak or act as if they know the future with certainty to be dangerous to themselves and others; they are charlatans, imprudent or blissfully ignorant.
I try to avoid elaborate volume delta interpretation schemes involving too many variables and prefer to keep things simple:
• Trends that have more chances of continuing should be accompanied by VD of the same polarity.
In trends, I am looking for "slow and steady". I work from the assumption that traders and systems often overreact, which translates into unproductive volatility.
Wild trends are more susceptible to overreactions.
• I prefer steady VD values over wildly increasing ones, as large VD increases often come with increased price volatility, which can backfire.
Large VD values caused by stopping volume will also often occur on trend reversals with abnormally high candles.
• Prices escaping divergence channels may be leading a trend in that direction, although there is no telling how long that trend will last; could be just a few bars or hundreds.
When price is in a channel, shifts in VD balances can sometimes give us an idea of the direction where price has the most chance of breaking.
• Dwindling VD will often indicate trend exhaustion and predate reversals by many bars, but the problem is that mere pauses in a trend will often produce the same behavior in VD.
I think it is too perilous to infer rigidly from VD decreases.
Divergence Channel
Here I have configured the divergence channels to be visible. First, I set the bodies to display divergences on the default Bar Balance. They are indicated by yellow bodies. Then I activated the divergence channels by choosing to draw levels on body divergences and checked the "Fill" checkbox to fill the channel with the same color as the levels. The divergence channel is best understood as a direction-less area from where a breach can be acted on if other variables converge with the breach's direction:
Tops and Bottoms EMAs
I find these EMAs rather interesting. They have no equivalent elsewhere, as they are calculated from the top and bottom values this indicator plots. The only similarity they have with volume-weighted MAs, including VWAP, is that they use price and volume. This indicator's Tops and Bottoms EMAs, however, use the price and volume delta. While the channel differs from other channels in how it is calculated, it can be used like others, as a baseline from which to evaluate price movement or, alternatively, as stop levels. Remember that you can change the period used for the EMAs in the "Periods" section of the inputs.
This chart shows the EMAs in action, filled with a gradient representing the advances/decline from the Momentum balance. Notice the anomaly in the chart's latest bars where the Momentum balance gradient has been indicating a bullish bias for some time, during which price was mostly below the EMAs. Price has just broken above the channel on positive VD. My interpretation of this situation would be that it is a risky opportunity for a long trade in the larger context where the market has been in a downtrend since the 5th. Intrepid traders choosing to enter here could do so with a "make or break" tight stop that will minimize their losses should the market continue its downtrend while hopefully preserving the potential upside of price continuing on the longer-term uptrend prevalent since the 28th:
█ NOTES
Volume
If you use indicators such as this one which depends on volume information, it is important to realize that the volume data they consume comes from data feeds, and that all data feeds are NOT created equally. Those who create the data feeds we use must make decisions concerning the nature of the transactions they tally and the way they are tallied in each feed, and these decisions affect the nature of our volume data. My Volume X-ray publication discusses some of the reasons why volume information from different timeframes, brokers/exchanges or sectors may vary considerably. I encourage you to read it. This indicator's display of a warning through a background color on volume discrepancies between the timeframe used to access intrabars and the chart's timeframe is an attempt to help you realize these variations in feeds. Don't take things for granted, and understand that the quality of a given feed's volume information affects the quality of the results this indicator calculates.
Markets as ecosystems
I believe it is perilous to think that behavioral patterns you discover in one market through the lens of this or any other indicator will necessarily port to other markets. While this may sometimes be the case, it will often not. Why is that? Because each market is its own ecosystem. As cities do, all markets share some common characteristics, but they also all have their idiosyncrasies. A proportion of a city's inhabitants is always composed of outsiders who come and go, but a core population of regulars and systems is usually the force that actually defines most of the city's observable characteristics. I believe markets work somewhat the same way; they may look the same, but if you live there for a while and pay attention, you will notice the idiosyncrasies. Some things that work in some markets will, accordingly, not work in others. Please keep that in mind when you draw conclusions.
On Up/Down or Buy/Sell Volume
Buying or selling volume are misnomers, as every unit of volume transacted is both bought and sold by two different traders. While this does not keep me from using the terms, there is no such thing as “buy only” or “sell only” volume. Trader lingo is riddled with peculiarities. Without access to order book information, traders work with the assumption that when price moves up during a bar, there was more buying pressure than selling pressure, just as when buy market orders take out limit ask orders in the order book at successively higher levels. The built-in volume indicator available on TradingView uses this logic to color the volume columns green or red. While this script’s calculations are more precise because it analyses intrabars to calculate its information, it uses pretty much the same imperfect logic. Until Pine scripts can have access to how much volume was transacted at the bid/ask prices, our volume delta calculations will remain a mere proxy.
Repainting
• The values calculated on the realtime bar will update as new information comes from the feed.
• Historical values may recalculate if the historical feed is updated or when calculations start from a new point in history.
• Markers and alerts will not repaint as they only occur on a bar's close. Keep this in mind when viewing markers on historical bars,
where one could understandably and incorrectly assume they appear at the bar's open.
To learn more about repainting, see the Pine Script™ User Manual's page on the subject .
Superfluity
In "The Bed of Procrustes", Nassim Nicholas Taleb writes: To bankrupt a fool, give him information . This indicator can display a lot of information. The inevitable adaptation period you will need to figure out how to use it should help you eliminate all the visuals you do not need. The more you eliminate, the easier it will be to focus on those that are the most useful to your trading practice. Don't be a fool.
█ THANKS
Thanks to alexgrover for his Dekidaka-Ashi indicator. His volume plots on candles were the inspiration for my top/bottom plots.
Kudos to PineCoders for their libraries. I use two of them in this script: Time and lower_tf .
The first versions of this script used functionality that I would not have known about were it not for these two guys:
— A guy called Kuan who commented on a Backtest Rookies presentation of their Volume Profile indicator.
— theheirophant , my partner in the exploration of the sometimes weird abysses of request.security() ’s behavior at lower timeframes.

Custom Buy/Sell Pattern BuilderAre you tired of using trading indicators that only let you follow fixed, pre-designed rules? Do you wish you could build your own “Buy” or “Sell” signals, experiment with your own ideas, or see instantly if your unique pattern works—without learning coding or hiring a developer?
The Custom Buy/Sell Pattern Builder is designed for YOU.
This TradingView indicator lets ANY trader—even a complete beginner—define exactly what kind of price and volume conditions should create a BUY or SELL label on any chart, in any market, at any timeframe.
You don’t need to know programming. You don’t need to know the definition of a hammer, doji, volume spike, or Engulfing pattern.
With a few clicks and easy dropdown choices, you can:
Make your own rules for buying or selling
Choose how many candles your pattern should look at
Decide if you want the biggest body, the lowest volume, the biggest movement, or any combination you can imagine
The result?
You’ll see clear “BUY” or “SELL” labels automatically show up on your chart whenever the exact rule YOU built matches current price action.
No more guessing. No more forced strategies. Just pure control and visual feedback!
Why Is This Powerful?
Traditional indicators (like MACD, RSI, or even classic candlestick scanners) work the same for everyone—and only as their inventors defined.
But every trader, and every market, is unique.
What if you could say:
“Show me a ‘SELL’ every time the newest candle is bigger than the one before, but with LESS volume, while the bar before that had an even smaller body—but more volume than all others?”
With this tool, it’s EASY!
You simply pick which candle you want to compare (most recent, previous, etc), what to compare (body or volume—body means the candle’s “thickness”, from open to close), choose “greater than”, “less than”, or “equal to”, and set a multiplier if you want (like “half as much”, “twice as big”, etc).
After this, if any bar on the chart fits all your rules, it will mark it as a BUY or SELL, depending on your selection.
This means—
Beginners can start experimenting with their intuition or small ideas, without tech hurdles
Experienced traders can visualize and fine-tune any possible logic, before they commit to backtesting or automating a real strategy
Every “what if” or “I wonder” setup is just 2–3 clicks away
How Does It Work? Simple Steps
1. Choose Your Signal Type
“Buy” or “Sell”
This tells the indicator whether to mark the qualifying bars with a green “BUY” or red “SELL” label
2. Pick How Many Candles To Use
“Pattern Candle Count” input (2, 3, or 4)
Example: If you use 4, the pattern will be applied to the most recent 4 candles at every step
3. Define Your Pattern With Inputs
For each candle (from newest “0” to oldest “3”), you can set:
Body Condition (example: “is this candle’s body bigger/smaller/equal to another?”)
Pick which candle to compare against
Pick “>”, “<”, “>=”, “<=”, or “=”
Set a multiplier if needed (like “0.5” to mean “half as big as” or “2” for “twice as big as”)
Volume Condition (exact same choices, but based on trading volume—not the candle’s price body)
For example:
“Candle0 Body > Candle2 Body”
means “the latest candle’s real-body (open–close) is bigger than the one two bars ago.”
“Candle1 Volume <= Candle2 Volume”
means “the previous candle’s volume is less than or equal to the volume of the bar two periods ago.”
You can leave a comparison blank if you don’t want to use it for a particular candle.
What Happens After You Set Your Rules?
Every bar on your chart is checked for your logic:
If ALL body AND volume conditions are true (for each candle you specified),
AND
The signal side (“Buy” or “Sell”) matches your dropdown,
Then a green “BUY” or red “SELL” label will show right on the bar, so you can visually spot exactly where your logic works!
Practical Example:
Suppose you want an entry setup that is:
“Sell whenever the newest candle’s body is bigger than two bars ago, body before that is bigger than three bars ago, AND the newest candle’s volume is less than or equal to two bars ago, AND the candle three bars ago’s volume is less than or equal to half the candle two bars ago’s volume.”
You’d set:
Pattern Candle Count: 4
Side: Sell
Candle0 Body Ref#: 2, Op: >, Mult: 1
Candle1 Body Ref#: 3, Op: >, Mult: 1
Candle0 Vol Ref#: 2, Op: <=, Mult: 1
Candle3 Vol Ref#: 2, Op: <=, Mult: 0.5
And the script will find all “SELL” bars on your chart matching these conditions.
Inputs Section: What Does Each Setting Do?
Let’s break down each input in the indicator’s Settings one by one, so even if you’re new, you’ll understand exactly how to use it!
1. Pattern Candle Count (2–4)
What is it?
This sets how many candles in a row you want your rule to look at.
Example:
“4” means your rules are based on the most recent candle and the 3 before it.
“2” means you are only comparing the current and previous candles.
Tip:
Beginners often use 4 to spot stronger patterns, but you can experiment!
2. Signal Side
What is it?
Choose “Buy” or “Sell”. The word you pick here decides which colored label (green for Buy, red for Sell) appears if your pattern matches.
Example:
Want to spot where “Sell” is likely? Pick “Sell”.
Change to “Buy” if you want bullish signals instead.
3. Body & Volume Comparison Settings (per Candle)
For each candle (#0 is newest/current, #3 is oldest in your pattern window):
Body Comparison
Candle# Body Ref#
Choose which other candle you want to compare this one’s body to.
“0” = newest, “1” = previous, “2” = two bars ago, “3” = three bars ago
Candle# Body Op (Operator; >, <, >=, <=, =)
How do you want to compare?
“>” means “greater than” (is bigger than)
“<” means “less than” (is smaller than)
“=” means “equal to”
Candle# Body Mult (Multiplier)
If you want relative comparisons. For example, with Mult=1:
“Candle0 body > Candle2 body x 1” means just “0 is larger than 2.”
“Candle0 body > Candle2 body x 2” means “0 is more than double 2.”
Volume Comparison
Candle# Vol Ref# / Op / Mult
Exact same logic as body, but works on the “Volume” of each candle (how much was traded during that bar).
How to Set Up a Rule (Step by Step Example)
Say you want to mark a Sell every time:
The most recent candle’s real body is BIGGER than the candle 2 bars ago;
The previous candle’s body is also BIGGER than the candle 3 bars ago;
The current candle’s volume is LESS than or equal to the volume of candle 2;
The previous candle’s volume is LESS than or equal to candle 2’s volume;
The candle 3 bars ago’s volume is LESS than or equal to HALF candle 2’s volume.
You’d set:
Pattern Candle Count: 4
Side: "Sell"
Candle0 Body Ref#: 2, Op: “>”, Mult: 1
Candle1 Body Ref#: 3, Op: “>”, Mult: 1
Candle0 Vol Ref#: 2, Op: “<=”, Mult: 1
Candle1 Vol Ref#: 2, Op: “<=”, Mult: 1
Candle3 Vol Ref#: 2, Op: “<=”, Mult: 0.5
All other comparisons (operators) can be left blank if you don’t want to use them!
When these rules are met, a bright red “SELL” label will appear right above the bar matching all your conditions.
Practical Tips & FAQ for Beginners
What does “body” mean?
It’s the “true range” of the candle: the difference between open and close. This ignores wicks for simple setups.
What does “volume” mean?
This is the total trading activity during that candle/bar. Many traders believe that patterns with different volume “meaning” (such as low-volume up bars, or high-volume down bars) signal a meaningful change.
What if nothing shows on chart?
It just means your current rules are rarely or never matched! Try making your comparisons simpler (maybe just 2-body and 2-volume conditions to start).
You can always hit “Reset Settings” to go back to default.
Can I use this for both buying and selling?
YES! You can detect both bullish (Buy) and bearish (Sell) custom conditions; just switch “Signal Side.”
Do I need to know coding?
Not at all! Everything is in simple input panels.
Creative Use Cases, Example Recipes & Troubleshooting
Creative Ways to Use
Spotting Reversals
Example:
Buy when: the newest candle body is LARGER than the previous 3 bars, but ALL volumes are lower than their neighbors.
Why? Sometimes, a big candle with surprisingly low volume after a sequence of small bars can signal a reversal.
Finding Exhaustion Moves
Example:
Sell when: the current bar body is twice as big as two bars ago, but volume is half.
Why? A very big candle with very little volume compared to similar bars may show the move is “running out of steam.”
Custom “Breakout + Confirmation” Patterns
Example:
Buy when:
Candle 0’s body is greater than Candle 2’s by at least 1.5x,
Candle 0’s volume is greater than Candle 1 and Candle 2,
Candle 1’s volume is less than Candle 0.
Why? This could catch strong breakouts but filter out noisy moves.
Multi-bar Bias/Squeeze Filter
Use “Pattern Candle Count: 4”
Set all 4 volume conditions to “<” and each reference to the previous candle.
Now, a BUY or SELL only marks when each bar is “dryer”/less active than the last — a classic squeeze or low-volatility buildup.
Troubleshooting Guide
“I don’t see any Buy/Sell label; is something broken?”
Most likely, your rules are too strict or rare! Try using only two comparisons and leave other “Op” inputs blank as a test.
Double-check you have enough candles on the chart: you need at least as many bars as your pattern count.
“Why does a label appear but not where I expect?”
Remember, the script checks your rules for every NEW candle. The candle “0” is always the most recent, then “1” is one bar back, etc.
Check the color and type chosen: “Signal Side” must be “Buy” for green, “Sell” for red.
“What if I want a more complex pattern?”
Stack conditions! You can demand the body/volume of each candle in your window meet a different rule or all follow the same rule in sequence.
Mini Glossary — For Newcomers
Candle/Bar: Each bar on the chart, shows price movement during a fixed time (e.g., one minute, one hour, one day).
Body: The colored (or filled) part of the candle — the open-to-close price range.
Volume: How much of the asset was actually traded that candle/bar.
Reference Index: When you pick “2” as a reference, it means “the candle two bars ago in the pattern window.”
Operator (“Op”): The math symbol used to compare (>, <, =, etc).
Signal Side: Whether you want to highlight bullish (“Buy”) or bearish (“Sell”) bars.
Tips for Getting More Value
Start Simple—try just one or two conditions at first. See what lights up. Slowly add more logic as you get comfortable.
Watch the chart live as you change settings. The labels update instantly—this makes strategy design fast and visual!
Try flipping your ideas: If a certain pattern doesn’t work for buys, try reversing the direction for possible “sell” setups.
Remember: There is NO wrong idea. This indicator is only limited by your creativity—it’s a “strategy playground.”
Example Quick-Start Recipes
Classic Sell:
4 candles, side = Sell
Candle0 Body > Candle2; Candle1 Body > Candle3
Candle0 Vol <= Candle2; Candle1 Vol <= Candle2; Candle3 Vol <= Candle2 × 0.5
Simple Buy After Pause:
3 candles, side = Buy
Candle0 Body > Candle1; Candle0 Vol > Candle1
All other Ops blank
Low-Volume Pullback for Entry:
4 candles, side = Buy
Candle0 Body > Candle2
Candle0 Vol < Candle1; Candle1 Vol < Candle2; Candle2 Vol < Candle3
Final Words
Think of this as your “pattern lab.” No code, no guesswork—just experiment, see what the market actually gives, and design your own visual rulebook.
If you’re stuck, reset the script to defaults—it’s always safe to start again!
If you want more ready-made “recipes” for different strategies/styles, just ask and I’ll send some more setups for you.
Happy building—and may your edge always be YOUR edge!
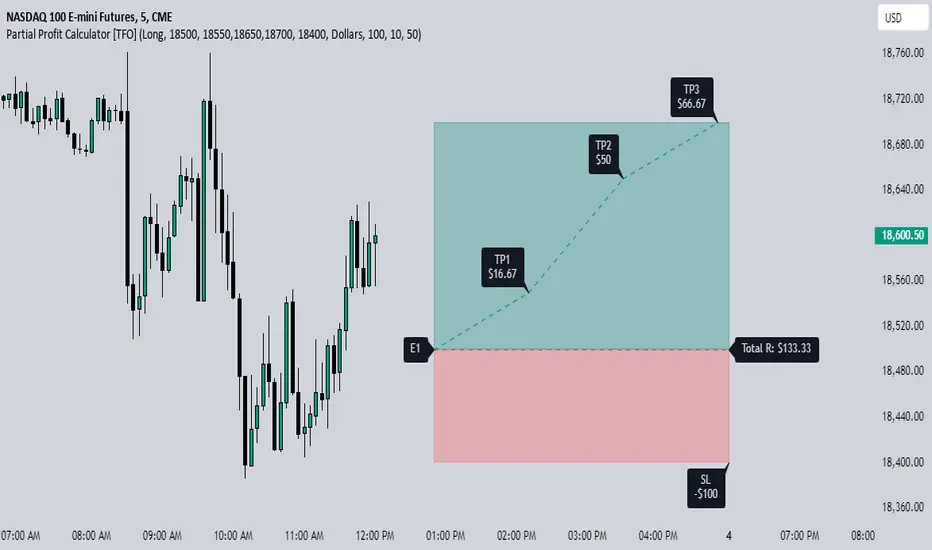
Partial Profit Calculator [TFO]This indicator was built to help calculate the outcome of trades that utilize multiple profit targets and/or multiple entries.
In its simplest form, we can have a single entry and a single profit target. As shown below in this long trade example, the indicator will draw risk and reward boxes (red and green, respectively) with several annotations. On the left-hand side, all entries will be displayed (in this case there is only one entry, "E1"). On the bottom, the "SL" label indicates the trade's stop loss placement. On the top, all target prices are displayed (in this case there is only one target, "TP1"). Lastly, on the right-hand side a label will display the total R that is to be expected from a winning trade, where R is one's unit of risk.
In the following example, we have two target prices - one at 18600 and one at 18700. You can input as many target prices as you'd like, separated by commas, i.e. "18600,18700" in this example. Make sure the values are separated by commas only, and not spaces, new lines, etc. As a result, we can see that the indicator draws where our profit targets would be with respect to our entry, E1. The indicator assumes that equal parts of the trade position are taken off at each target price. In this example on Nasdaq futures (NQ1!), since we have 2 target prices, this would be equivalent to assuming that we take exactly half the trade position off at TP1, and the remaining half of the position at TP2.
If we wanted to take more of the position off at a certain target, we could simply duplicate the target price. Here I set the target prices to "18600,18600,18700" to enforce that two thirds of the position be taken off at TP1 and TP2, while the remaining third gets taken off at TP3.
We can also show outcome annotations to describe how much R is generated from each possible trade outcome. Using the below chart as an example, the stop loss indicates a -1R loss. The total R from this trade criteria is 1.33 R, and each target price shows how much R is being generated if one were to take off an equal part of the position at said target prices. In this case, we would generate 0.17 R from taking one third of the position off at TP1, another 0.5 R from taking one third of the position off at TP2, and another 0.67 R from taking the remaining one third of the position off at TP3, all adding up to the total R indicated on the right-hand side label.
Using multiple entries works the same way as using multiple target prices, where the input should indicate each entry price separated by commas. In this example I've used "18550,18450" to achieve an average price of 18500, as indicated by the "E_avg" label that appears when more than one entry price is utilized. We can also opt to display risk as dollars instead of R values, where you can input your desired risk per trade, and all values are shown as dollar amounts instead of R multiples, as shown below with a risk per trade of $100.
This is meant to be an educational tool for trades that utilize multiple profit targets and/or entries. Hope you like it!
ATR Bands with Optional Risk/Reward Colors█ OVERVIEW
This indicator projects ATR bands and, optionally, colors them based on a risk/reward advantage for those who trade breakouts/breakdowns using moving averages as partial or full exit points.
█ DEFINITIONS
► True Range
The True Range is a measure of the volatility of a financial asset and is defined as the maximum difference among one of the following values:
- The high of the current period minus the low of the current period.
- The absolute value of the high of the current period minus the closing price of the previous period.
- The absolute value of the low of the current period minus the closing price of the previous period.
► Average True Range
The Average True Range was developed by J. Welles Wilder Jr. and was introduced in his 1978 book titled "New Concepts in Technical Trading Systems". It is calculated as an average of the true range values over a certain number of periods (usually 14) and is commonly used to measure volatility and set stop-loss and profit targets (1).
For example, if you are looking at a daily chart and you want to calculate the 14-day ATR, you would take the True Range of the previous 14 days, calculate their average, and this would be the ATR for that day. The process is then repeated every day to obtain a series of ATR values over time.
The ATR can be smoothed using different methods, such as the Simple Moving Average (SMA), the Exponential Moving Average (EMA), or others, depending on the user's preferences or analysis needs.
► ATR Bands
The ATR bands are created by adding or subtracting the ATR from a reference point (usually the closing price). This process generates bands around the central point that expand and contract based on market volatility, allowing traders to assess dynamic support and resistance levels and to adapt their trading strategies to current market conditions.
█ INDICATOR
► ATR Bands
The indicator provides all the essential parameters for calculating the ATR: period length, time frame, smoothing method, and multiplier.
It is then possible to choose the reference point from which to create the bands. The most commonly used reference points are Open, High, Low, and Close, but you can also choose the commonly used candle averages: HL2, HLC3, HLCC4, OHLC4. Among these, there is also a less common "OC2", which represents the average of the candle body. Additionally, two parameters have been specifically created for this indicator: Open/Close and High/Low.
With the "Open/Close" parameter, the upper band is calculated from the higher value between Open and Close, while the lower one is calculated from the lower value between Open and Close. In the case of bullish candles, therefore, the Close value is taken as the starting point for the upper band and the Open value for the lower one; conversely, in bearish candles, the Open value is used for the upper band and the Close value for the lower band. This setting can be useful for precautionally generating broader bands when trading with candlesticks like hammers or inverted hammers.
The "High/Low" parameter calculates the upper band starting from the High and the lower band starting from the Low. Among all the available options, this one allows drawing the widest bands.
Other possible options to improve the drawing of ATR bands, aligning them with the price action, are:
• Doji Smoothing: When the current candle is a doji (having the same Open and Close price), the bands assume the values they had on the previous candle. This can be useful to avoid steep fluctuations of the bands themselves.
• Extend to High/Low: Extends the bands to the High or Low values when they exceed the value of the band.
• Round Last Cent: Expands the upper band by one cent if the price ends with x.x9, and the lower band if the price ends with x.x1. This function only works when the asset's tick is 0.01.
► Risk/Reward Advantage
The indicator optionally colors the ATR bands after setting a breakpoint, one or two risk/reward ratios, and a series of moving averages. This function allows you to know in advance whether entering a trade can provide an advantage over the risk. The band is colored when the ratio between the distance from the break point to the band and the distance from the break point to the first available moving average reaches at least the set ratio value. It is possible to set two colorings, one for a minimum risk/reward ratio and one for an optimal risk/reward ratio.
The break point can be chosen between High/Low (High in case of breakout, Low in case of breakdown) or Open/Close (on breakouts, Close with bullish candles or Open with bearish candles; on breakdowns, Close with bearish candles or Open with bullish candles).
It is possible to choose up to 10 moving averages of various types, including the VWAP with the Anchor Period (2).
Depending on the "Price to MA" setting, the bands can be individually or simultaneously colored.
By selecting "Single Direction," the risk/reward calculation is performed only when all moving averages are above or below the break point, resulting in only one band being colored at a time. For this reason, when the break point is in between the moving averages, the calculation is not executed. This setting can be useful for strategies involving price movement from a level towards a series of specific moving averages (for example, in reversals starting from a certain level towards the VWAP with possible partial take profits on some previous moving averages, or simply in trend following towards one or more moving averages).
Choosing "Both Directions" the risk/reward ratio is calculated based on the first available moving averages both above and below the price. This setting is useful for those who operate in range bound markets or simply take advantage of movements between moving averages.
█ NOTE
This script may not be suitable for scalping strategies that require immediate entries due to the inability to know the ATR of a candle in advance until its closure. Once the candle is closed, you should have time to place a stop or stop-limit order, so your strategy should not anticipate an immediate start with the next candle. Even more conveniently, if your strategy involves an entry on a pullback, you can place a limit order at the breakout level.
(1) www.tradingview.com
(2) For convenience, the code for the Anchor Period has been entirely copied from the VWAP code provided by TradingView.

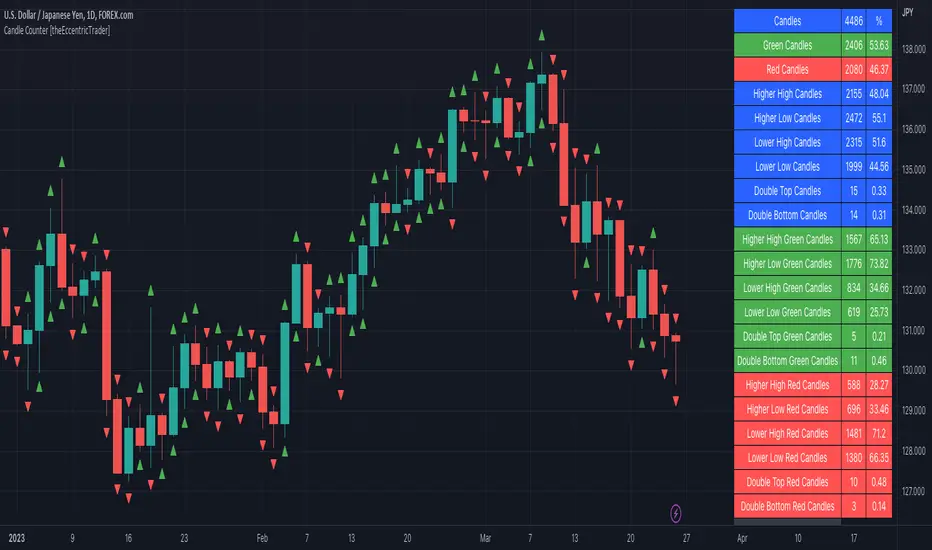
Candle Counter [theEccentricTrader]█ OVERVIEW
This indicator counts the number of confirmed candle scenarios on any given candlestick chart and displays the statistics in a table, which can be repositioned and resized at the user's discretion.
█ CONCEPTS
Green and Red Candles
A green candle is one that closes with a high price equal to or above the price it opened.
A red candle is one that closes with a low price that is lower than the price it opened.
Upper Candle Trends
A higher high candle is one that closes with a higher high price than the high price of the preceding candle.
A lower high candle is one that closes with a lower high price than the high price of the preceding candle.
A double-top candle is one that closes with a high price that is equal to the high price of the preceding candle.
Lower Candle Trends
A higher low candle is one that closes with a higher low price than the low price of the preceding candle.
A lower low candle is one that closes with a lower low price than the low price of the preceding candle.
A double-bottom candle is one that closes with a low price that is equal to the low price of the preceding candle.
█ FEATURES
Inputs
Start Date
End Date
Position
Text Size
Show Sample Period
Show Plots
Table
The table is colour coded, consists of three columns and twenty-two rows. Blue cells denote all candle scenarios, green cells denote green candle scenarios and red cells denote red candle scenarios.
The candle scenarios are listed in the first column with their corresponding total counts to the right, in the second column. The last row in column one, row twenty-two, displays the sample period which can be adjusted or hidden via indicator settings.
Rows two and three in the third column of the table display the total green and red candles as percentages of total candles. Rows four to nine in column three, coloured blue, display the corresponding candle scenarios as percentages of total candles. Rows ten to fifteen in column three, coloured green, display the corresponding candle scenarios as percentages of total green candles. And lastly, rows sixteen to twenty-one in column three, coloured red, display the corresponding candle scenarios as percentages of total red candles.
Plots
I have added plots as a visual aid to the various candle scenarios listed in the table. Green up-arrows denote higher high candles when above bar and higher low candles when below bar. Red down-arrows denote lower high candles when above bar and lower low candles when below bar. Similarly, blue diamonds when above bar denote double-top candles and when below bar denote double-bottom candles. These plots can also be hidden via indicator settings.
█ HOW TO USE
This indicator is intended for research purposes and strategy development. I hope it will be useful in helping to gain a better understanding of the underlying dynamics at play on any given market and timeframe. It can, for example, give you an idea of any inherent biases such as a greater proportion of green candles to red. Or a greater proportion of higher low green candles to lower low green candles. Such information can be very useful when conducting top down analysis across multiple timeframes, or considering trailing stop loss methods.
What you do with these statistics and how far you decide to take your research is entirely up to you, the possibilities are endless.
This is just the first and most basic in a series of indicators that can be used to study objective price action scenarios and develop a systematic approach to trading.
█ LIMITATIONS
Some higher timeframe candles on tickers with larger lookbacks such as the DXY, do not actually contain all the open, high, low and close (OHLC) data at the beginning of the chart. Instead, they use the close price for open, high and low prices. So, while we can determine whether the close price is higher or lower than the preceding close price, there is no way of knowing what actually happened intra-bar for these candles. And by default candles that close at the same price as the open price, will be counted as green. You can avoid this problem by utilising the sample period filter.
The green and red candle calculations are based solely on differences between open and close prices, as such I have made no attempt to account for green candles that gap lower and close below the close price of the preceding candle, or red candles that gap higher and close above the close price of the preceding candle. I can only recommend using 24-hour markets, if and where possible, as there are far fewer gaps and, generally, more data to work with. Alternatively, you can replace the scenarios with your own logic to account for the gap anomalies, if you are feeling up to the challenge.
It is also worth noting that the sample size will be limited to your Trading View subscription plan. Premium users get 20,000 candles worth of data, pro+ and pro users get 10,000, and basic users get 5,000. If upgrading is currently not an option, you can always keep a rolling tally of the statistics in an excel spreadsheet or something of the like.
Dynamic Zone Range on OMA [Loxx]Dynamic Zone Range on OMA is an One More Moving Average oscillator with Dynamic Zones.
What is the One More Moving Average (OMA)?
The usual story goes something like this : which is the best moving average? Everyone that ever started to do any kind of technical analysis was pulled into this "game". Comparing, testing, looking for new ones, testing ...
The idea of this one is simple: it should not be itself, but it should be a kind of a chameleon - it should "imitate" as much other moving averages as it can. So the need for zillion different moving averages would diminish. And it should have some extra, of course:
The extras:
it has to be smooth
it has to be able to "change speed" without length change
it has to be able to adapt or not (since it has to "imitate" the non-adaptive as well as the adaptive ones)
The steps:
Smoothing - compared are the simple moving average (that is the basis and the first step of this indicator - a smoothed simple moving average with as little lag added as it is possible and as close to the original as it is possible) Speed 1 and non-adaptive are the reference for this basic setup.
Speed changing - same chart only added one more average with "speeds" 2 and 3 (for comparison purposes only here)
Finally - adapting : same chart with SMA compared to one more average with speed 1 but adaptive (so this parameters would make it a "smoothed adaptive simple average") Adapting part is a modified Kaufman adapting way and this part (the adapting part) may be a subject for changes in the future (it is giving satisfactory results, but if or when I find a better way, it will be implemented here)
Some comparisons for different speed settings (all the comparisons are without adaptive turned on, and are approximate. Approximation comes from a fact that it is impossible to get exactly the same values from only one way of calculation, and frankly, I even did not try to get those same values).
speed 0.5 - T3 (0.618 Tilson)
speed 2.5 - T3 (0.618 Fulks/Matulich)
speed 1 - SMA , harmonic mean
speed 2 - LWMA
speed 7 - very similar to Hull and TEMA
speed 8 - very similar to LSMA and Linear regression value
Parameters:
Length - length (period) for averaging
Source - price to use for averaging
Speed - desired speed (i limited to -1.5 on the lower side but it even does not need that limit - some interesting results with speeds that are less than 0 can be achieved)
Adaptive - does it adapt or not
Variety Moving Averages w/ Dynamic Zones contains 33 source types and 35+ moving averages with double dynamic zones levels.
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included
4 signal types
Bar coloring
Alerts
Channels fill
Dekidaka-Ashi - Candles And Volume Teaming Up (Again)The introduction of candlestick methods for market price data visualization might be one of the most important events in the history of technical analysis, as it totally changed the way to see a trading chart. Candlestick charts are extremely efficient, as they allow the trader to visualize the opening, high, low and closing price (OHLC) each at the same time, something impossible with a traditional line chart. Candlesticks are also cleaner than bars charts and make a more efficient use of space. Japanese peoples are always better than everyone at an incredible amount of stuff, look at what they made, the candlesticks/renko/kagi/heikin-ashi charts, the Ichimoku, manga, ecchi...
However classical candlesticks only include historical market price data, and won't include other type of data such as volume, which is considered by many investors a key information toward effective financial forecasting as volume is an indicator of trading activity. In order to tackle to this problem solutions where proposed, the most common one being to adapt the width of the candle based on the amount of volume, this method is the most commonly accepted one when it comes to visualizing both volume and OHLC data using candlesticks.
Now why proposing an additional tool for volume data visualization ? Because the classical width approach don't provide usable data regarding volume (as the width is directly related to the volume data). Therefore a new trading tool based on candlesticks that allow the trader to gain access to information about the volume is proposed. The approach is based on rescaling the volume directly to the price without the direct use of user settings. We will also see that this tool allow to create support and resistances as well as providing signals based on a breakout methodology.
Dekidaka-Ashi - Kakatte Koi Yo!
"Dekidaka" (出来高) mean "Volume" in a financial context, while "Ashi" (足) mean "leg" or "bar". In general methods based on candlesticks will have "Ashi" in their name.
Now that the name of the indicator has been explained lets see how it works, the indicator should be overlayed directly to a candlestick chart. The proposed method don't alter the shape of the candlesticks and allow to visualize any information given by the candles. As you can see on the figure below the candle body of the proposed tool only return the border of the candle, this allow to show the high/low wick of the candle.
The body size of the candle is based on two things : the absolute close/open difference, and the volume, if the absolute close/open difference is high and the volume is high then the body of the candle will be clearly visible, if the volume is high but the absolute close/open difference is low, then the body will be less visible. This approach is used because of the rescaling method used, the volume is divided by the sum between the current volume value and the precedent volume value, this rescale the volume in a (0,1) range, this result is multiplied by the absolute close/open difference and added/subtracted to the high/low price. The original approach was based on normalization using the rolling maximum, but this approach would have led to repainting.
You have access to certain settings that can help you obtain a better visualization, the first one being the body size setting, with higher values increasing the body amplitude.
In green body with size 2, in red with size 1. The smooth parameter will smooth the volume data before being used, this allow to create more visible bodies.
Here smooth = 100.
Making Bands From The Dekidaka-Ashi
This tool is made so it output two rescaled volume values, with the highest value being denoted as "Dekidaka-high" and the lowest one as "Dekidaka-low". In order to get bands we must use two moving averages, one using the Dekidaka-high as input and the other one using Dekidaka-low, the body size parameter should be fairly high, therefore i will hide the tool as it could cause trouble visualizing the bands.
Bands with both MA's of period 20 and the body size equal to 20. Larger periods of the MA's will require a larger amount of body size.
Breakout Signals
There is a wide variety of signals that can be made from candles, ones i personally like comes from the HA candles. The proposed tool is no exception and can produce a wide variety of signals. The signals generated are basic ones based on a breakout methodology, here is each signal with their associated label :
Strong Bullish signal "⇈" : The high price cross the Dekidaka-high and the closing price is greater than the opening price
Strong Bearish signal "⇊" : The low price cross the Dekidaka-low and the closing price is lower than the opening price
Weak Bullish signal "↑" : The high price cross the Dekidaka-high and the closing price is lower than the opening price
Weak Bearish signal "↓" : The low price cross the Dekidaka-low and the closing price is greater than the opening price
Uncertain "↕" : The high price cross the Dekidaka-high and the low price cross the the Dekidaka-low
In order to see the signals on the chart check the "Show signals" option. Note that such signals are not based on an advanced study, and even if they are based on a breakout methodology we can see that volatile movement rarely produce signals, therefore signals mostly occur during low volume/volatility periods, which isn't necessarily a great thing.
Conclusion
A trading tool based on candlesticks that aim to include volume information has been presented and a brief methodology has been introduced. A study of the signals generated is required, however i'am not confident at all on their accuracy, i could work on that in the future. We have also seen how to make bands from the tool.
Candlesticks remain a beautiful charting technique that can provide an enormous amount of information to the trader, and even if the accuracy of patterns based on candlesticks is subject to debates, we can all agree that candlesticks will remain the most widely used type of financial chart.
On a side note i mostly use a dark color for a bullish candle, and a light gray for a bearish candle, with the border color being of the same color as the bullish candle. This is in my opinion the best setup for a candlestick chart, as candles using the traditional green/red can kill the eyes and because this setup allow to apply a wide variety of colors to the plot of overlayed indicators without the fear of causing conflict with the candles color.
Thanks for reading ! :3 Nya
A Word
This morning i received some hateful messages on twitter, the users behind them certainly coming from tradingview, so lets be clear, i know i'am not the most liked person in this community, i know that perfectly, but no one merit to be receive hateful messages. I'am not responsible for the losses of peoples using my indicators, nor is tradingview, using technical indicators does not guarantee long term returns, your ability to be profitable will mostly be based on the quality and quantity of knowledge you have.

FX Meter ScriptA while ago, we wrote* about the usefulness of using a currency strength meter and how you can build one from scratch.
See here: www.globalprime.com.au
Now we've taken this little project to the next level by visually spotting, via color signals in a dashboard and alerts, when a potential new trend might be developing in a currency pair.
*It's critical that you first read that article before you jump into reading this one or else you could get easily lost.
The script gives a trigger every time two currencies show diverging flows via opposing moving average slopes.
The signals originate from a first chart where currency indexes can be found, calculated through a formula, in various thin lines. Then a moving average to each currency index is applied so that it can smooth out the lines (what I call Micro moving averages – thicker lines -) and is usually a 4-5 period MA, with the key input to pay attention being the slope. One can perform their own tests on what works best for their particular trading style. The smaller the period in the moving average, the more responsive to changes in biases but the downside is that you will get a greater number of false moves. In the windows below the 1st chart, the stochRSI is calculated for each currency index (these values originate from the currency index and not from the applied MA). By default, a 25-period is applied to both RSI and Stoch length.
A 2nd chart that looks at the same logic is also accounted for to build this script, but instead of checking the micro trend, it applies a 25MA to the currency index, so it looks at what I call the slope of the macro trend. In this case, by default, a 125-period is applied to both RSI and Stoch length.
We had in mind to transition from just eye-balling and monitoring these charts manually to build a script via Tradingview that makes calculations real time (whenever the change in the moving average slope first occurs, and not when the bar/line closes), so that one can decide whether or not its a signal worth trading as part of a new trend emerging. Note, this is not so much a signal-triggering indicator but rather a tool to constantly be on the lookout monitoring what currencies might start to develop trends.
The actual script consists of a dashboard with different colored rectangles being triggered depending on the quality of the signal.
We will be happy to discuss it further with anyone who is interested in exploiting all the benefits that it can offer.
The way you add the script into your Tradingview chart is by first copy everything in the txt file. Then go to Pine editor (bottom middle-left) in your tradingview chart, delete everything there, then Paste the script. Then click Add to Chart (top right of the pine editor).
Note, you should add via the Anchored Text function the following list of pairs below, in this alphabetic order, on the right-hand side of the chart, as demonstrated above:
AUDCAD
AUDJPY
AUDNZD
AUDUSD
CADJPY
EURAUD
EURJPY
EURCAD
EURNZD
EURGBP
EURUSD
GBPAUD
GBPCAD
GBPJPY
GBPNZD
GBPUSD
NZDCAD
NZDJPY
NZDUSD
USDCAD
USDJPY
There are only 2 rules for the script to trigger a signal (see below). However, as I will elaborate further down, there are up to 6 different colors we can grade a signal
RULE 1 -> 2 moving averages, which are a calculation applied to a currency index as shown in the micro trend above, exhibit slopes in the opposite direction.
RULE 2 -> The Stoch RSI cannot be in overbought conditions if the slope of the moving average points higher or in oversold if the slope points lower.
Note 1: Even if the chart is a 60m timeframe by default (can be changed to any timeframe(, one gets the signal the moment the change of slope is identified, which means the indicator monitors changes in price tick by tick, and not on a candle close, otherwise one would get the trigger too late.
As an example of the highest-graded signal triggering (in green), a few hours ago we were given the visual cue that GBPCAD was experiencing a change of behavior. If we crosscheck the time the green-colored trigger was given with the actual GBPCAD chart, this is what we can observe. The pair is 30p higher since the trigger.
HOW TO SETUP ALERTS
One can easily setup a notification window each time the above rules are met, for example, if the EUR MA slope changes to bullish, and the AUD MA slope changes to bearish, and none of the 2 currency index values corresponding to these 2 moving averages (EUR and AUD) show a stoch RSI in overbought (above 80) in the case of the EUR, or oversold (below 20) in the case of the AUD, then the notification pop up would show a customized line: Long EURAUD
Note 1: Recording the slope of the macro moving average, which is usually a 25period MA applied to the currency index, is not included as part of the rules to trigger a signal, but it is taken into account to grade the quality of each signal.
Note 2: I recommend each signal to be triggered once or if you prefer, simply monitor the chart visually on the change of colors via the dashboard. The calculation resets and can appear again the moment that the slope changes to the opposite direction, so it’s a very dynamic indicator that will alert you the second a pair of currencies starts trending.
Note 3: When the signal is triggered, the indicator draws a colored rectangle. Each signal notification should be colored based on the following logic below.
LOGIC TO QUALIFY SIGNALS
-> Any long micro position with Macro MA in full agreement (ie/ Long EURAUD, Macro EUR up, Macro AUD down) is highlighted with green color
-> Any long micro position with macro moving averages in partial agreement (for example Long EURAUD, Macro EUR up AUD up) is highlighted with blue color
-> Any long micro position with macro moving averages in full disagreement (for example Long EURAUD, Macro EUR down AUD up) is highlighted with magenta color
-> Any short micro position with macro moving averages in full agreement (for example Short EURAUD, Macro EUR down AUD up) is highlighted with red color
-> Any short micro position with macro moving averages in partial agreement (for example Short EURAUD, Macro EUR up AUD up) is highlighted with orange color
-> Any short micro position with macro moving averages in full disagreement (for example Short EURAUD, Macro EUR up AUD down) is highlighted with purple color
PARAMETERS IN THE SCRIPT SETTINGS
Overbought/oversold: One can modify the stoch RSI level from which the indicator considers the value to be in overbought or oversold conditions. As a rule of thumb, consider 20/30 for oversold and 70/80 for oversold.
Slopes micro/macro MAs: One can edit the slope of the micro MA period (rule of thumb 4-5) and the macro MA (by default 25).
Value StochRSI: The default inputs are K 3, D 3, RSI Length 25, Stoch Length 25 for the micro and 125 period for the macro.
Change colors: One can edit the assigned colors in the signals dashboard.
Timeframe applied: The indicator has the flexibility to be applied to any timeframe, not just the 60m by default. Simply change the timeframe temporality.
CURRENCY INDEXES FORMULAS
It is the responsibility of the user to keep the values of the indexes updated. Find a recent sample below, as per values in early April. What this means is that at least once a week, in order to not let the values outdated, you should update the script with the latest valuations in the denominator.
NZD INDEX -> FX_IDC:NZDAUD/0.96+FX:NZDJPY/75.81+FX:NZDUSD/0.68+FX_IDC:NZDEUR/0.6+FX_IDC:NZDGBP/0.52+FX:NZDCHF/0.69+FX:NZDCAD/0.9
EUR INDEX -> FX:EURUSD/1.13+FX:EURJPY/125.5+FX:EURGBP/0.87+FX:EURCHF/1.135+FX:EURCAD/1.49+FX:EURNZD/1.655+FX:EURAUD/1.59
JPY INDEX -> 1/(FX:USDJPY/110.5+FX:EURJPY/125.5+FX:AUDJPY/79+FX:NZDJPY/75.5+FX:GBPJPY/144.5+FX:CHFJPY/110.5+FX:CADJPY/84)
USD INDEX -> FX_IDC:USDEUR/0.88+FX:USDJPY/110.5+FX_IDC:USDGBP/0.77+FX:USDCHF+FX:USDCAD/1.315+FX_IDC:USDNZD/1.46+FX_IDC:USDAUD/1.4
CAD INDEX-> FX_IDC:CADAUD/1.07+FX_IDC:CADNZD/1.11+FX:CADJPY/84.27+FX_IDC:CADUSD/0.76+FX_IDC:CADEUR/0.67+FX:CADCHF/0.76+FX_IDC:CADGBP/0.58
GBP INDEX -> FX:GBPAUD/1.83+FX:GBPNZD/1.91+FX:GBPJPY/144.5+FX_IDC:GBPEUR/1.15+FX:GBPCHF/1.31+FX:GBPUSD/1.31+FX:GBPCAD/1.71
Remember, I have provided a manual on how to build a currency strength meter. That’s what you will need to do first if you want to obtain the actual currency indexes other than just the indicator, which is just the visual cue to get you alerted when the slopes turn.
Once you’ve created your indexes via tradingview, you then apply a moving average to each index. Then apply the stochrsi 25 period to each index. For the macro trend, I make the same calculations, but the period of the MA is 25 instead of 4, while the stoch rsi is 125 periods vs 25 periods.
FINAL NOTE
This is a tool that should be interpreted as visual assistance, via the dashboard, to get that first cue when opposing micro slopes via the FX meter occur. However, you still need to check the technical context of the pair (levels marked, proj reached, etc.) but that first cue is a major time saver to constantly spot what's trending in FX. The permutations u can play with, as part of this script, are significant. You can tweak the timeframes you use, the periods of the moving averages, etc. I find the micro and macro trend combos when either a green or red signals is triggered the most reliable, with positions to be exploited via 15m and hourly under the right technical context.

Great Expectations [LucF]Great Expectations helps traders answer the question: What is possible? It is a powerful question, yet exploration of the unknown always entails risk. A more complete set of questions better suited to traders could be:
What opportunity exists from any given point on a chart?
What portion of this opportunity can be realistically captured?
What risk will be incurred in trying to do so, and how long will it take?
Great Expectations is the result of an exploration of these questions. It is a trade simulator that generates visual and quantitative information to help strategy modelers visually identify and analyse areas of optimal expectation on charts, whether they are designing automated or discretionary strategies.
WARNING: Great Expectations is NOT an indicator that helps determine the current state of a market. It works by looking at points in the past from which the future is already known. It uses one definition of repainting extensively (i.e. it goes back in the past to print information that could not have been know at the time). Repainting understood that way is in fact almost all the indicator does! —albeit for what I hope is a noble cause. The indicator is of no use whatsoever in analyzing markets in real-time. If you do not understand what it does, please stay away!
This is an indicator—not a strategy that uses TradingView’s backtesting engine. It works by simulating trades, not unlike a backtest, but with the crucial difference that it assumes a trade (either long or short) is entered on all bars in the historic sample. It walks forward from each bar and determines possible outcomes, gathering individual trade statistics that in turn generate precious global statistics from all outcomes tested on the chart.
Great Expectations provides numbers summarizing trade results on all simulations run from the chart. Those numbers cannot be compared to backtest-produced numbers since all non-filtered bars are examined, even if an entry was taken on the bar immediately preceding the current one, which never happens in a backtest. This peculiarity does NOT invalidate Great Expectations calculations; it just entails that results be considered under a different light. Provided they are evaluated within the indicator’s context, they can be useful—sometimes even more than backtesting results, e.g. in evaluating the impact of parameter-fitting or variations in entry, exit or filtering strats.
Traders and strategy modelers are creatures of hope often suffering from blurred vision; my hope is that Great Expectations will help them appraise the validity of their setup and strat intuitions in a realistic fashion, preventing confirmation bias from obstructing perspective—and great expectations from turning into financial great deceptions.
USE CASES
You’ve identified what looks like a promising setup on other indicators. You load Great Expectations on the chart and evaluate if its high-expectation areas match locations where your setup’s conditions occur. Unless today is your lucky day, chances are the indicator will help you realize your setup is not as promising as you had hoped.
You want to get a rough estimate of the optimal trade duration for a chart and you don’t mind using the entry and exit strategies provided with the indicator. You use the trade length readouts of the indicator.
You’re experimenting with a new stop strategy and want to know how long it will keep you in trades, on average. You integrate your stop strategy in the indicator’s code and look at the average trade length it produces and the TST ratio to evaluate its performance.
You have put together your own entry and exit criteria and are looking for a filter that will help you improve backtesting results. You visually ascertain the suitability of your filter by looking at its results on the charts with great Expectations, to see if your filter is choosing its areas correctly.
You have a strategy that shows backtested trades on your chart. Great Expectations can help you evaluate how well your strategy is benefitting from high-opportunity areas while avoiding poor expectation spots.
You want more complete statistics on your set of strategies than what backtesting will provide. You use Great Expectations, knowing that it tests all bars in the sample that correspond to your criteria, as opposed to backtesting results which are limited to a subset of all possible entries.
You want to fool your friends into thinking you’ve designed the holy grail of indicators, something that identifies optimal opportunities on any chart; you show them the P&L cloud.
FEATURES
For one trade
At any given point on the chart, assuming a trade is entered there, Great Expectations shows you information specific to that trade simulation both on the chart and in the Data Window.
The chart can display:
the P & L Cloud which shows whether the trade ended profitably or not, and by how much,
the Opportunity & Risk Cloud which the maximum opportunity and risk the simulation encountered. When superimposed over the P & L cloud, you will see what I call the managed opportunity and risk, i.e the portion of maximum opportunity that was captured and the portion of the maximum risk that was incurred,
the target and if it was reached,
a background that uses a gradient to show different levels of trade length, P&L or how frequently the target was reached during simulation.
The Data Window displays more than 40 values on individual trades and global results. For any given trade you will know:
Entry/Exit levels, including slippage impact,
It’s outcome and duration,
P/L achieved,
The fraction of the maximum opportunity/risk managed by the trade.
For all trades
After going through all the possible trades on the chart, the indicator will provide you with a rare view of all outcomes expressed with the P&L cloud, which allows us to instantly see the most/least profitable areas of a chart using trade data as support, while also showing its relationship with the opportunity/risk encountered during the simulation. The difference between the two clouds is the managed opportunity and risk.
The Data Window will present you with numbers which we will go through later. Some of them are: average stop size, P/L, win rate, % opportunity managed, trade lengths for different types of trade outcomes and the TST (Target:Stop Travel) ratio.
Let’s see Great Expectations in action… and remember to open your Data Window!
INPUTS
Trade direction : You must first choose if you wish to look at long or short trades. Because of the way the indicator works and the amount of visual information on the chart, it is only practical to look at one type of trades at a time. The default is Longs.
Maximum trade Length (MaxL) : This is the maximum walk forward distance the simulator will go in analyzing outcomes from any given point in the past. It also determines the size of the dead zone among the chart’s last bars. A red background line identifies the beginning of the dead zone for which not enough bars have elapsed to analyze outcomes for the maximum trade length defined. If an ATR-based entry stop is used, that length is added to the wait time before beginning simulations, so that the first entry starts with a clean ATR value. On a sample of around 16000 bars, my tests show that the indicator runs into server errors at lengths of around 290, i.e. having completed ~4,6M simulation loop iterations. That is way too high a length anyways; 100 will usually be amply enough to ring out all the possibilities out of a simulation, and on shorter time frames, 30 can be enough. While making it unduly small will prevent simulations of expressing the market’s potential, the less you use, the faster the indicator will run. The default is 40.
Unrealized P&L base at End of Trade (EOT) : When a simulation ends and the trade is still open, we calculate unrealized P&L from an exit order executed from either the last in-trade stop on the previous bar, or the close of the last bar. You can readily see the impact of this selection on the chart, with the P&L cloud. The default is on the close.
Display : The check box besides the title does nothing.
Show target : Shows a green line displaying the trade’s target expressed as a multiple of X, i.e. the amplitude of the entry stop. I call this value “X” and use it as a unit to express profit and loss on a trade (some call it “R”). The line is highlighted for trades where the close reached the target during the trade, whether the trade ended in profit or loss. This is also where you specify the multiple of X you wish to use in calculating targets. The multiple is used even if targets are not displayed.
Show P&L Cloud : The cloud allows traders to see right away the profitable areas of the chart. The only line printed with the cloud is the “end of trade line” (EOT). The EOT line is the only way one can see the level where a trade ended on the chart (in the Data Window you can see it as the “Exit Fill” value). The EOT level for the trade determines if the trade ended in a profit or a loss. Its value represents one of the following:
- fill from order executed at close of bar where stop is breached during trade (which produces “Realized P/L”),
- simulation of a fill pseudo-fill at the user-defined EOT level (last close or stop level) if the trade runs its course through MaxL bars without getting stopped (producing Unrealized P/L).
The EOT line and the cloud fill print in green when the trade’s outcome is profitable and in red when it is not. If the trade was closed after breaching the stop, the line appears brighter.
Show Opportunity&Risk Cloud : Displays the maximum opportunity/risk that was present during the trade, i.e. the maximum and minimum prices reached.
Background Color Scheme : Allows you to choose between 3 different color schemes for the background gradients, to accommodate different types of chart background/candles. Select “None” if you don’t want a background.
Background source : Determines what value will be used to generate the different intensities of the gradient. You can choose trade length (brighter is shorter), Trade P&L (brighter is higher) or the number of times the target was reached during simulation (brighter is higher). The default is Trade Length.
Entry strat : The check box besides the title does nothing. The default strat is All bars, meaning a trade will be simulated from all bars not excluded by the filters where a MaxL bars future exists. For fun, I’ve included a pseudo-random entry strat (an indirect way of changing the seed is to vary the starting date of the simulation).
Show Filter State : Displays areas where the combination of filters you have selected are allowing entries. Filtering occurs as per your selection(s), whether the state is displayed or not. The effect of multiple selections is additive. The filters are:
1. Bar direction: Longs will only be entered if close>open and vice versa.
2. Rising Volume: Applies to both long and shorts.
3. Rising/falling MA of the length you choose over the number of bars you choose.
4. Custom indicator: You can feed your own filtering signal through this from another indicator. It must produce a signal of 1 to allow long entries and 0 to allow shorts.
Show Entry Stops :
1. Multiple of user-defined length ATR.
2. Fixed percentage.
3. Fixed value.
All entry stops are calculated using the entry fill price as a reference. The fill price is calculated from the current bar’s open, to which slippage is added if configured. This simulates the case where the strategy issued the entry signal on the previous bar for it to be executed at the next bar’s open.
The entry stop remains active until the in-trade stop becomes the more aggressive of the two stops. From then on, the entry stop will be ignored, unless a bar close breaches the in-trade stop, in which case the stop will be reset with a new entry stop and the process repeats.
Show In-trade stops : Displays in bright red the selected in-trade stop (be sure to read the note in this section about them).
1. ATR multiple: added/subtracted from the average of the two previous bars minimum/maximum of open/close.
2. A trailing stop with a deviation expressed as a multiple of entry stop (X).
3. A fixed percentage trailing stop.
Trailing stops deviations are measured from the highest/lowest high/low reached during the trade.
Note: There is a twist with the in-trade stops. It’s that for any given bar, its in-trade stop can hold multiple values, as each successive pass of the advancing simulation loops goes over it from a different entry points. What is printed is the stop from the loop that ended on that bar, which may have nothing to do with other instances of the trade’s in-trade stop for the same bar when visited from other starting points in previous simulations. There is just no practical way to print all stop values that were used for any given bar. While the printed entry stops are the actual ones used on each bar, the in-trade stops shown are merely the last instance used among many.
Include Slippage : if checked, slippage will be added/subtracted from order price to yield the fill price. Slippage is in percentage. If you choose to include slippage in the simulations, remember to adjust it by considering the liquidity of the markets and the time frame you’ll be analyzing.
Include Fees : if checked, fees will be subtracted/added to both realized an unrealized trade profits/losses. Fees are in percentage. The default fees work well for crypto markets but will need adjusting for others—especially in Forex. Remember to modify them accordingly as they can have a major impact on results. Both fees and slippage are included to remind us of their importance, even if the global numbers produced by the indicator are not representative of a real trading scenario composed of sequential trades.
Date Range filtering : the usual. Just note that the checkbox has to be selected for date filtering to activate.
DATA WINDOW
Most of the information produced by this indicator is made available in the Data Window, which you bring up by using the icon below the Watchlist and Alerts buttons at the right of the TV UI. Here’s what’s there.
Some of the information presented in the Data Window is standard trade data; other values are not so standard; e. g. the notions of managed opportunity and risk and Target:Stop Travel ratio. The interplay between all the values provided by Great Expectations is inherently complex, even for a static set of entry/filter/exit strats. During the constant updating which the habitual process of progressive refinement in building strategies that is the lot of strategy modelers entails, another level of complexity is no doubt added to the analysis of this indicator’s values. While I don’t want to sound like Wolfram presenting A New Kind of Science , I do believe that if you are a serious strategy modeler and spend the time required to get used to using all the information this indicator makes available, you may find it useful.
Trade Information
Entry Order : This is the open of the bar where simulation starts. We suppose that an entry signal was generated at the previous bar.
Entry Fill (including slip.) : The actual entry price, including slippage. This is the base price from which other values will be calculated.
Exit Order : When a stop is breached, an exit order is executed from the close of the bar that breached the stop. While there is no “In-trade stop” value included in the Data Window (other than the End of trade Stop previously discussed), this “Exit Order” value is how we can know the level where the trade was stopped during the simulation. The “Trade Length” value will then show the bar where the stop was breached.
Exit Fill (including slip.) : When the exit order is simulated, slippage is added to the order level to create the fill.
Chart: Target : This is the target calculated at the beginning of the simulation. This value also appear on the chart in teal. It is controlled by the multiple of X defined under the “Show Target” checkbox in the Inputs.
Chart: Entry Stop : This value also appears on the chart (the red dots under points where a trade was simulated). Its value is controlled by the Entry Strat chosen in the Inputs.
X (% Fill, including Fees) and X (currency) : This is the stop’s amplitude (Entry Fill – Entry Stop) + Fees. It represents the risk incurred upon entry and will be used to express P&L. We will show R expressed in both a percentage of the Entry Fill level (this value), and currency (the next value). This value represents the risk in the risk:reward ratio and is considered to be a unit of 1 so that RR can be expressed as a single value (i.e. “2” actually meaning “1:2”).
Trade Length : If trade was stopped, it’s the number of bars elapsed until then. The trade is then considered “Closed”. If the trade ends without being stopped (there is no profit-taking strat implemented, so the stop is the only exit strat), then the trade is “Open”, the length is MaxL and it will show in orange. Otherwise the value will print in green/red to reflect if the trade is winning/losing.
P&L (X) : The P&L of the trade, expressed as a multiple of X, which takes into account fees paid at entry and exit. Given our default target setting at 2 units of “X”, a trade that closes at its target will have produced a P&L of +2.0, i.e. twice the value of X (not counting fees paid at exit ). A trade that gets stopped late 50% further that the entry stop’s level will produce a P&L of -1.5X.
P&L (currency, including Fees) : same value as above, but expressed in currency.
Target first reached at bar : If price closed above the target during the trade (even if it occurs after the trade was stopped), this will show when. This value will be used in calculating our TST ratio.
Times Stop/Target reached in sim. : Includes all occurrences during the complete simulation loop.
Opportunity (X) : The highest/lowest price reached during a simulation, i.e. the maximum opportunity encountered, whether the trade was previously stopped or not, expressed as a multiple of X.
Risk (X) : The lowest/highest price reached during a simulation, i.e. the maximum risk encountered, whether the trade was previously stopped or not, expressed as a multiple of X.
Risk:Opportunity : The greater this ratio, the greater Opportunity is, compared to Risk.
Managed Opportunity (%) : The portion of Opportunity that was captured by the highest/low stop position, even if it occurred after a previous stop closed the trade.
Managed Risk (%) : The portion of risk that was protected by the lowest/highest stop position, even if it occurred after a previous stop closed the trade. When this value is greater than 100%, it means the trade’s stop is protecting more than the maximum risk, which is frequent. You will, however, never see close to those values for the Managed Opportunity value, since the stop would have to be higher than the Maximum opportunity. It is much easier to alleviate the risk than it is to lock in profits.
Managed Risk:Opportunity : The ratio of the two preceding values.
Managed Opp. vs. Risk : The Managed Opportunity minus the Managed Risk. When it is negative, which is most often is, it means your strat is protecting a greater portion of the risk than it captures opportunity.
Global Numbers
Win Rate(%) : Percentage of winning trades over all entries. Open trades are considered winning if their last stop/close (as per user selection) locks in profits.
Avg X%, Avg X (currency) : Averages of previously described values:.
Avg Profitability/Trade (APPT) : This measures expectation using: Average Profitability Per Trade = (Probability of Win × Average Win) − (Probability of Loss × Average Loss) . It quantifies the average expectation/trade, which RR alone can’t do, as the probabilities of each outcome (win/lose) must also be used to calculate expectancy. The APPT combine the RR with the win rate to yield the true expectancy of a strategy. In my usual way of expressing risk with X, APPT is the equivalent of the average P&L per trade expressed in X. An APPT of -1.5 means that we lose on average 1.5X/trade.
Equity (X), Equity (currency) : The cumulative result of all trade outcomes, expressed as a multiple of X. Multiplied by the Average X in currency, this yields the Equity in currency.
Risk:Opportunity, Managed Risk:Opportunity, Managed Opp. vs. Risk : The global values of the ones previously described.
Avg Trade Length (TL) : One of the most important values derived by going through all the simulations. Again, it is composed of either the length of stopped trades, or MaxL when the trade isn’t stopped (open). This value can help systems modelers shape the characteristics of the components they use to build their strategies.
Avg Closed Win TL and Avg Closed Lose TL : The average lengths of winning/losing trades that were stopped.
Target reached? Avg bars to Stop and Target reached? Avg bars to Target : For the trades where the target was reached at some point in the simulation, the number of bars to the first point where the stop was breached and where the target was reached, respectively. These two values are used to calculate the next value.
TST (Target:Stop Travel Ratio) : This tracks the ratio between the two preceding values (Bars to first stop/Bars to first target), but only for trades where the target was reached somewhere in the loop. A ratio of 2 means targets are reached twice as fast as stops.
The next values of this section are counts or percentages and are self-explanatory.
Chart Plots
Contains chart plots of values already describes.
NOTES
Optimization/Overfitting: There is a fine line between optimizing and overfitting. Tools like this indicator can lead unsuspecting modelers down a path of overfitting that often turns strategies into over-specialized beasts that do not perform elegantly when confronted to the real-world. Proven testing strategies like walk forward analysis will go a long way in helping modelers alleviate this risk.
Input tuning: Because the results generated by the indicator will vary with the parameters used in the active entry, filtering and exit strats, it’s important to realize that although it may be fun at first, just slapping the default settings on a chart and time frame will not yield optimal nor reliable results. While using ATR as often as possible (as I do in this indicator) is a good way to make strat parametrization adaptable, it is not a foolproof solution.
There is no data for the last MaxL bars of the chart, since not enough trade future has elapsed to run a simulation from MaxL bars back.
Modifying the code: I have tried to structure the code modularly, even if that entails a larger code base, so that you can adapt it to your needs. I’ve included a few token components in each of the placeholders designed for entry strategies, filters, entry stops and in-trade stops. This will hopefully make it easier to add your own. In the same spirit, I have also commented liberally.
You will find in the code many instances of standard trade management tasks that can be lifted to code TV strategies where, as I do in mine, you manage everything yourself and don’t rely on built-in Pine strategy functions to act on your trades.
Enjoy!
THANKS
To @scarf who showed me how plotchar() could be used to plot values without ruining scale.
To @glaz for the suggestion to include a Chandelier stop strat; I will.
To @simpelyfe for the idea of using an indicator input for the filters (if some day TV lets us use more than one, it will be useful in other modules of the indicator).
To @RicardoSantos for the random generator used in the random entry strat.
To all scripters publishing open source on TradingView; their code is the best way to learn.
To my trading buddies Irving and Bruno; who showed me way back how pro traders get it done.
Relative Strength Heatmap [BackQuant]Relative Strength Heatmap
A multi-horizon RSI matrix that compresses 20 different lookbacks into a single panel, turning raw momentum into a visual “pressure gauge” for overbought and oversold clustering, trend exhaustion, and breadth of participation across time horizons.
What this is
This indicator builds a strip-style heatmap of 20 RSIs, each with a different length, and stacks them vertically as colored tiles in a single pane. Every tile is colored by its RSI value using your chosen palette, so you can see at a glance:
How many “fast” versus “slow” RSIs are overbought or oversold.
Whether momentum is concentrated in the short lookbacks or spread across the whole curve.
When momentum extremes cluster, signalling strong market pressure or exhaustion.
On top of the tiles, the script plots two simple breadth lines:
A white line that counts how many RSIs are above 70 (overbought cluster).
A black line that counts how many RSIs are below 30 (oversold cluster).
This turns a single symbol’s RSI ladder into a compact “market pressure gauge” that shows not only whether RSI is overbought or oversold, but how many different horizons agree at the same time.
Core idea
A single RSI looks at one length and one timescale. Markets, however, are driven by flows that operate on multiple horizons at once. By computing RSI over a ladder of lengths, you approximate a “term structure” of strength:
Short lengths react to immediate swings and very recent impulses.
Medium lengths reflect swing behaviour and local trends.
Long lengths reflect structural bias and higher timeframe regime.
When many lengths agree, for example 10 or more RSIs all above 70, it suggests broad participation and strong directional pressure. When only a few fast lengths stretch to extremes while longer ones stay neutral, the move is more fragile and more likely to mean-revert.
This script makes that structure visible as a heatmap instead of forcing you to run many separate RSI panes.
How it works
1) Generating RSI lengths
You control three parameters in the calculation settings:
RS Period – the base RSI length used for the shortest strip.
RSI Step – the amount added to each successive RSI length.
RSI Multiplier – a global scaling factor applied after the step.
Each of the 20 RSIs uses:
RSI length = round((base_length + step × index) × multiplier) , where the index goes from 0 to 19.
That means:
RSI 1 uses (len + step × 0) × mult.
RSI 2 uses (len + step × 1) × mult.
…
RSI 20 uses (len + step × 19) × mult.
You can keep the ladder dense (small step and multiplier) or stretch it across much longer horizons.
2) Heatmap layout and grouping
Each RSI is plotted as an “area” strip at a fixed vertical level using histbase to stack them:
RSI 1–5 form Group 1.
RSI 6–10 form Group 2.
RSI 11–15 form Group 3.
RSI 16–20 form Group 4.
Each group has a toggle:
Show only Group 1 and 2 if you care mainly about fast and medium horizons.
Show all groups for a full spectrum from very short to very long.
Hide any group that feels redundant for your workflow.
The actual numeric RSI values are not plotted as lines. Instead, each strip is drawn as a horizontal band whose fill color represents the current RSI regime.
3) Palette-based coloring
Each tile’s color is driven by the RSI value and your chosen palette. The script includes several palettes:
Viridis – smooth green to yellow, good for subtle reading.
Jet – strong blue to red sequence with high contrast.
Plasma – purple through orange to yellow.
Custom Heat – cool blues to neutral grey to hot reds.
Gray – grayscale from white to black for minimalistic layouts.
Cividis, Inferno, Magma, Turbo, Rainbow – additional scientific and rainbow-style maps.
Internally, RSI values are bucketed into ranges (for example, below 10, 10–20, …, 90–100). Each bucket maps to a unique colour for that palette. In all schemes, low RSI values are mapped to the “cold” or darker side and high RSI values to the “hot” or brighter side.
The result is a true momentum heatmap:
Cold or dark tiles show low RSI and oversold or compressed conditions.
Mid tones show neutral or mid-range RSI.
Warm or bright tiles show high RSI and overbought or stretched conditions.
4) Bull and bear breadth counts
All 20 RSI values are collected into an array each bar. Two counters are then calculated:
Bull count – how many RSIs are above 70.
Bear count – how many RSIs are below 30.
These are plotted as:
A white line (“RSI > 70 Count”) for the overbought cluster.
A black line (“RSI < 30 Count”) for the oversold cluster.
If you enable the “Show Bull and Bear Count” option, you get an immediate reading of how many of the 20 horizons are stretched at any moment.
5) Cluster alerts and background tagging
Two alert conditions monitor “strong cluster” regimes:
RSI Heatmap Strong Bull – triggers when at least 10 RSIs are above 70.
RSI Heatmap Strong Bear – triggers when at least 10 RSIs are below 30.
When one of these conditions is true, the indicator can tint the background of the chart using a soft version of the current palette. This visually marks stretches where momentum is extreme across many lengths at once, not just on a single RSI.
What it plots
In one oscillator window, the indicator provides:
Up to 20 horizontal RSI strips, each representing a different RSI length.
Color-coded tiles reflecting the current RSI value for each length.
Group toggles to show or hide each block of five RSIs.
An optional white line that counts how many RSIs are above 70.
An optional black line that counts how many RSIs are below 30.
Optional background highlights when the number of overbought or oversold RSIs passes the strong-cluster threshold.
How it measures breadth and pressure
Single-symbol breadth
Breadth is usually defined across a basket of symbols, such as how many stocks advance versus decline. This indicator uses the same concept across time horizons for a single symbol. The question becomes:
“How many different RSI lengths are stretched in the same direction at once?”
Examples:
If only 2 or 3 of the shortest RSIs are above 70, bull count stays low. The move is fast and local, but not yet broadly supported.
If 12 or more RSIs across short, medium and long lengths are above 70, the bull count spikes. The move has broad momentum and strong upside pressure.
If 10 or more RSIs are below 30, bear count spikes and you are in a broad oversold regime.
This is breadth of momentum within one market.
Market pressure gauge
The combination of heatmap tiles and breadth lines acts as a pressure gauge:
High bull count with warm colors across most strips indicates strong upside pressure and crowded long positioning.
High bear count with cold colors across most strips indicates strong downside pressure and capitulation or forced selling.
Low counts with a mixed heatmap indicate neutral pressure, fragmented flows, or range-bound conditions.
You can treat the strong-cluster alerts as “extreme pressure” signals. When they fire, the market is heavily skewed in one direction across many horizons.
How to read the heatmap
Horizontal patterns (through time)
Look along the time axis and watch how the colors evolve:
Persistent hot tiles across many strips show sustained bullish pressure and trend strength.
Persistent cold tiles across many strips show sustained bearish pressure and weak demand.
Frequent flipping between hot and cold colours indicates a choppy or mean-reverting environment.
Vertical structure (across lengths at one bar)
Focus on a single bar and read the column of tiles from top to bottom:
Short RSIs hot, long RSIs neutral or cool: early trend or short-term fomo. Price has moved fast, longer horizons have not caught up.
Short and long RSIs all hot: mature, entrenched uptrend. Broad participation, high pressure, greater risk of blow-off or late-entry vulnerability.
Short RSIs cold but long RSIs mid to high: pullback in a higher timeframe uptrend. Dip-buy and continuation setups are often found here.
Short RSIs high but long RSIs low: countertrend rallies within a broader downtrend. Good hunting ground for fades and short entries after a bounce.
Bull and bear breadth lines
Use the two lines as simple, numeric breadth indicators:
A rising white line shows more RSIs pushing above 70, so bullish pressure is expanding in breadth.
A rising black line shows more RSIs pushing below 30, so bearish pressure is expanding in breadth.
When both lines are low and flat, few horizons are extreme and the market is in mid-range territory.
Cluster zones
When either count crosses the strong threshold (for example 10 out of 20 RSIs in extreme territory):
A strong bull cluster marks a broadly overbought regime. Trend followers may see this as confirmation. Mean-reversion traders may see it as a late-stage or blow-off context.
A strong bear cluster marks a broadly oversold regime. Downtrend traders see strong pressure, but the risk of sharp short-covering bounces also increases.
Trading applications
Trend confirmation
Use the heatmap and breadth lines as a trend filter:
Prefer long setups when the heatmap shows mostly mid to high RSIs and the bull count is rising.
Avoid fresh shorts when there is a strong bull cluster, unless you are specifically trading exhaustion.
Prefer short setups when the heatmap is mostly low RSIs and the bear count is rising.
Avoid aggressive longs when a strong bear cluster is active, unless you are trading reflexive bounces.
Mean-reversion timing
Treat cluster extremes as exhaustion zones:
Look for reversal patterns, failed breakouts, or order flow shifts when bull count is very high and price starts to stall or diverge.
Look for reflexive bounce potential when bear count is very high and price stops making new lows or shows absorption at the lows.
Use the palette and counts together: hot tiles plus a peaking white line can mark blow-off conditions, cold tiles plus a peaking black line can mark capitulation.
Regime detection and risk toggling
Use the overall shape of the ladder over time:
If upper strips stay warm and lower strips stay neutral or warm for extended periods, the market is in an uptrend regime. You can justify higher risk for long-biased strategies.
If upper strips stay cold and lower strips stay neutral or cold, the market is in a downtrend regime. You can justify higher risk for short-biased strategies or defensive positioning.
If colours and counts flip frequently, you are likely in a range or choppy regime. Consider reducing size or using more tactical, short-term strategies.
Multi-horizon synchronization
You can think of each RSI length as a proxy for a different “speed” of the same market:
When only fast RSIs are stretched, the move is local and less robust.
When fast, medium and slow RSIs align, the move has multi-horizon confirmation.
You can require a minimum bull or bear count before allowing your main strategy to engage.
Spotting hidden shifts
Sometimes price appears flat or drifting, but the heatmap quietly cools or warms:
If price is sideways while many hot tiles fade toward neutral, momentum is decaying under the surface and trend risk is increasing.
If price is sideways while many cold tiles climb back toward neutral, selling pressure is decaying and the tape is repairing itself.
Settings overview
Calculation Settings
RS Period – base RSI length for the shortest strip.
RSI Step – the increment added to each successive RSI length.
RSI Multiplier – scales all generated RSI lengths.
Calculation Source – the input series, such as close, hlc3 or others.
Plotting and Coloring Settings
Heatmap Color Palette – choose between Viridis, Jet, Plasma, Custom Heat, Gray, Cividis, Inferno, Magma, Turbo or Rainbow.
Show Group 1 – toggles RSI 1–5.
Show Group 2 – toggles RSI 6–10.
Show Group 3 – toggles RSI 11–15.
Show Group 4 – toggles RSI 16–20.
Show Bull and Bear Count – enables or disables the two breadth lines.
Alerts
RSI Heatmap Strong Bull – fires when the number of RSIs above 70 reaches or exceeds the configured threshold (default 10).
RSI Heatmap Strong Bear – fires when the number of RSIs below 30 reaches or exceeds the configured threshold (default 10).
Tuning guidance
Fast, tactical configurations
Use a small base RS Period, for example 2 to 5.
Use a small RSI Step, for tight clustering around the fast horizon.
Keep the multiplier near 1.0 to avoid extreme long lengths.
Focus on Group 1 and Group 2 for intraday and short-term trading.
Swing and position configurations
Use a mid-range RS Period, for example 7 to 14.
Use a moderate RSI Step to fan out into slower horizons.
Optionally use a multiplier slightly above 1.0.
Keep all four groups enabled for a full view from fast to slow.
Macro or higher timeframe configurations
Use a larger base RS Period.
Use a larger RSI Step so the top of the ladder reaches very slow lengths.
Focus on Group 3 and Group 4 to see structural momentum.
Treat clusters as regime markers rather than frequent trading signals.
Notes
This indicator is a contextual tool, not a standalone trading system. It does not model execution, spreads, slippage or fundamental drivers. Use it to:
Understand whether momentum is narrow or broad across horizons.
Confirm or filter existing signals from your primary strategy.
Identify environments where the market is crowded into one side.
Distinguish between isolated spikes and truly broad pressure moves.
The Relative Strength Heatmap is designed to answer a simple but powerful question:
“How many versions of RSI agree with what I am seeing on the chart?”
By compressing those answers into a single panel with clear colour coding and breadth lines, it becomes a practical, visual gauge of momentum breadth and market pressure that you can overlay on any trading framework.

Luxy BIG beautiful Dynamic ORBThis is an advanced Opening Range Breakout (ORB) indicator that tracks price breakouts from the first 5, 15, 30, and 60 minutes of the trading session. It provides complete trade management including entry signals, stop-loss placement, take-profit targets, and position sizing calculations.
The ORB strategy is based on the concept that the opening range of a trading session often acts as support/resistance, and breakouts from this range tend to lead to significant moves.
What Makes This Different?
Most ORB indicators simply draw horizontal lines and leave you to figure out the rest. This indicator goes several steps further:
Multi-Stage Tracking
Instead of just one ORB timeframe, this tracks FOUR simultaneously (5min, 15min, 30min, 60min). Each stage builds on the previous one, giving you multiple trading opportunities throughout the session.
Active Trade Management
When a breakout occurs, the indicator automatically calculates and displays entry price, stop-loss, and multiple take-profit targets. These lines extend forward and update in real-time until the trade completes.
Cycle Detection
Unlike indicators that only show the first breakout, this tracks the complete cycle: Breakout → Retest → Re-breakout. You can see when price returns to test the ORB level after breaking out (potential re-entry).
Failed Breakout Warning
If price breaks out but quickly returns inside the range (within a few bars), the label changes to "FAILED BREAK" - warning you to exit or avoid the trade.
Position Sizing Calculator
Built-in risk management that tells you exactly how many shares to buy based on your account size and risk tolerance. No more guessing or manual calculations.
Advanced Filtering
Optional filters for volume confirmation, trend alignment, and Fair Value Gaps (FVG) to reduce false signals and improve win rate.
Core Features Explained
### 1. Multi-Stage ORB Levels
The indicator builds four separate Opening Range levels:
ORB 5 - First 5 minutes (fastest signals, most volatile)
ORB 15 - First 15 minutes (balanced, most popular)
ORB 30 - First 30 minutes (slower, more reliable)
ORB 60 - First 60 minutes (slowest, most confirmed)
Each level is drawn as a horizontal range on your chart. As time progresses, the ranges expand to include more price action. You can enable or disable any stage and assign custom colors to each.
How it works: During the opening minutes, the indicator tracks the highest high and lowest low. Once the time period completes, those levels become your ORB high and low for that stage.
### 2. Breakout Detection
When price closes outside the ORB range, a label appears:
BREAK UP (green label above price) - Price closed above ORB High
BREAK DOWN (red label below price) - Price closed below ORB Low
The label shows which ORB stage triggered (ORB5, ORB15, etc.) and the cycle number if tracking multiple breakouts.
Important: Signals appear on bar close only - no repainting. What you see is what you get.
### 3. Retest Detection
After price breaks out and moves away, if it returns to test the ORB level, a "RETEST" label appears (orange). This indicates:
The original breakout level is now acting as support/resistance
Potential re-entry opportunity if you missed the first breakout
Confirmation that the level is significant
The indicator requires price to move a minimum distance away before considering it a valid retest (configurable in settings).
### 4. Failed Breakout Detection
If price breaks out but returns inside the ORB range within a few bars (before the breakout is "committed"), the original label changes to "FAILED BREAK" in orange.
This warns you:
The breakout lacked conviction
Consider exiting if already in the trade
Wait for better setup
Committed Breakout: The indicator tracks how many bars price stays outside the range. Only after staying outside for the minimum number of bars does it become a committed breakout that can be retested.
### 5. TP/SL Lines (Trade Management)
When a breakout occurs, colored horizontal lines appear showing:
Entry Line (cyan for long, orange for short) - Your entry price (the ORB level)
Stop Loss Line (red) - Where to exit if trade goes against you
TP1, TP2, TP3 Lines (same color as entry) - Profit targets at 1R, 2R, 3R
These lines extend forward as new bars form, making it easy to track your trade. When a target is hit, the line turns green and the label shows a checkmark.
Lines freeze (stop updating) when:
Stop loss is hit
The final enabled take-profit is hit
End of trading session (optional setting)
### 6. Position Sizing Dashboard
The dashboard (bottom-left corner by default) shows real-time information:
Current ORB stage and range size
Breakout status (Inside Range / Break Up / Break Down)
Volume confirmation (if filter enabled)
Trend alignment (if filter enabled)
Entry and Stop Loss prices
All enabled Take Profit levels with percentages
Risk/Reward ratio
Position sizing: Max shares to buy and total risk amount
Position Sizing Example:
If your account is $25,000 and you risk 1% per trade ($250), and the distance from entry to stop loss is $0.50, the calculator shows you can buy 500 shares (250 / 0.50 = 500).
### 7. FVG Filter (Fair Value Gap)
Fair Value Gaps are price inefficiencies - gaps left by strong momentum where one candle's high doesn't overlap with a previous candle's low (or vice versa).
When enabled, this filter:
Detects bullish and bearish FVGs
Draws semi-transparent boxes around these gaps
Only allows breakout signals if there's an FVG near the breakout level
Why this helps: FVGs indicate institutional activity. Breakouts through FVGs tend to be stronger and more reliable.
Proximity setting: Controls how close the FVG must be to the ORB level. 2.0x means the breakout can be within 2 times the FVG size - a reasonable default.
### 8. Volume & Trend Filters
Volume Filter:
Requires current volume to be above average (customizable multiplier). High volume breakouts are more likely to sustain.
Set minimum multiplier (e.g., 1.5x = 50% above average)
Set "strong volume" multiplier (e.g., 2.5x) that bypasses other filters
Dashboard shows current volume ratio
Trend Filter:
Only shows breakouts aligned with a higher timeframe trend. Choose from:
VWAP - Price above/below volume-weighted average
EMA - Price above/below exponential moving average
SuperTrend - ATR-based trend indicator
Combined modes (VWAP+EMA, VWAP+SuperTrend) for stricter filtering
### 9. Pullback Filter (Advanced)
Purpose:
Waits for price to pull back slightly after initial breakout before confirming the signal.
This reduces false breakouts from immediate reversals.
How it works:
- After breakout is detected, indicator waits for a small pullback (default 2%)
- Once pullback occurs AND price breaks out again, signal is confirmed
- If no pullback within timeout period (5 bars), signal is issued anyway
Settings:
Enable Pullback Filter: Turn this filter on/off
Pullback %: How much price must pull back (2% is balanced)
Timeout (bars): Max bars to wait for pullback (5 is standard)
When to use:
- Choppy markets with many fake breakouts
- When you want higher quality signals
- Combine with Volume filter for maximum confirmation
Trade-off:
- Better signal quality
- May miss some valid fast moves
- Slight entry delay
How to Use This Indicator
### For Beginners - Simple Setup
Add the indicator to your chart (5-minute or 15-minute timeframe recommended)
Leave all default settings - they work well for most stocks
Watch for BREAK UP or BREAK DOWN labels to appear
Check the dashboard for entry, stop loss, and targets
Use the position sizing to determine how many shares to buy
Basic Trading Plan:
Wait for a clear breakout label
Enter at the ORB level (or next candle open if you're late)
Place stop loss where the red line indicates
Take profit at TP1 (50% of position) and TP2 (remaining 50%)
### For Advanced Traders - Customized Setup
Choose which ORB stages to track (you might only want ORB15 and ORB30)
Enable filters: Volume (stocks) or Trend (trending markets)
Enable FVG filter for institutional confirmation
Set "Track Cycles" mode to catch retests and re-breakouts
Customize stop loss method (ATR for volatile stocks, ORB% for stable ones)
Adjust risk per trade and account size for accurate position sizing
Advanced Strategy Example:
Enable ORB15 only (disable others for cleaner chart)
Turn on Volume filter at 1.5x with Strong at 2.5x
Enable Trend filter using VWAP
Set Signal Mode to "Track Cycles" with Max 3 cycles
Wait for aligned breakouts (Volume + Trend + Direction)
Enter on retest if you missed the initial break
### Timeframe Recommendations
5-minute chart: Scalping, very active trading, crypto
15-minute chart: Day trading, balanced approach (most popular)
30-minute chart: Swing entries, less screen time
60-minute chart: Position trading, longer holds
The indicator works on any intraday timeframe, but ORB is fundamentally a day trading strategy. Daily charts don't make sense for ORB.
DEFAULT CONFIGURATION
ON by Default:
• All 4 ORB stages (5/15/30/60)
• Breakout Detection
• Retest Labels
• All TP levels (1/1.5/2/3)
• TP/SL Lines (Detailed mode)
• Dashboard (Bottom Left, Dark theme)
• Position Size Calculator
OFF by Default (Optional Filters):
• FVG Filter
• Pullback Filter
• Volume Filter
• Trend Filter
• HTF Bias Check
• Alerts
Recommended for Beginners:
• Leave all defaults
• Session Mode: Auto-Detect
• Signal Mode: Track Cycles
• Stop Method: ATR
• Add Volume Filter if trading stocks
Recommended for Advanced:
• Enable ORB15 + ORB30 only (disable 5 & 60)
• Enable: Volume + Trend + FVG
• Signal Mode: Track Cycles, Max 3
• Stop Method: ATR or Safer
• Enable HTF Daily bias check
## Settings Guide
The settings are organized into logical groups. Here's what each section controls:
### ORB COLORS Section
Show Edge Labels: Display "ORB 5", "ORB 15" labels at the right edge of the levels
Background: Fill the area between ORB high/low with color
Transparency: How see-through the background is (95% is nearly invisible)
Enable ORB 5/15/30/60: Turn each stage on or off individually
Colors: Assign colors to each ORB stage for easy identification
### SESSION SETTINGS Section
Session Mode: Choose trading session (Auto-Detect works for most instruments)
Custom Session Hours: Define your own hours if needed (format: HHMM-HHMM)
Auto-Detect uses the instrument's natural hours (stocks use exchange hours, crypto uses 24/7).
### BREAKOUT DETECTION Section
Enable Breakout Detection: Master switch for signals
Show Retest Labels: Display retest signals
Label Size: Visual size for all labels (Small recommended)
Enable FVG Filter: Require Fair Value Gap confirmation
Show FVG Boxes: Display the gap boxes on chart
Signal Mode: "First Only" = one signal per direction per day, "Track Cycles" = multiple signals
Max Cycles: How many breakout-retest cycles to track (6 is balanced)
Breakout Buffer: Extra distance required beyond ORB level (0.1-0.2% recommended)
Min Distance for Retest: How far price must move away before retest is valid (2% recommended)
Min Bars Outside ORB: Bars price must stay outside for committed breakout (2 is balanced)
### TARGETS & RISK Section
Enable Targets & Stop-Loss: Calculate and show trade management
TP1/TP2/TP3 checkboxes: Select which profit targets to display
Stop Method: How to calculate stop loss placement
- ATR: Based on volatility (best for most cases)
- ORB %: Fixed % of ORB range
- Swing: Recent swing high/low
- Safer: Widest of all methods
ATR Length & Multiplier: Controls ATR stop distance (14 period, 1.5x is standard)
ORB Stop %: Percentage beyond ORB for stop (20% is balanced)
Swing Bars: Lookback period for swing high/low (3 is recent)
### TP/SL LINES Section
Show TP/SL Lines: Display horizontal lines on chart
Label Format: "Short" = minimal text, "Detailed" = shows prices
Freeze Lines at EOD: Stop extending lines at session close
### DASHBOARD Section
Show Info Panel: Display the metrics dashboard
Theme: Dark or Light colors
Position: Where to place dashboard on chart
Toggle rows: Show/hide specific information rows
Calculate Position Size: Enable the position sizing calculator
Risk Mode: Risk fixed $ amount or % of account
Account Size: Your total trading capital
Risk %: Percentage to risk per trade (0.5-1% recommended)
### VOLUME FILTER Section
Enable Volume Filter: Require volume confirmation
MA Length: Average period (20 is standard)
Min Volume: Required multiplier (1.5x = 50% above average)
Strong Volume: Multiplier that bypasses other filters (2.5x)
### TREND FILTER Section
Enable Trend Filter: Require trend alignment
Trend Mode: Method to determine trend (VWAP is simple and effective)
Custom EMA Length: If using EMA mode (50 for swing, 20 for day trading)
SuperTrend settings: Period and Multiplier if using SuperTrend mode
### HIGHER TIMEFRAME Section
Check Daily Trend: Display higher timeframe bias in dashboard
Timeframe: What TF to check (D = daily, recommended)
Method: Price vs MA (stable) or Candle Direction (reactive)
MA Period: EMA length for Price vs MA method (20 is balanced)
Min Strength %: Minimum strength threshold for HTF bias to be considered
- For "Price vs MA": Minimum distance (%) from moving average
- For "Candle Direction": Minimum candle body size (%)
- 0.5% is balanced - increase for stricter filtering
- Lower values = more signals, higher values = only strong trends
### ALERTS Section
Enable Alerts: Master switch (must be ON to use any alerts)
Breakout Alerts: Notify on ORB breakouts
Retest Alerts: Notify when price retests after breakout
Failed Break Alerts: Notify on failed breakouts
Stage Complete Alerts: Notify when each ORB stage finishes forming
After enabling desired alert types, click "Create Alert" button, select this indicator, choose "Any alert() function call".
## Tips & Best Practices
### General Trading Tips
ORB works best on liquid instruments (stocks with good volume, major crypto pairs)
First hour of the session is most important - that's when ORB is forming
Breakouts WITH the trend have higher success rates - use the trend filter
Failed breakouts are common - use the "Min Bars Outside" setting to filter weak moves
Not every day produces good ORB setups - be patient and selective
### Position Sizing Best Practices
Never risk more than 1-2% of your account on a single trade
Use the built-in calculator - don't guess your position size
Update your account size monthly as it grows
Smaller accounts: use $ Amount mode for simplicity
Larger accounts: use % of Account mode for scaling
### Take Profit Strategy
Most traders use: 50% at TP1, 50% at TP2
Aggressive: Hold through TP1 for TP2 or TP3
Conservative: Full exit at TP1 (1:1 risk/reward)
After TP1 hits, consider moving stop to breakeven
TP3 rarely hits - only on strong trending days
### Filter Combinations
Maximum Quality: Volume + Trend + FVG (fewest signals, highest quality)
Balanced: Volume + Trend (good quality, reasonable frequency)
Active Trading: No filters or Volume only (many signals, lower quality)
Trending Markets: Trend filter essential (indices, crypto)
Range-Bound: Volume + FVG (avoid trend filter)
### Common Mistakes to Avoid
Chasing breakouts - wait for the bar to close, don't FOMO into wicks
Ignoring the stop loss - always use it, move it manually if needed
Over-leveraging - the calculator shows MAX shares, you can buy less
Trading every signal - quality > quantity, use filters
Not tracking results - keep a journal to see what works for YOU
## Pros and Cons
### Advantages
Complete all-in-one solution - from signal to position sizing
Multiple timeframes tracked simultaneously
Visual clarity - easy to see what's happening
Cycle tracking catches opportunities others miss
Built-in risk management eliminates guesswork
Customizable filters for different trading styles
No repainting - what you see is locked in
Works across multiple markets (stocks, forex, crypto)
### Limitations
Intraday strategy only - doesn't work on daily charts
Requires active monitoring during first 1-2 hours of session
Not suitable for after-hours or extended sessions by default
Can produce many signals in choppy markets (use filters)
Dashboard can be overwhelming for complete beginners
Performance depends on market conditions (trends vs ranges)
Requires understanding of risk management concepts
### Best For
Day traders who can watch the first 1-2 hours of market open
Traders who want systematic entry/exit rules
Those learning proper position sizing and risk management
Active traders comfortable with multiple signals per day
Anyone trading liquid instruments with clear sessions
### Not Ideal For
Swing traders holding multi-day positions
Set-and-forget / passive investors
Traders who can't watch market open
Complete beginners unfamiliar with trading concepts
Low volume / illiquid instruments
## Frequently Asked Questions
Q: Why are no signals appearing?
A: Check that you're on an intraday timeframe (5min, 15min, etc.) and that the current time is within your session hours. Also verify that "Enable Breakout Detection" is ON and at least one ORB stage is enabled. If using filters, they might be blocking signals - try disabling them temporarily.
Q: What's the best ORB stage to use?
A: ORB15 (15 minutes) is most popular and balanced. ORB5 gives faster signals but more noise. ORB30 and ORB60 are slower but more reliable. Many traders use ORB15 + ORB30 together.
Q: Should I enable all the filters?
A: Start with no filters to see all signals. If too many false signals, add Volume filter first (stocks) or Trend filter (trending markets). FVG filter is most restrictive - use for maximum quality but fewer signals.
Q: How do I know which stop loss method to use?
A: ATR works for most cases - it adapts to volatility. Use ORB% if you want predictable stop placement. Swing is for respecting chart structure. Safer gives you the most room but largest risk.
Q: Can I use this for swing trading?
A: Not really - ORB is fundamentally an intraday strategy. The ranges reset each day. For swing trading, look at weekly support/resistance or moving averages instead.
Q: Why do TP/SL lines disappear sometimes?
A: Lines freeze (stop extending) when: stop loss is hit, the last enabled take-profit is hit, or end of session arrives (if "Freeze at EOD" is enabled). This is intentional - the trade is complete.
Q: What's the difference between "First Only" and "Track Cycles"?
A: "First Only" shows one breakout UP and one DOWN per day maximum - clean but might miss opportunities. "Track Cycles" shows breakout-retest-rebreak sequences - more signals but busier chart.
Q: Is position sizing accurate for options/forex?
A: The calculator is designed for shares (stocks). For options, ignore the share count and use the risk amount. For forex, you'll need to adapt the lot size calculation manually.
Q: How much capital do I need to use this?
A: The indicator works for any account size, but practical day trading typically requires $25,000 in the US due to Pattern Day Trader rules. Adjust the "Account Size" setting to match your capital.
Q: Can I backtest this strategy?
A: This is an indicator, not a strategy script, so it doesn't have built-in backtesting. You can visually review historical signals or code a strategy script using similar logic.
Q: Why does the dashboard show different entry price than the breakout label?
A: If you're looking at an old breakout, the ORB levels may have changed when the next stage completed. The dashboard always shows the CURRENT active range and trade setup.
Q: What's a good win rate to expect?
A: ORB strategies typically see 40-60% win rate depending on market conditions and filters used. The strategy relies on positive risk/reward ratios (2:1 or better) to be profitable even with moderate win rates.
Q: Does this work on crypto?
A: Yes, but crypto trades 24/7 so you need to define what "session start" means. Use Session Mode = Custom and set your preferred daily reset time (e.g., 0000-2359 UTC).
## Credits & Transparency
### Development
This indicator was developed with the assistance of AI technology to implement complex ORB trading logic.
The strategy concept, feature specifications, and trading logic were designed by the publisher. The implementation leverages modern development tools to ensure:
Clean, efficient, and maintainable code
Comprehensive error handling and input validation
Detailed documentation and user guidance
Performance optimization
### Trading Concepts
This indicator implements several public domain trading concepts:
Opening Range Breakout (ORB): Trading strategy popularized by Toby Crabel, Mark Fisher and many more talanted traders.
Fair Value Gap (FVG): Price imbalance concept from ICT methodology
SuperTrend: ATR-based trend indicator using public formula
Risk/Reward Ratio: Standard risk management principle
All mathematical formulas and technical concepts used are in the public domain.
### Pine Script
Uses standard TradingView built-in functions:
ta.ema(), ta.atr(), ta.vwap(), ta.highest(), ta.lowest(), request.security()
No external libraries or proprietary code from other authors.
## Disclaimer
This indicator is provided for educational and informational purposes only. It is not financial advice.
Trading involves substantial risk of loss and is not suitable for every investor. Past performance shown in examples is not indicative of future results.
The indicator provides signals and calculations, but trading decisions are solely your responsibility. Always:
Test strategies on paper before using real money
Never risk more than you can afford to lose
Understand that all trading involves risk
Consider seeking advice from a licensed financial advisor
The publisher makes no guarantees regarding accuracy, profitability, or performance. Use at your own risk.
---
Version: 3.0
Pine Script Version: v6
Last Updated: October 2024
For support, questions, or suggestions, please comment below or send a private message.
---
Happy trading, and remember: consistent risk management beats perfect entry timing every time.

Free Stock ScreenerMissing great trade opportunities is annoying, and unless you have 12 screens or only trade one market, you are missing a lot of trades. To fix that, we created this free stock screener so you get notified instantly of potential great trading conditions in real time, right on your chart.
You get notified of trading benchmarks being met by the value being displayed on the scanner as well as a color change so that it grabs your attention and makes you aware that you should take a look at the other market and look for a potential trade. It also has built in alerts so you can have an alert notification go off when any of your trading conditions are met instead of needing to watch the scanner for color changes.
The screener will change the ticker symbol background color to red green when price is above or below the previous daily range and above or below both VWAPs. This signals that the ticker is trending, which typically means it is a great time to trade that market and follow the trend.
This free stock screener allows you to scan up to 10 different markets at the same time for various different conditions so you always know what is going on with your favorite trading symbols. If you want to scan more tickers, just add the indicator to your chart again and change the table position to the other side of the screen and update the tickers on the 2nd screener, allowing you to have 20 tickers at a time.
The scanner can be fully customized by changing the markets that it screens and turning on or off as many of them as you would like. You can also turn on or off any of the different data sets so that you only get information about trading conditions that matter to you.
The screener can provide data on any type of market, such as stocks, crypto, futures, forex and more. Each ticker can be adjusted to whatever market you would like it to scan for data in the settings panel, the only limitation is that it will not provide data for the VWAP and volume trend score if the ticker you are screening does not provide volume data.
Screener Features
The scanner will provide the following types of data for each ticker that is turned on:
Volume - Provides a volume score compared to the average volume and notifies you of higher than normal volume and volume spikes on individual bars by changing colors.
Volatility - Provides a volatility score compared to the average volatility and notifies you of higher than normal volatility by changing colors.
Oscillator - Choose between the RSI or CCI. The value of that oscillator will be displayed and will notify you when values are in extreme ranges such as overbought or oversold conditions according to the threshold values you enter in the settings panel. When those thresholds have been breached, you will be notified by it changing color.
Big Candles - Compares the current candle to average previous candle sizes, and changes color to notify you of big candles including a big top wick, big bottom wick, big candle body and big candle high to low range.
Daily Level Touches & Trends - Calculates and displays various daily candle and intraday open price levels that act as support and resistance. Notifies you when price is touching any of the daily levels that are turned on. The levels you can have on are as follows: previous day high, previous day low or previous day open. It also will notify you when price is touching the current day’s open, NY 930am open, Asia 8pm open, London 2am open and NY midnight 12am open. It will also say “Above” if price is above the previous day’s high or it will say “Below” if price is below the previous day’s low. The color of the cell will also change when a level touch is happening or price is above the previous day high or below the previous day low.
VWAP - Choose from 2 different VWAP lengths, default settings are daily and weekly VWAPs. You will get notified if price touches either of the VWAPs and they will also say “Above” or “Below” if price is currently above or below each VWAP.
How To Use The Screener To Help You Trade
The main purpose of the screener is to scan other markets and notify you of potential good trading opportunities such as price bouncing off of the daily levels or VWAPs. It can also be used to know when price is trending according to the VWAPs and daily levels. Lastly, you can use it to know how the volume and volatility trends are currently which gives you more confidence in taking a trade with this data when volume and volatility are present.
Volume Score
When volume is high, this represents a good time to trade because there are many market participants and price is likely to be volatile while there is high volume which can present a lot of good trade setups for you to take.
The volume score shown on the screener measures the current volume trend compared to previous volume trends and calculates that into a score based on 100 being the same as the previous volume trend. So any value above 100 means it is high volume and any value less than 100 means it is lower volume than normal.
In the settings panel, you can adjust the volume threshold that needs to be met for a volume notification to show up. The default setting is at 120, so you will get notified when the current volume trend score is 120 or higher or you can adjust that threshold value to whatever value you prefer.
It also will notify you when there is a volume spike on the current bar. This is determined by calculating an average of the recent volume totals and then checking to see if the current bar is greater than or equal to that average multiplied by 3. So if a single bar has volume that is greater than 3 times what the average volume is, then you will get a notification that says “Spike” to make you aware of that volume spike.
The volume trend threshold, volume spike multiplier and lookback length for the average volume used in volume spike calculations can all be adjusted in the settings panel to fit your desired preferences.
Volatility Score
High volatility can mean it is a great time to trade because the market is moving quickly and providing large enough movements that you can get in and out in a short amount of time, while still accruing decent sized trade PnL.
The volatility score will calculate the current volatility for each market compared to previous conditions and then divide the current volatility by the average volatility to give you a volatility score. Anything over 100 means the market is decently volatile and you should look at that market to find potential trade setups to execute on. Anything below 100 means the market is not very volatile and it is usually best to just wait until volatility returns before you start trading again.
The screener will notify you when the volatility score is above the threshold you set. The default value is set to 90, but can be adjusted to your preference. Pay attention to any market that shows an alert and take a look at that chart because the high volatility may present a good trade setup for you in the near future.
Oscillator Score
The oscillator data can be switched between Relative Strength Index(RSI) and Commodity Channel Index(CCI).
The RSI provides a value between 0 and 100 that indicates the momentum and strength of the recent price action. Many traders use the extremes of the 0-100 range to signal overbought or oversold conditions and use that as a sign to look for price to reverse in the near future. The typical values used for this and the default settings to provide notifications are: 70 for overbought and 30 for oversold. The scanner will notify you when the RSI value is considered overbought or oversold so you know to take a look at the chart and analyze if it is ready for a trade to be taken.
The CCI provides a value that can be used to determine the trend strength of the underlying asset when the oscillator moves above 100 or below -100. These extreme values are outside of the normal accumulation range and signify that price is moving strongly in that direction so it may be a good time to take a trade in the direction of the trend. The scanner will show you the value of the CCI for each market and notify you if that value is above 100 or below -100.
Both RSI and CCI settings can be adjusted in the settings panel to your desired settings so you have the exact oscillator settings you prefer to use as well as the exact values that you want to use for being notified.
Big Candles
Big candles can mean that many traders are buying or selling at the same time and many times indicate a good signal to trade in that same direction. That is why we included this calculation in the screener, so you are always aware when a large candle prints.
It calculates the average size of the recent candles and then uses that average as the benchmark to determine if the current candle is considered big and worthy of notifying you to take a look at that chart.
You can adjust the multiplier used for the big candle threshold to whatever you desire, but the default setting is 3 which means the candle will be considered big and notify you if it is 3 times as large as an average candle.
The big candles data will track the following candle values and notify you with these labels:
High to Low candle size = HL
Candle Body from open to close candle size = OC
Top Wick size = TW
Bottom Wick size = BW
Daily Level Touches & Trend
Daily level touches are excellent levels to watch for price to bounce because they often act as support and resistance levels for intraday trading. The scanner will track each market and notify you when the current candle is touching any of the daily levels that you have turned on in the settings panel.
The main levels that are turned on by default and are useful for all markets and how they will be labeled on the scanner are as follows:
Previous Day High = High
Previous Day Low = Low
Previous Day Open = < Open
Previous Day Close = Close
Current Day Open = Open
We also included some extra levels that are useful for futures traders. They are as follows:
NY 930am Open = 930am
NY 12am Midnight Open = 12am
Asia Open at 8pm NY time = Asia
London Open at 2am NY Time = London
Watch how price reacts to these levels and then trade the bounces off of these levels if the price action confirms that it is going to respect that level.
When price is currently above the previous day high, the scanner will say “Above” and show a green color, indicating a bullish trend and that price is above the previous daily candle’s high.
When price is currently below the previous day low, the scanner will say “Below” and show a red color, indicating a bearish trend and that price is below the previous daily candle’s low.
Pay attention to when price is trending above or below the previous daily candle as those trends can provide excellent trend trading opportunities.
The daily levels that you have turned on in the settings will also show as lines on the chart and include a label next to them, identifying each level so you know what each line represents. You can turn on or off all of the lines shown on the chart in the main settings or turn them off one by one in the style panel of the settings. Labels can also be turned on or off for all of the lines in the main settings panel. You can adjust the label positioning in the Label Offset section of the settings panel.
VWAP Touches & Trend
VWAP stands for volume weighted average price and is a very popular tool that traders use to determine trend direction based on volume as well as an excellent level to trade price bounces off of.
The typical VWAP time period used is Daily, which means the volume weighted average price will reset at the beginning of a new day. We set the first VWAP to be the daily VWAP by default and the second one to be the weekly VWAP. You can adjust both of the time periods to be any of the provided time lengths that you choose.
The screener will show “Above” with a green background color when price is above the VWAP, indicating a bullish trend. It will show “Below” with a red background color when price is below the VWAP, indicating a bearish trend. When both VWAPs are showing Above or Below, you can expect price to trend in that direction, so look for pullbacks you can trade in the direction of the trend. If the VWAPs are showing different directions, then you should expect to bounce back and forth between the VWAPs, but be careful and watch out for price to break beyond either one and start a trend.
When the current candle is touching the VWAP, the scanner will change colors and say VWAP to notify you that price is touching the VWAP and you should look at that chart and analyze the market for a potential bounce off of the VWAP to trade.
Trending Market Signals
Strong trends are excellent markets to trade and can many times provide excellent trading opportunities that don’t require expert price action reading skills to be able to take winning trades from. That is why we included a signal to notify you of a strong trending market.
The strong trending market will show up as a green or red background color for the ticker name. If the color of the ticker name is green, it is notifying you that the price is above the previous daily high, above VWAP 1 and above VWAP 2 and is a good market to look for bullish trend trades. If the color of the ticker name is red, it is notifying you that the price is below the previous daily low, below VWAP 1 and below VWAP 2 and is a good market to look for bearish trend trades.
Changing The Tickers It Scans
To change the tickers that the indicator scans, scroll near the bottom of the settings panel and select the ticker symbol you want to update and then search for the exact symbol you want to use. If you want to scan less tickers, then just turn some of the tickers off that you don’t need.
Scanning More Than 10 Tickers
If you want to scan more than 10 tickers, you can add the scanner to your chart again and then just change the table position to the other side of the screen. This will allow you to scan 10 more tickers that will show up separately. Then if you want even more, just add the indicator to your chart again and update the table position until you have as many markets as you want. The table position setting can be found at the bottom of the main settings panel.
Alerts
The screener has alerts that can be used to notify you when any of the data set thresholds have been met or if price is touching one of the levels. You can set alerts for the following events:
Bullish Trend Alert - Price is above the previous daily high and above both VWAPs.
Bearish Trend Alert - Price is below the previous daily low and below both VWAPs.
High Volume Alert - Volume is higher than the threshold or a volume spike is detected.
High Volatility Alert - Volatility is higher than the threshold.
Oscillator Is Extended Alert - Oscillator value has exceeded the upper or lower threshold.
Big Candle Alert - A big candle has been detected.
Daily Level Touch Alert - One of the daily levels that is turned on is being touched.
VWAP Touch Alert - One of the 2 VWAPs are being touched.
An alert will trigger when any one of tickers on your scanner meets the alert conditions, so when you see the alert, you will need to go to your chart and look at the scanner to see which ticker it was and then navigate to that chart to look for potential trade setups.
The alerts will use the exact same settings you have configured in the settings panel to send you alert notifications. With normal settings, this could give you a lot of alerts, so if you only want alerts to fire when abnormal conditions are being met, try setting up a second screener on your chart that has very high threshold values and only has the most important level touches on. Then turn the setting "Do Not Show The Screener On The Chart" to off so the calculations will still run and fire alerts, but won't clog up your charts. This way you can only get alert notifications when major events happen but still have your normal screener settings available on your chart.
Markets This Can Be Used On
This screener uses the price action and volume data so you can use it to scan any type of market you would like as long as the ticker you are scanning has price and volume data feeds. If a market does not have volume data, then it will just show NaN in the volume row and the VWAP rows will not show anything.

Dynamic Equity Allocation Model"Cash is Trash"? Not Always. Here's Why Science Beats Guesswork.
Every retail trader knows the frustration: you draw support and resistance lines, you spot patterns, you follow market gurus on social media—and still, when the next bear market hits, your portfolio bleeds red. Meanwhile, institutional investors seem to navigate market turbulence with ease, preserving capital when markets crash and participating when they rally. What's their secret?
The answer isn't insider information or access to exotic derivatives. It's systematic, scientifically validated decision-making. While most retail traders rely on subjective chart analysis and emotional reactions, professional portfolio managers use quantitative models that remove emotion from the equation and process multiple streams of market information simultaneously.
This document presents exactly such a system—not a proprietary black box available only to hedge funds, but a fully transparent, academically grounded framework that any serious investor can understand and apply. The Dynamic Equity Allocation Model (DEAM) synthesizes decades of financial research from Nobel laureates and leading academics into a practical tool for tactical asset allocation.
Stop drawing colorful lines on your chart and start thinking like a quant. This isn't about predicting where the market goes next week—it's about systematically adjusting your risk exposure based on what the data actually tells you. When valuations scream danger, when volatility spikes, when credit markets freeze, when multiple warning signals align—that's when cash isn't trash. That's when cash saves your portfolio.
The irony of "cash is trash" rhetoric is that it ignores timing. Yes, being 100% cash for decades would be disastrous. But being 100% equities through every crisis is equally foolish. The sophisticated approach is dynamic: aggressive when conditions favor risk-taking, defensive when they don't. This model shows you how to make that decision systematically, not emotionally.
Whether you're managing your own retirement portfolio or seeking to understand how institutional allocation strategies work, this comprehensive analysis provides the theoretical foundation, mathematical implementation, and practical guidance to elevate your investment approach from amateur to professional.
The choice is yours: keep hoping your chart patterns work out, or start using the same quantitative methods that professionals rely on. The tools are here. The research is cited. The methodology is explained. All you need to do is read, understand, and apply.
The Dynamic Equity Allocation Model (DEAM) is a quantitative framework for systematic allocation between equities and cash, grounded in modern portfolio theory and empirical market research. The model integrates five scientifically validated dimensions of market analysis—market regime, risk metrics, valuation, sentiment, and macroeconomic conditions—to generate dynamic allocation recommendations ranging from 0% to 100% equity exposure. This work documents the theoretical foundations, mathematical implementation, and practical application of this multi-factor approach.
1. Introduction and Theoretical Background
1.1 The Limitations of Static Portfolio Allocation
Traditional portfolio theory, as formulated by Markowitz (1952) in his seminal work "Portfolio Selection," assumes an optimal static allocation where investors distribute their wealth across asset classes according to their risk aversion. This approach rests on the assumption that returns and risks remain constant over time. However, empirical research demonstrates that this assumption does not hold in reality. Fama and French (1989) showed that expected returns vary over time and correlate with macroeconomic variables such as the spread between long-term and short-term interest rates. Campbell and Shiller (1988) demonstrated that the price-earnings ratio possesses predictive power for future stock returns, providing a foundation for dynamic allocation strategies.
The academic literature on tactical asset allocation has evolved considerably over recent decades. Ilmanen (2011) argues in "Expected Returns" that investors can improve their risk-adjusted returns by considering valuation levels, business cycles, and market sentiment. The Dynamic Equity Allocation Model presented here builds on this research tradition and operationalizes these insights into a practically applicable allocation framework.
1.2 Multi-Factor Approaches in Asset Allocation
Modern financial research has shown that different factors capture distinct aspects of market dynamics and together provide a more robust picture of market conditions than individual indicators. Ross (1976) developed the Arbitrage Pricing Theory, a model that employs multiple factors to explain security returns. Following this multi-factor philosophy, DEAM integrates five complementary analytical dimensions, each tapping different information sources and collectively enabling comprehensive market understanding.
2. Data Foundation and Data Quality
2.1 Data Sources Used
The model draws its data exclusively from publicly available market data via the TradingView platform. This transparency and accessibility is a significant advantage over proprietary models that rely on non-public data. The data foundation encompasses several categories of market information, each capturing specific aspects of market dynamics.
First, price data for the S&P 500 Index is obtained through the SPDR S&P 500 ETF (ticker: SPY). The use of a highly liquid ETF instead of the index itself has practical reasons, as ETF data is available in real-time and reflects actual tradability. In addition to closing prices, high, low, and volume data are captured, which are required for calculating advanced volatility measures.
Fundamental corporate metrics are retrieved via TradingView's Financial Data API. These include earnings per share, price-to-earnings ratio, return on equity, debt-to-equity ratio, dividend yield, and share buyback yield. Cochrane (2011) emphasizes in "Presidential Address: Discount Rates" the central importance of valuation metrics for forecasting future returns, making these fundamental data a cornerstone of the model.
Volatility indicators are represented by the CBOE Volatility Index (VIX) and related metrics. The VIX, often referred to as the market's "fear gauge," measures the implied volatility of S&P 500 index options and serves as a proxy for market participants' risk perception. Whaley (2000) describes in "The Investor Fear Gauge" the construction and interpretation of the VIX and its use as a sentiment indicator.
Macroeconomic data includes yield curve information through US Treasury bonds of various maturities and credit risk premiums through the spread between high-yield bonds and risk-free government bonds. These variables capture the macroeconomic conditions and financing conditions relevant for equity valuation. Estrella and Hardouvelis (1991) showed that the shape of the yield curve has predictive power for future economic activity, justifying the inclusion of these data.
2.2 Handling Missing Data
A practical problem when working with financial data is dealing with missing or unavailable values. The model implements a fallback system where a plausible historical average value is stored for each fundamental metric. When current data is unavailable for a specific point in time, this fallback value is used. This approach ensures that the model remains functional even during temporary data outages and avoids systematic biases from missing data. The use of average values as fallback is conservative, as it generates neither overly optimistic nor pessimistic signals.
3. Component 1: Market Regime Detection
3.1 The Concept of Market Regimes
The idea that financial markets exist in different "regimes" or states that differ in their statistical properties has a long tradition in financial science. Hamilton (1989) developed regime-switching models that allow distinguishing between different market states with different return and volatility characteristics. The practical application of this theory consists of identifying the current market state and adjusting portfolio allocation accordingly.
DEAM classifies market regimes using a scoring system that considers three main dimensions: trend strength, volatility level, and drawdown depth. This multidimensional view is more robust than focusing on individual indicators, as it captures various facets of market dynamics. Classification occurs into six distinct regimes: Strong Bull, Bull Market, Neutral, Correction, Bear Market, and Crisis.
3.2 Trend Analysis Through Moving Averages
Moving averages are among the oldest and most widely used technical indicators and have also received attention in academic literature. Brock, Lakonishok, and LeBaron (1992) examined in "Simple Technical Trading Rules and the Stochastic Properties of Stock Returns" the profitability of trading rules based on moving averages and found evidence for their predictive power, although later studies questioned the robustness of these results when considering transaction costs.
The model calculates three moving averages with different time windows: a 20-day average (approximately one trading month), a 50-day average (approximately one quarter), and a 200-day average (approximately one trading year). The relationship of the current price to these averages and the relationship of the averages to each other provide information about trend strength and direction. When the price trades above all three averages and the short-term average is above the long-term, this indicates an established uptrend. The model assigns points based on these constellations, with longer-term trends weighted more heavily as they are considered more persistent.
3.3 Volatility Regimes
Volatility, understood as the standard deviation of returns, is a central concept of financial theory and serves as the primary risk measure. However, research has shown that volatility is not constant but changes over time and occurs in clusters—a phenomenon first documented by Mandelbrot (1963) and later formalized through ARCH and GARCH models (Engle, 1982; Bollerslev, 1986).
DEAM calculates volatility not only through the classic method of return standard deviation but also uses more advanced estimators such as the Parkinson estimator and the Garman-Klass estimator. These methods utilize intraday information (high and low prices) and are more efficient than simple close-to-close volatility estimators. The Parkinson estimator (Parkinson, 1980) uses the range between high and low of a trading day and is based on the recognition that this information reveals more about true volatility than just the closing price difference. The Garman-Klass estimator (Garman and Klass, 1980) extends this approach by additionally considering opening and closing prices.
The calculated volatility is annualized by multiplying it by the square root of 252 (the average number of trading days per year), enabling standardized comparability. The model compares current volatility with the VIX, the implied volatility from option prices. A low VIX (below 15) signals market comfort and increases the regime score, while a high VIX (above 35) indicates market stress and reduces the score. This interpretation follows the empirical observation that elevated volatility is typically associated with falling markets (Schwert, 1989).
3.4 Drawdown Analysis
A drawdown refers to the percentage decline from the highest point (peak) to the lowest point (trough) during a specific period. This metric is psychologically significant for investors as it represents the maximum loss experienced. Calmar (1991) developed the Calmar Ratio, which relates return to maximum drawdown, underscoring the practical relevance of this metric.
The model calculates current drawdown as the percentage distance from the highest price of the last 252 trading days (one year). A drawdown below 3% is considered negligible and maximally increases the regime score. As drawdown increases, the score decreases progressively, with drawdowns above 20% classified as severe and indicating a crisis or bear market regime. These thresholds are empirically motivated by historical market cycles, in which corrections typically encompassed 5-10% drawdowns, bear markets 20-30%, and crises over 30%.
3.5 Regime Classification
Final regime classification occurs through aggregation of scores from trend (40% weight), volatility (30%), and drawdown (30%). The higher weighting of trend reflects the empirical observation that trend-following strategies have historically delivered robust results (Moskowitz, Ooi, and Pedersen, 2012). A total score above 80 signals a strong bull market with established uptrend, low volatility, and minimal losses. At a score below 10, a crisis situation exists requiring defensive positioning. The six regime categories enable a differentiated allocation strategy that not only distinguishes binarily between bullish and bearish but allows gradual gradations.
4. Component 2: Risk-Based Allocation
4.1 Volatility Targeting as Risk Management Approach
The concept of volatility targeting is based on the idea that investors should maximize not returns but risk-adjusted returns. Sharpe (1966, 1994) defined with the Sharpe Ratio the fundamental concept of return per unit of risk, measured as volatility. Volatility targeting goes a step further and adjusts portfolio allocation to achieve constant target volatility. This means that in times of low market volatility, equity allocation is increased, and in times of high volatility, it is reduced.
Moreira and Muir (2017) showed in "Volatility-Managed Portfolios" that strategies that adjust their exposure based on volatility forecasts achieve higher Sharpe Ratios than passive buy-and-hold strategies. DEAM implements this principle by defining a target portfolio volatility (default 12% annualized) and adjusting equity allocation to achieve it. The mathematical foundation is simple: if market volatility is 20% and target volatility is 12%, equity allocation should be 60% (12/20 = 0.6), with the remaining 40% held in cash with zero volatility.
4.2 Market Volatility Calculation
Estimating current market volatility is central to the risk-based allocation approach. The model uses several volatility estimators in parallel and selects the higher value between traditional close-to-close volatility and the Parkinson estimator. This conservative choice ensures the model does not underestimate true volatility, which could lead to excessive risk exposure.
Traditional volatility calculation uses logarithmic returns, as these have mathematically advantageous properties (additive linkage over multiple periods). The logarithmic return is calculated as ln(P_t / P_{t-1}), where P_t is the price at time t. The standard deviation of these returns over a rolling 20-trading-day window is then multiplied by √252 to obtain annualized volatility. This annualization is based on the assumption of independently identically distributed returns, which is an idealization but widely accepted in practice.
The Parkinson estimator uses additional information from the trading range (High minus Low) of each day. The formula is: σ_P = (1/√(4ln2)) × √(1/n × Σln²(H_i/L_i)) × √252, where H_i and L_i are high and low prices. Under ideal conditions, this estimator is approximately five times more efficient than the close-to-close estimator (Parkinson, 1980), as it uses more information per observation.
4.3 Drawdown-Based Position Size Adjustment
In addition to volatility targeting, the model implements drawdown-based risk control. The logic is that deep market declines often signal further losses and therefore justify exposure reduction. This behavior corresponds with the concept of path-dependent risk tolerance: investors who have already suffered losses are typically less willing to take additional risk (Kahneman and Tversky, 1979).
The model defines a maximum portfolio drawdown as a target parameter (default 15%). Since portfolio volatility and portfolio drawdown are proportional to equity allocation (assuming cash has neither volatility nor drawdown), allocation-based control is possible. For example, if the market exhibits a 25% drawdown and target portfolio drawdown is 15%, equity allocation should be at most 60% (15/25).
4.4 Dynamic Risk Adjustment
An advanced feature of DEAM is dynamic adjustment of risk-based allocation through a feedback mechanism. The model continuously estimates what actual portfolio volatility and portfolio drawdown would result at the current allocation. If risk utilization (ratio of actual to target risk) exceeds 1.0, allocation is reduced by an adjustment factor that grows exponentially with overutilization. This implements a form of dynamic feedback that avoids overexposure.
Mathematically, a risk adjustment factor r_adjust is calculated: if risk utilization u > 1, then r_adjust = exp(-0.5 × (u - 1)). This exponential function ensures that moderate overutilization is gently corrected, while strong overutilization triggers drastic reductions. The factor 0.5 in the exponent was empirically calibrated to achieve a balanced ratio between sensitivity and stability.
5. Component 3: Valuation Analysis
5.1 Theoretical Foundations of Fundamental Valuation
DEAM's valuation component is based on the fundamental premise that the intrinsic value of a security is determined by its future cash flows and that deviations between market price and intrinsic value are eventually corrected. Graham and Dodd (1934) established in "Security Analysis" the basic principles of fundamental analysis that remain relevant today. Translated into modern portfolio context, this means that markets with high valuation metrics (high price-earnings ratios) should have lower expected returns than cheaply valued markets.
Campbell and Shiller (1988) developed the Cyclically Adjusted P/E Ratio (CAPE), which smooths earnings over a full business cycle. Their empirical analysis showed that this ratio has significant predictive power for 10-year returns. Asness, Moskowitz, and Pedersen (2013) demonstrated in "Value and Momentum Everywhere" that value effects exist not only in individual stocks but also in asset classes and markets.
5.2 Equity Risk Premium as Central Valuation Metric
The Equity Risk Premium (ERP) is defined as the expected excess return of stocks over risk-free government bonds. It is the theoretical heart of valuation analysis, as it represents the compensation investors demand for bearing equity risk. Damodaran (2012) discusses in "Equity Risk Premiums: Determinants, Estimation and Implications" various methods for ERP estimation.
DEAM calculates ERP not through a single method but combines four complementary approaches with different weights. This multi-method strategy increases estimation robustness and avoids dependence on single, potentially erroneous inputs.
The first method (35% weight) uses earnings yield, calculated as 1/P/E or directly from operating earnings data, and subtracts the 10-year Treasury yield. This method follows Fed Model logic (Yardeni, 2003), although this model has theoretical weaknesses as it does not consistently treat inflation (Asness, 2003).
The second method (30% weight) extends earnings yield by share buyback yield. Share buybacks are a form of capital return to shareholders and increase value per share. Boudoukh et al. (2007) showed in "The Total Shareholder Yield" that the sum of dividend yield and buyback yield is a better predictor of future returns than dividend yield alone.
The third method (20% weight) implements the Gordon Growth Model (Gordon, 1962), which models stock value as the sum of discounted future dividends. Under constant growth g assumption: Expected Return = Dividend Yield + g. The model estimates sustainable growth as g = ROE × (1 - Payout Ratio), where ROE is return on equity and payout ratio is the ratio of dividends to earnings. This formula follows from equity theory: unretained earnings are reinvested at ROE and generate additional earnings growth.
The fourth method (15% weight) combines total shareholder yield (Dividend + Buybacks) with implied growth derived from revenue growth. This method considers that companies with strong revenue growth should generate higher future earnings, even if current valuations do not yet fully reflect this.
The final ERP is the weighted average of these four methods. A high ERP (above 4%) signals attractive valuations and increases the valuation score to 95 out of 100 possible points. A negative ERP, where stocks have lower expected returns than bonds, results in a minimal score of 10.
5.3 Quality Adjustments to Valuation
Valuation metrics alone can be misleading if not interpreted in the context of company quality. A company with a low P/E may be cheap or fundamentally problematic. The model therefore implements quality adjustments based on growth, profitability, and capital structure.
Revenue growth above 10% annually adds 10 points to the valuation score, moderate growth above 5% adds 5 points. This adjustment reflects that growth has independent value (Modigliani and Miller, 1961, extended by later growth theory). Net margin above 15% signals pricing power and operational efficiency and increases the score by 5 points, while low margins below 8% indicate competitive pressure and subtract 5 points.
Return on equity (ROE) above 20% characterizes outstanding capital efficiency and increases the score by 5 points. Piotroski (2000) showed in "Value Investing: The Use of Historical Financial Statement Information" that fundamental quality signals such as high ROE can improve the performance of value strategies.
Capital structure is evaluated through the debt-to-equity ratio. A conservative ratio below 1.0 multiplies the valuation score by 1.2, while high leverage above 2.0 applies a multiplier of 0.8. This adjustment reflects that high debt constrains financial flexibility and can become problematic in crisis times (Korteweg, 2010).
6. Component 4: Sentiment Analysis
6.1 The Role of Sentiment in Financial Markets
Investor sentiment, defined as the collective psychological attitude of market participants, influences asset prices independently of fundamental data. Baker and Wurgler (2006, 2007) developed a sentiment index and showed that periods of high sentiment are followed by overvaluations that later correct. This insight justifies integrating a sentiment component into allocation decisions.
Sentiment is difficult to measure directly but can be proxied through market indicators. The VIX is the most widely used sentiment indicator, as it aggregates implied volatility from option prices. High VIX values reflect elevated uncertainty and risk aversion, while low values signal market comfort. Whaley (2009) refers to the VIX as the "Investor Fear Gauge" and documents its role as a contrarian indicator: extremely high values typically occur at market bottoms, while low values occur at tops.
6.2 VIX-Based Sentiment Assessment
DEAM uses statistical normalization of the VIX by calculating the Z-score: z = (VIX_current - VIX_average) / VIX_standard_deviation. The Z-score indicates how many standard deviations the current VIX is from the historical average. This approach is more robust than absolute thresholds, as it adapts to the average volatility level, which can vary over longer periods.
A Z-score below -1.5 (VIX is 1.5 standard deviations below average) signals exceptionally low risk perception and adds 40 points to the sentiment score. This may seem counterintuitive—shouldn't low fear be bullish? However, the logic follows the contrarian principle: when no one is afraid, everyone is already invested, and there is limited further upside potential (Zweig, 1973). Conversely, a Z-score above 1.5 (extreme fear) adds -40 points, reflecting market panic but simultaneously suggesting potential buying opportunities.
6.3 VIX Term Structure as Sentiment Signal
The VIX term structure provides additional sentiment information. Normally, the VIX trades in contango, meaning longer-term VIX futures have higher prices than short-term. This reflects that short-term volatility is currently known, while long-term volatility is more uncertain and carries a risk premium. The model compares the VIX with VIX9D (9-day volatility) and identifies backwardation (VIX > 1.05 × VIX9D) and steep backwardation (VIX > 1.15 × VIX9D).
Backwardation occurs when short-term implied volatility is higher than longer-term, which typically happens during market stress. Investors anticipate immediate turbulence but expect calming. Psychologically, this reflects acute fear. The model subtracts 15 points for backwardation and 30 for steep backwardation, as these constellations signal elevated risk. Simon and Wiggins (2001) analyzed the VIX futures curve and showed that backwardation is associated with market declines.
6.4 Safe-Haven Flows
During crisis times, investors flee from risky assets into safe havens: gold, US dollar, and Japanese yen. This "flight to quality" is a sentiment signal. The model calculates the performance of these assets relative to stocks over the last 20 trading days. When gold or the dollar strongly rise while stocks fall, this indicates elevated risk aversion.
The safe-haven component is calculated as the difference between safe-haven performance and stock performance. Positive values (safe havens outperform) subtract up to 20 points from the sentiment score, negative values (stocks outperform) add up to 10 points. The asymmetric treatment (larger deduction for risk-off than bonus for risk-on) reflects that risk-off movements are typically sharper and more informative than risk-on phases.
Baur and Lucey (2010) examined safe-haven properties of gold and showed that gold indeed exhibits negative correlation with stocks during extreme market movements, confirming its role as crisis protection.
7. Component 5: Macroeconomic Analysis
7.1 The Yield Curve as Economic Indicator
The yield curve, represented as yields of government bonds of various maturities, contains aggregated expectations about future interest rates, inflation, and economic growth. The slope of the yield curve has remarkable predictive power for recessions. Estrella and Mishkin (1998) showed that an inverted yield curve (short-term rates higher than long-term) predicts recessions with high reliability. This is because inverted curves reflect restrictive monetary policy: the central bank raises short-term rates to combat inflation, dampening economic activity.
DEAM calculates two spread measures: the 2-year-minus-10-year spread and the 3-month-minus-10-year spread. A steep, positive curve (spreads above 1.5% and 2% respectively) signals healthy growth expectations and generates the maximum yield curve score of 40 points. A flat curve (spreads near zero) reduces the score to 20 points. An inverted curve (negative spreads) is particularly alarming and results in only 10 points.
The choice of two different spreads increases analysis robustness. The 2-10 spread is most established in academic literature, while the 3M-10Y spread is often considered more sensitive, as the 3-month rate directly reflects current monetary policy (Ang, Piazzesi, and Wei, 2006).
7.2 Credit Conditions and Spreads
Credit spreads—the yield difference between risky corporate bonds and safe government bonds—reflect risk perception in the credit market. Gilchrist and Zakrajšek (2012) constructed an "Excess Bond Premium" that measures the component of credit spreads not explained by fundamentals and showed this is a predictor of future economic activity and stock returns.
The model approximates credit spread by comparing the yield of high-yield bond ETFs (HYG) with investment-grade bond ETFs (LQD). A narrow spread below 200 basis points signals healthy credit conditions and risk appetite, contributing 30 points to the macro score. Very wide spreads above 1000 basis points (as during the 2008 financial crisis) signal credit crunch and generate zero points.
Additionally, the model evaluates whether "flight to quality" is occurring, identified through strong performance of Treasury bonds (TLT) with simultaneous weakness in high-yield bonds. This constellation indicates elevated risk aversion and reduces the credit conditions score.
7.3 Financial Stability at Corporate Level
While the yield curve and credit spreads reflect macroeconomic conditions, financial stability evaluates the health of companies themselves. The model uses the aggregated debt-to-equity ratio and return on equity of the S&P 500 as proxies for corporate health.
A low leverage level below 0.5 combined with high ROE above 15% signals robust corporate balance sheets and generates 20 points. This combination is particularly valuable as it represents both defensive strength (low debt means crisis resistance) and offensive strength (high ROE means earnings power). High leverage above 1.5 generates only 5 points, as it implies vulnerability to interest rate increases and recessions.
Korteweg (2010) showed in "The Net Benefits to Leverage" that optimal debt maximizes firm value, but excessive debt increases distress costs. At the aggregated market level, high debt indicates fragilities that can become problematic during stress phases.
8. Component 6: Crisis Detection
8.1 The Need for Systematic Crisis Detection
Financial crises are rare but extremely impactful events that suspend normal statistical relationships. During normal market volatility, diversified portfolios and traditional risk management approaches function, but during systemic crises, seemingly independent assets suddenly correlate strongly, and losses exceed historical expectations (Longin and Solnik, 2001). This justifies a separate crisis detection mechanism that operates independently of regular allocation components.
Reinhart and Rogoff (2009) documented in "This Time Is Different: Eight Centuries of Financial Folly" recurring patterns in financial crises: extreme volatility, massive drawdowns, credit market dysfunction, and asset price collapse. DEAM operationalizes these patterns into quantifiable crisis indicators.
8.2 Multi-Signal Crisis Identification
The model uses a counter-based approach where various stress signals are identified and aggregated. This methodology is more robust than relying on a single indicator, as true crises typically occur simultaneously across multiple dimensions. A single signal may be a false alarm, but the simultaneous presence of multiple signals increases confidence.
The first indicator is a VIX above the crisis threshold (default 40), adding one point. A VIX above 60 (as in 2008 and March 2020) adds two additional points, as such extreme values are historically very rare. This tiered approach captures the intensity of volatility.
The second indicator is market drawdown. A drawdown above 15% adds one point, as corrections of this magnitude can be potential harbingers of larger crises. A drawdown above 25% adds another point, as historical bear markets typically encompass 25-40% drawdowns.
The third indicator is credit market spreads above 500 basis points, adding one point. Such wide spreads occur only during significant credit market disruptions, as in 2008 during the Lehman crisis.
The fourth indicator identifies simultaneous losses in stocks and bonds. Normally, Treasury bonds act as a hedge against equity risk (negative correlation), but when both fall simultaneously, this indicates systemic liquidity problems or inflation/stagflation fears. The model checks whether both SPY and TLT have fallen more than 10% and 5% respectively over 5 trading days, adding two points.
The fifth indicator is a volume spike combined with negative returns. Extreme trading volumes (above twice the 20-day average) with falling prices signal panic selling. This adds one point.
A crisis situation is diagnosed when at least 3 indicators trigger, a severe crisis at 5 or more indicators. These thresholds were calibrated through historical backtesting to identify true crises (2008, 2020) without generating excessive false alarms.
8.3 Crisis-Based Allocation Override
When a crisis is detected, the system overrides the normal allocation recommendation and caps equity allocation at maximum 25%. In a severe crisis, the cap is set at 10%. This drastic defensive posture follows the empirical observation that crises typically require time to develop and that early reduction can avoid substantial losses (Faber, 2007).
This override logic implements a "safety first" principle: in situations of existential danger to the portfolio, capital preservation becomes the top priority. Roy (1952) formalized this approach in "Safety First and the Holding of Assets," arguing that investors should primarily minimize ruin probability.
9. Integration and Final Allocation Calculation
9.1 Component Weighting
The final allocation recommendation emerges through weighted aggregation of the five components. The standard weighting is: Market Regime 35%, Risk Management 25%, Valuation 20%, Sentiment 15%, Macro 5%. These weights reflect both theoretical considerations and empirical backtesting results.
The highest weighting of market regime is based on evidence that trend-following and momentum strategies have delivered robust results across various asset classes and time periods (Moskowitz, Ooi, and Pedersen, 2012). Current market momentum is highly informative for the near future, although it provides no information about long-term expectations.
The substantial weighting of risk management (25%) follows from the central importance of risk control. Wealth preservation is the foundation of long-term wealth creation, and systematic risk management is demonstrably value-creating (Moreira and Muir, 2017).
The valuation component receives 20% weight, based on the long-term mean reversion of valuation metrics. While valuation has limited short-term predictive power (bull and bear markets can begin at any valuation), the long-term relationship between valuation and returns is robustly documented (Campbell and Shiller, 1988).
Sentiment (15%) and Macro (5%) receive lower weights, as these factors are subtler and harder to measure. Sentiment is valuable as a contrarian indicator at extremes but less informative in normal ranges. Macro variables such as the yield curve have strong predictive power for recessions, but the transmission from recessions to stock market performance is complex and temporally variable.
9.2 Model Type Adjustments
DEAM allows users to choose between four model types: Conservative, Balanced, Aggressive, and Adaptive. This choice modifies the final allocation through additive adjustments.
Conservative mode subtracts 10 percentage points from allocation, resulting in consistently more cautious positioning. This is suitable for risk-averse investors or those with limited investment horizons. Aggressive mode adds 10 percentage points, suitable for risk-tolerant investors with long horizons.
Adaptive mode implements procyclical adjustment based on short-term momentum: if the market has risen more than 5% in the last 20 days, 5 percentage points are added; if it has declined more than 5%, 5 points are subtracted. This logic follows the observation that short-term momentum persists (Jegadeesh and Titman, 1993), but the moderate size of adjustment avoids excessive timing bets.
Balanced mode makes no adjustment and uses raw model output. This neutral setting is suitable for investors who wish to trust model recommendations unchanged.
9.3 Smoothing and Stability
The allocation resulting from aggregation undergoes final smoothing through a simple moving average over 3 periods. This smoothing is crucial for model practicality, as it reduces frequent trading and thus transaction costs. Without smoothing, the model could fluctuate between adjacent allocations with every small input change.
The choice of 3 periods as smoothing window is a compromise between responsiveness and stability. Longer smoothing would excessively delay signals and impede response to true regime changes. Shorter or no smoothing would allow too much noise. Empirical tests showed that 3-period smoothing offers an optimal ratio between these goals.
10. Visualization and Interpretation
10.1 Main Output: Equity Allocation
DEAM's primary output is a time series from 0 to 100 representing the recommended percentage allocation to equities. This representation is intuitive: 100% means full investment in stocks (specifically: an S&P 500 ETF), 0% means complete cash position, and intermediate values correspond to mixed portfolios. A value of 60% means, for example: invest 60% of wealth in SPY, hold 40% in money market instruments or cash.
The time series is color-coded to enable quick visual interpretation. Green shades represent high allocations (above 80%, bullish), red shades low allocations (below 20%, bearish), and neutral colors middle allocations. The chart background is dynamically colored based on the signal, enhancing readability in different market phases.
10.2 Dashboard Metrics
A tabular dashboard presents key metrics compactly. This includes current allocation, cash allocation (complement), an aggregated signal (BULLISH/NEUTRAL/BEARISH), current market regime, VIX level, market drawdown, and crisis status.
Additionally, fundamental metrics are displayed: P/E Ratio, Equity Risk Premium, Return on Equity, Debt-to-Equity Ratio, and Total Shareholder Yield. This transparency allows users to understand model decisions and form their own assessments.
Component scores (Regime, Risk, Valuation, Sentiment, Macro) are also displayed, each normalized on a 0-100 scale. This shows which factors primarily drive the current recommendation. If, for example, the Risk score is very low (20) while other scores are moderate (50-60), this indicates that risk management considerations are pulling allocation down.
10.3 Component Breakdown (Optional)
Advanced users can display individual components as separate lines in the chart. This enables analysis of component dynamics: do all components move synchronously, or are there divergences? Divergences can be particularly informative. If, for example, the market regime is bullish (high score) but the valuation component is very negative, this signals an overbought market not fundamentally supported—a classic "bubble warning."
This feature is disabled by default to keep the chart clean but can be activated for deeper analysis.
10.4 Confidence Bands
The model optionally displays uncertainty bands around the main allocation line. These are calculated as ±1 standard deviation of allocation over a rolling 20-period window. Wide bands indicate high volatility of model recommendations, suggesting uncertain market conditions. Narrow bands indicate stable recommendations.
This visualization implements a concept of epistemic uncertainty—uncertainty about the model estimate itself, not just market volatility. In phases where various indicators send conflicting signals, the allocation recommendation becomes more volatile, manifesting in wider bands. Users can understand this as a warning to act more cautiously or consult alternative information sources.
11. Alert System
11.1 Allocation Alerts
DEAM implements an alert system that notifies users of significant events. Allocation alerts trigger when smoothed allocation crosses certain thresholds. An alert is generated when allocation reaches 80% (from below), signaling strong bullish conditions. Another alert triggers when allocation falls to 20%, indicating defensive positioning.
These thresholds are not arbitrary but correspond with boundaries between model regimes. An allocation of 80% roughly corresponds to a clear bull market regime, while 20% corresponds to a bear market regime. Alerts at these points are therefore informative about fundamental regime shifts.
11.2 Crisis Alerts
Separate alerts trigger upon detection of crisis and severe crisis. These alerts have highest priority as they signal large risks. A crisis alert should prompt investors to review their portfolio and potentially take defensive measures beyond the automatic model recommendation (e.g., hedging through put options, rebalancing to more defensive sectors).
11.3 Regime Change Alerts
An alert triggers upon change of market regime (e.g., from Neutral to Correction, or from Bull Market to Strong Bull). Regime changes are highly informative events that typically entail substantial allocation changes. These alerts enable investors to proactively respond to changes in market dynamics.
11.4 Risk Breach Alerts
A specialized alert triggers when actual portfolio risk utilization exceeds target parameters by 20%. This is a warning signal that the risk management system is reaching its limits, possibly because market volatility is rising faster than allocation can be reduced. In such situations, investors should consider manual interventions.
12. Practical Application and Limitations
12.1 Portfolio Implementation
DEAM generates a recommendation for allocation between equities (S&P 500) and cash. Implementation by an investor can take various forms. The most direct method is using an S&P 500 ETF (e.g., SPY, VOO) for equity allocation and a money market fund or savings account for cash allocation.
A rebalancing strategy is required to synchronize actual allocation with model recommendation. Two approaches are possible: (1) rule-based rebalancing at every 10% deviation between actual and target, or (2) time-based monthly rebalancing. Both have trade-offs between responsiveness and transaction costs. Empirical evidence (Jaconetti, Kinniry, and Zilbering, 2010) suggests rebalancing frequency has moderate impact on performance, and investors should optimize based on their transaction costs.
12.2 Adaptation to Individual Preferences
The model offers numerous adjustment parameters. Component weights can be modified if investors place more or less belief in certain factors. A fundamentally-oriented investor might increase valuation weight, while a technical trader might increase regime weight.
Risk target parameters (target volatility, max drawdown) should be adapted to individual risk tolerance. Younger investors with long investment horizons can choose higher target volatility (15-18%), while retirees may prefer lower volatility (8-10%). This adjustment systematically shifts average equity allocation.
Crisis thresholds can be adjusted based on preference for sensitivity versus specificity of crisis detection. Lower thresholds (e.g., VIX > 35 instead of 40) increase sensitivity (more crises are detected) but reduce specificity (more false alarms). Higher thresholds have the reverse effect.
12.3 Limitations and Disclaimers
DEAM is based on historical relationships between indicators and market performance. There is no guarantee these relationships will persist in the future. Structural changes in markets (e.g., through regulation, technology, or central bank policy) can break established patterns. This is the fundamental problem of induction in financial science (Taleb, 2007).
The model is optimized for US equities (S&P 500). Application to other markets (international stocks, bonds, commodities) would require recalibration. The indicators and thresholds are specific to the statistical properties of the US equity market.
The model cannot eliminate losses. Even with perfect crisis prediction, an investor following the model would lose money in bear markets—just less than a buy-and-hold investor. The goal is risk-adjusted performance improvement, not risk elimination.
Transaction costs are not modeled. In practice, spreads, commissions, and taxes reduce net returns. Frequent trading can cause substantial costs. Model smoothing helps minimize this, but users should consider their specific cost situation.
The model reacts to information; it does not anticipate it. During sudden shocks (e.g., 9/11, COVID-19 lockdowns), the model can only react after price movements, not before. This limitation is inherent to all reactive systems.
12.4 Relationship to Other Strategies
DEAM is a tactical asset allocation approach and should be viewed as a complement, not replacement, for strategic asset allocation. Brinson, Hood, and Beebower (1986) showed in their influential study "Determinants of Portfolio Performance" that strategic asset allocation (long-term policy allocation) explains the majority of portfolio performance, but this leaves room for tactical adjustments based on market timing.
The model can be combined with value and momentum strategies at the individual stock level. While DEAM controls overall market exposure, within-equity decisions can be optimized through stock-picking models. This separation between strategic (market exposure) and tactical (stock selection) levels follows classical portfolio theory.
The model does not replace diversification across asset classes. A complete portfolio should also include bonds, international stocks, real estate, and alternative investments. DEAM addresses only the US equity allocation decision within a broader portfolio.
13. Scientific Foundation and Evaluation
13.1 Theoretical Consistency
DEAM's components are based on established financial theory and empirical evidence. The market regime component follows from regime-switching models (Hamilton, 1989) and trend-following literature. The risk management component implements volatility targeting (Moreira and Muir, 2017) and modern portfolio theory (Markowitz, 1952). The valuation component is based on discounted cash flow theory and empirical value research (Campbell and Shiller, 1988; Fama and French, 1992). The sentiment component integrates behavioral finance (Baker and Wurgler, 2006). The macro component uses established business cycle indicators (Estrella and Mishkin, 1998).
This theoretical grounding distinguishes DEAM from purely data-mining-based approaches that identify patterns without causal theory. Theory-guided models have greater probability of functioning out-of-sample, as they are based on fundamental mechanisms, not random correlations (Lo and MacKinlay, 1990).
13.2 Empirical Validation
While this document does not present detailed backtest analysis, it should be noted that rigorous validation of a tactical asset allocation model should include several elements:
In-sample testing establishes whether the model functions at all in the data on which it was calibrated. Out-of-sample testing is crucial: the model should be tested in time periods not used for development. Walk-forward analysis, where the model is successively trained on rolling windows and tested in the next window, approximates real implementation.
Performance metrics should be risk-adjusted. Pure return consideration is misleading, as higher returns often only compensate for higher risk. Sharpe Ratio, Sortino Ratio, Calmar Ratio, and Maximum Drawdown are relevant metrics. Comparison with benchmarks (Buy-and-Hold S&P 500, 60/40 Stock/Bond portfolio) contextualizes performance.
Robustness checks test sensitivity to parameter variation. If the model only functions at specific parameter settings, this indicates overfitting. Robust models show consistent performance over a range of plausible parameters.
13.3 Comparison with Existing Literature
DEAM fits into the broader literature on tactical asset allocation. Faber (2007) presented a simple momentum-based timing system that goes long when the market is above its 10-month average, otherwise cash. This simple system avoided large drawdowns in bear markets. DEAM can be understood as a sophistication of this approach that integrates multiple information sources.
Ilmanen (2011) discusses various timing factors in "Expected Returns" and argues for multi-factor approaches. DEAM operationalizes this philosophy. Asness, Moskowitz, and Pedersen (2013) showed that value and momentum effects work across asset classes, justifying cross-asset application of regime and valuation signals.
Ang (2014) emphasizes in "Asset Management: A Systematic Approach to Factor Investing" the importance of systematic, rule-based approaches over discretionary decisions. DEAM is fully systematic and eliminates emotional biases that plague individual investors (overconfidence, hindsight bias, loss aversion).
References
Ang, A. (2014) *Asset Management: A Systematic Approach to Factor Investing*. Oxford: Oxford University Press.
Ang, A., Piazzesi, M. and Wei, M. (2006) 'What does the yield curve tell us about GDP growth?', *Journal of Econometrics*, 131(1-2), pp. 359-403.
Asness, C.S. (2003) 'Fight the Fed Model', *The Journal of Portfolio Management*, 30(1), pp. 11-24.
Asness, C.S., Moskowitz, T.J. and Pedersen, L.H. (2013) 'Value and Momentum Everywhere', *The Journal of Finance*, 68(3), pp. 929-985.
Baker, M. and Wurgler, J. (2006) 'Investor Sentiment and the Cross-Section of Stock Returns', *The Journal of Finance*, 61(4), pp. 1645-1680.
Baker, M. and Wurgler, J. (2007) 'Investor Sentiment in the Stock Market', *Journal of Economic Perspectives*, 21(2), pp. 129-152.
Baur, D.G. and Lucey, B.M. (2010) 'Is Gold a Hedge or a Safe Haven? An Analysis of Stocks, Bonds and Gold', *Financial Review*, 45(2), pp. 217-229.
Bollerslev, T. (1986) 'Generalized Autoregressive Conditional Heteroskedasticity', *Journal of Econometrics*, 31(3), pp. 307-327.
Boudoukh, J., Michaely, R., Richardson, M. and Roberts, M.R. (2007) 'On the Importance of Measuring Payout Yield: Implications for Empirical Asset Pricing', *The Journal of Finance*, 62(2), pp. 877-915.
Brinson, G.P., Hood, L.R. and Beebower, G.L. (1986) 'Determinants of Portfolio Performance', *Financial Analysts Journal*, 42(4), pp. 39-44.
Brock, W., Lakonishok, J. and LeBaron, B. (1992) 'Simple Technical Trading Rules and the Stochastic Properties of Stock Returns', *The Journal of Finance*, 47(5), pp. 1731-1764.
Calmar, T.W. (1991) 'The Calmar Ratio', *Futures*, October issue.
Campbell, J.Y. and Shiller, R.J. (1988) 'The Dividend-Price Ratio and Expectations of Future Dividends and Discount Factors', *Review of Financial Studies*, 1(3), pp. 195-228.
Cochrane, J.H. (2011) 'Presidential Address: Discount Rates', *The Journal of Finance*, 66(4), pp. 1047-1108.
Damodaran, A. (2012) *Equity Risk Premiums: Determinants, Estimation and Implications*. Working Paper, Stern School of Business.
Engle, R.F. (1982) 'Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of United Kingdom Inflation', *Econometrica*, 50(4), pp. 987-1007.
Estrella, A. and Hardouvelis, G.A. (1991) 'The Term Structure as a Predictor of Real Economic Activity', *The Journal of Finance*, 46(2), pp. 555-576.
Estrella, A. and Mishkin, F.S. (1998) 'Predicting U.S. Recessions: Financial Variables as Leading Indicators', *Review of Economics and Statistics*, 80(1), pp. 45-61.
Faber, M.T. (2007) 'A Quantitative Approach to Tactical Asset Allocation', *The Journal of Wealth Management*, 9(4), pp. 69-79.
Fama, E.F. and French, K.R. (1989) 'Business Conditions and Expected Returns on Stocks and Bonds', *Journal of Financial Economics*, 25(1), pp. 23-49.
Fama, E.F. and French, K.R. (1992) 'The Cross-Section of Expected Stock Returns', *The Journal of Finance*, 47(2), pp. 427-465.
Garman, M.B. and Klass, M.J. (1980) 'On the Estimation of Security Price Volatilities from Historical Data', *Journal of Business*, 53(1), pp. 67-78.
Gilchrist, S. and Zakrajšek, E. (2012) 'Credit Spreads and Business Cycle Fluctuations', *American Economic Review*, 102(4), pp. 1692-1720.
Gordon, M.J. (1962) *The Investment, Financing, and Valuation of the Corporation*. Homewood: Irwin.
Graham, B. and Dodd, D.L. (1934) *Security Analysis*. New York: McGraw-Hill.
Hamilton, J.D. (1989) 'A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle', *Econometrica*, 57(2), pp. 357-384.
Ilmanen, A. (2011) *Expected Returns: An Investor's Guide to Harvesting Market Rewards*. Chichester: Wiley.
Jaconetti, C.M., Kinniry, F.M. and Zilbering, Y. (2010) 'Best Practices for Portfolio Rebalancing', *Vanguard Research Paper*.
Jegadeesh, N. and Titman, S. (1993) 'Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency', *The Journal of Finance*, 48(1), pp. 65-91.
Kahneman, D. and Tversky, A. (1979) 'Prospect Theory: An Analysis of Decision under Risk', *Econometrica*, 47(2), pp. 263-292.
Korteweg, A. (2010) 'The Net Benefits to Leverage', *The Journal of Finance*, 65(6), pp. 2137-2170.
Lo, A.W. and MacKinlay, A.C. (1990) 'Data-Snooping Biases in Tests of Financial Asset Pricing Models', *Review of Financial Studies*, 3(3), pp. 431-467.
Longin, F. and Solnik, B. (2001) 'Extreme Correlation of International Equity Markets', *The Journal of Finance*, 56(2), pp. 649-676.
Mandelbrot, B. (1963) 'The Variation of Certain Speculative Prices', *The Journal of Business*, 36(4), pp. 394-419.
Markowitz, H. (1952) 'Portfolio Selection', *The Journal of Finance*, 7(1), pp. 77-91.
Modigliani, F. and Miller, M.H. (1961) 'Dividend Policy, Growth, and the Valuation of Shares', *The Journal of Business*, 34(4), pp. 411-433.
Moreira, A. and Muir, T. (2017) 'Volatility-Managed Portfolios', *The Journal of Finance*, 72(4), pp. 1611-1644.
Moskowitz, T.J., Ooi, Y.H. and Pedersen, L.H. (2012) 'Time Series Momentum', *Journal of Financial Economics*, 104(2), pp. 228-250.
Parkinson, M. (1980) 'The Extreme Value Method for Estimating the Variance of the Rate of Return', *Journal of Business*, 53(1), pp. 61-65.
Piotroski, J.D. (2000) 'Value Investing: The Use of Historical Financial Statement Information to Separate Winners from Losers', *Journal of Accounting Research*, 38, pp. 1-41.
Reinhart, C.M. and Rogoff, K.S. (2009) *This Time Is Different: Eight Centuries of Financial Folly*. Princeton: Princeton University Press.
Ross, S.A. (1976) 'The Arbitrage Theory of Capital Asset Pricing', *Journal of Economic Theory*, 13(3), pp. 341-360.
Roy, A.D. (1952) 'Safety First and the Holding of Assets', *Econometrica*, 20(3), pp. 431-449.
Schwert, G.W. (1989) 'Why Does Stock Market Volatility Change Over Time?', *The Journal of Finance*, 44(5), pp. 1115-1153.
Sharpe, W.F. (1966) 'Mutual Fund Performance', *The Journal of Business*, 39(1), pp. 119-138.
Sharpe, W.F. (1994) 'The Sharpe Ratio', *The Journal of Portfolio Management*, 21(1), pp. 49-58.
Simon, D.P. and Wiggins, R.A. (2001) 'S&P Futures Returns and Contrary Sentiment Indicators', *Journal of Futures Markets*, 21(5), pp. 447-462.
Taleb, N.N. (2007) *The Black Swan: The Impact of the Highly Improbable*. New York: Random House.
Whaley, R.E. (2000) 'The Investor Fear Gauge', *The Journal of Portfolio Management*, 26(3), pp. 12-17.
Whaley, R.E. (2009) 'Understanding the VIX', *The Journal of Portfolio Management*, 35(3), pp. 98-105.
Yardeni, E. (2003) 'Stock Valuation Models', *Topical Study*, 51, Yardeni Research.
Zweig, M.E. (1973) 'An Investor Expectations Stock Price Predictive Model Using Closed-End Fund Premiums', *The Journal of Finance*, 28(1), pp. 67-78.
SuperTrend Optimizer Remastered[CHE] SuperTrend Optimizer Remastered — Grid-ranked SuperTrend with additive or multiplicative scoring
Summary
This indicator evaluates a fixed grid of one hundred and two SuperTrend parameter pairs and ranks them by a simple flip-to-flip return model. It auto-selects the currently best-scoring combination and renders its SuperTrend in real time, with optional gradient coloring for faster visual parsing. The original concept is by KioseffTrading Thanks a lot for it.
For years I wanted to shorten the roughly two thousand three hundred seventy-one lines; I have now reduced the core to about three hundred eighty lines without triggering script errors. The simplification is generalizable to other indicators. A multiplicative return mode was added alongside the existing additive aggregation, enabling different rankings and often more realistic compounding behavior.
Motivation: Why this design?
SuperTrend is sensitive to its factor and period. Picking a single pair statically can underperform across regimes. This design sweeps a compact parameter grid around user-defined lower bounds, measures flip-to-flip outcomes, and promotes the combination with the strongest cumulative return. The approach keeps the visual footprint familiar while removing manual trial-and-error. The multiplicative mode captures compounding effects; the additive mode remains available for linear aggregation.
Originally (by KioseffTrading)
Very long script (~2,371 lines), monolithic structure.
SuperTrend optimization with additive (cumulative percentage-sum) scoring only.
Heavier use of repetitive code; limited modularity and fewer UI conveniences.
No explicit multiplicative compounding option; rankings did not reflect sequence-sensitive equity growth.
Now (remastered by CHE)
Compact core (~380 lines) with the same functional intent, no compile errors.
Adds multiplicative (compounding) scoring alongside additive, changing rankings to reflect real equity paths and penalize drawdown sequences.
Fixed 34×3 grid sweep, live ranking, gradient-based bar/wick/line visuals, top-table display, and an optional override plot.
Cleaner arrays/state handling, last-bar table updates, and reusable simplification pattern that can be applied to other indicators.
What’s different vs. standard approaches?
Baseline: A single SuperTrend with hand-picked inputs.
Architecture differences:
Fixed grid of thirty-four factor offsets across three ATR offsets.
Per-combination flip-to-flip backtest with additive or multiplicative aggregation.
Live ranking with optional “Best” or “Worst” table output.
Gradient bar, wick, and line coloring driven by consecutive trend counts.
Optional override plot to force a specific SuperTrend independent of ranking.
Practical effect: Charts show the currently best-scoring SuperTrend, not a static choice, plus an on-chart table of top performers for transparency.
How it works (technical)
For each parameter pair, the script computes SuperTrend value and direction. It monitors direction transitions and treats a change from up to down as a long entry and the reverse as an exit, measuring the move between entry and exit using close prices. Results are aggregated per pair either by summing percentage changes or by compounding return factors and then converting to percent for comparison. On the last bar, open trades are included as unrealized contributions to ranking. The best combination’s line is plotted, with separate styling for up and down regimes. Consecutive regime counts are normalized within a rolling window and mapped to gradients for bars, wicks, and lines. A two-column table reports the best or worst performers, with an optional row describing the parameter sweep.
Parameter Guide
Factor (Lower Bound) — Starting SuperTrend factor; the grid adds offsets between zero and three point three. Default three point zero. Higher raises distance to price and reduces flips.
ATR Period (Lower Bound) — Starting ATR length; the grid adds zero, one, and two. Default ten. Longer reduces noise at the cost of responsiveness.
Best vs Worst — Ranks by top or bottom cumulative return. Default Best. Use Worst for stress tests.
Calculation Mode — Additive sums percents; Multiplicative compounds returns. Multiplicative is closer to equity growth and can change the leaderboard.
Show in Table — “Top Three” or “All”. Fewer rows keep charts clean.
Show “Parameters Tested” Label — Displays the effective sweep ranges for auditability.
Plot Override SuperTrend — If enabled, the override factor and ATR are plotted instead of the ranked winner.
Override Factor / ATR Period — Values used when override is on.
Light Mode (for Table) — Adjusts table colors for bright charts.
Gradient/Coloring controls — Toggles for gradient bars and wick coloring, window length for normalization, gamma for contrast, and transparency settings. Use these to emphasize or tone down visual intensity.
Table Position and Text Size — Places the table and sets typography.
Reading & Interpretation
The auto SuperTrend plots one line for up regimes and one for down regimes. Color intensity reflects consecutive trend persistence within the chosen window. A small square at the bottom encodes the same gradient as a compact status channel. Optional wick coloring uses the same gradient for maximum contrast. The performance table lists parameter pairs and their cumulative return under the chosen aggregation; positive values are tinted with the up color, negative with the down color. “Long” labels mark flips that open a long in the simplified model.
Practical Workflows & Combinations
Trend following: Use the auto line as your primary bias. Enter on flips aligned with structure such as higher highs and higher lows. Filter with higher-timeframe trend or volatility contraction.
Exits/Stops: Consider conservative exits when color intensity fades or when the opposite line is approached. Aggressive traders can trail near the plotted line.
Override mode: When you want stability across instruments, enable override and standardize factor and ATR; keep the table visible for sanity checks.
Multi-asset/Multi-TF: Defaults travel well on liquid instruments and intraday to daily timeframes. Heavier assets may prefer larger lower bounds or multiplicative mode.
Behavior, Constraints & Performance
Repaint/confirmation: Signals are based on SuperTrend direction; confirmation is best assessed on closed bars to avoid mid-bar oscillation. No higher-timeframe requests are used.
Resources: One hundred and two SuperTrend evaluations per bar, arrays for state, and a last-bar table render. This is efficient for the grid size but avoid stacking many instances.
Known limits: The flip model ignores costs, slippage, and short exposure. Rapid whipsaws can degrade both aggregation modes. Gradients are cosmetic and do not change logic.
Sensible Defaults & Quick Tuning
Start with the provided lower bounds and “Top Three” table.
Too many flips → raise the lower bound factor or period.
Too sluggish → lower the bounds or switch to additive mode.
Rankings feel unstable → prefer multiplicative mode and extend the normalization window.
Visuals too strong → increase gradient transparency or disable wick coloring.
What this indicator is—and isn’t
This is a parameter-sweep and visualization layer for SuperTrend selection. It is not a complete trading system, not predictive, and does not include position sizing, transaction costs, or risk management. Combine with market structure, higher-timeframe context, and explicit risk controls.
Attribution and refactor note: The original work is by KioseffTrading. The script has been refactored from approximately two thousand three hundred seventy-one lines to about three hundred eighty core lines, retaining behavior without compiler errors. The general simplification pattern is reusable for other indicators.
Metadata
Name/Tag: SuperTrend Optimizer Remastered
Pine version: v6
Overlay or separate pane: true (overlay)
Core idea/principle: Grid-based SuperTrend selection by cumulative flip returns with additive or multiplicative aggregation.
Primary outputs/signals: Auto-selected SuperTrend up and down lines, optional override lines, gradient bar and wick colors, “Long” labels, performance table.
Inputs with defaults: See Parameter Guide above.
Metrics/functions used: SuperTrend, ATR, arrays, barstate checks, windowed normalization, gamma-based contrast adjustment, table API, gradient utilities.
Special techniques: Fixed grid sweep, compounding vs linear aggregation, last-bar UI updates, gradient encoding of persistence.
Performance/constraints: One hundred and two SuperTrend calls, arrays of length one hundred and two, label budget, last-bar table updates, no higher-timeframe requests.
Recommended use-cases/workflows: Trend bias selection, quick parameter audits, override standardization across assets.
Compatibility/assets/timeframes: Standard OHLC charts across intraday to daily; liquid instruments recommended.
Limitations/risks: Costs and slippage omitted; mid-bar instability possible; not suitable for synthetic chart types.
Debug/diagnostics: Ranking table, optional tested-range label; internal counters for consecutive trends.
Disclaimer
The content provided, including all code and materials, is strictly for educational and informational purposes only. It is not intended as, and should not be interpreted as, financial advice, a recommendation to buy or sell any financial instrument, or an offer of any financial product or service. All strategies, tools, and examples discussed are provided for illustrative purposes to demonstrate coding techniques and the functionality of Pine Script within a trading context.
Any results from strategies or tools provided are hypothetical, and past performance is not indicative of future results. Trading and investing involve high risk, including the potential loss of principal, and may not be suitable for all individuals. Before making any trading decisions, please consult with a qualified financial professional to understand the risks involved.
By using this script, you acknowledge and agree that any trading decisions are made solely at your discretion and risk.
Do not use this indicator on Heikin-Ashi, Renko, Kagi, Point-and-Figure, or Range charts, as these chart types can produce unrealistic results for signal markers and alerts.
Best regards and happy trading
Chervolino

Screener based on Profitunity strategy for multiple timeframes
Screener based on Profitunity strategy by Bill Williams for multiple timeframes (max 5, including chart timeframe) and customizable symbol list. The screener analyzes the Alligator and Awesome Oscillator indicators, Divergent bars and high volume bars.
The maximum allowed number of requests (symbols and timeframes) is limited to 40 requests, for example, for 10 symbols by 4 requests of different timeframes. Therefore, the indicator automatically limits the number of displayed symbols depending on the number of timeframes for each symbol, if there are more symbols than are displayed in the screener table, then the ordinal numbers are displayed to the left of the symbols, in this case you can display the next group of symbols by increasing the value by 1 in the "Show tickers from" field, if the "Group" field is enabled, or specify the symbol number by 1 more than the last symbol in the screener table. 👀 When timeframe filtering is applied, the screener table displays only the columns of those timeframes for which the filtering value is selected, which allows displaying more symbols.
For each timeframe, in the "TIMEFRAMES > Prev" field, you can enable the display of data for the previous bar relative to the last (current) one, if the market is open for the requested symbol. In the "TIMEFRAMES > Y" field, you can enable filtering depending on the location of the last five bars relative to the Alligator indicator lines, which are designated by special symbols in the screener table:
⬆️ — if the Alligator is open upwards (Lips > Teeth > Jaw) and none of the bars is closed below the Lips line;
↗️ — if one of the bars, except for the penultimate one, is closed below Lips, or two bars, except for the last one, are closed below Lips, or the Alligator is open upwards only below four bars, but none of the bars is closed below Lips;
⬇️ — if the Alligator is open downwards (Lips < Teeth < Jaw), but none of the bars is closed above Lips;
↘️ — if one of the bars, except the penultimate one, is closed above the Lips, or two bars, except the last one, are closed above the Lips, or the Alligator is open down only above four bars, but none of the bars are closed above the Lips;
➡️ — in other cases, including when the Alligator lines intersect and one of the bars is closed behind the Lips line or two bars intersect one of the Alligator lines.
In the "TIMEFRAMES > Show bar change value for TF" field, you can add a column to the right of the selected timeframe column with the percentage change between the closing price of the last bar (current) and the closing price of the previous bar ((close – previous close) / previous close * 100). Depending on the percentage value, the background color of the screener table cell will change: dark red if <= -3%; red if <= -2%, light red if <= -0.5%; dark green if >= 3%; green if >= 2%; light green if >= 0.5%.
For each timeframe, the screener table displays the symbol of the latest (current) bar, depending on the closing price relative to the bar's midpoint ((high + low) / 2) and its location relative to the Alligator indicator lines: ⎾ — the bar's closing price is above its midpoint; ⎿ — the bar's closing price is below its midpoint; ├ — the bar's closing price is equal to its midpoint; 🟢 — Bullish Divergent bar, i.e. the bar's closing price is above its midpoint, the bar's high is below all Alligator lines, the bar's low is below the previous bar's low; 🔴 — Bearish Divergent bar, i.e. the bar's closing price is below its midpoint, the bar's low is above all Alligator lines, the bar's high is above the previous bar's high. When filtering is enabled in the "TIMEFRAMES > Filtering by Divergent bar" field, the data in the screener table cells will be displayed only for those timeframes that have a Divergent bar. A high bar volume signal is also displayed — 📶/📶² if the bar volume is greater than 40%/70% of the average volume value calculated using a simple moving average (SMA) in the 140 bar interval from the last bar.
In the indicator settings in the "SYMBOL LIST" field, each ticker (for example: OANDA:SPX500USD) must be on a separate line. If the market is closed, then the data for requested symbols will be limited to the time of the last (current) bar on the chart, for example, if the current symbol was traded yesterday, and the requested symbol is traded today, when requesting data for an hourly timeframe, the last bar will be for yesterday, if the timeframe of the current chart is not higher than 1 day. Therefore, by default, a warning will be displayed on the chart instead of the screener table that if the market is open, you must wait for the screener to load (after the first price change on the current chart), or if the highest timeframe in the screener is 1 day, you will be prompted to change the timeframe on the current chart to 1 week, if the screener requests data for the timeframe of 1 week, you will be prompted to change the timeframe on the current chart to 1 month, or switch to another symbol on the current chart for which the market is open (for example: BINANCE:BTCUSDT), or disable the warning in the field "SYMBOL LIST > Do not display screener if market is close".
The number of the last columns with the color of the AO indicator that will be displayed in the screener table for each timeframe is specified in the indicator settings in the "AWESOME OSCILLATOR > Number of columns" field.
For each timeframe, the direction of the trend between the price of the highest and lowest bars in the specified range of bars from the last bar is displayed — ↑ if the trend is up (the highest bar is to the right of the lowest), or ↓ if the trend is down (the lowest bar is to the right of the highest). If there is a divergence on the AO indicator in the specified interval, the symbol ∇ is also displayed. The average volume value is also calculated in the specified interval using a simple moving average (SMA). The number of bars is set in the indicator settings in the "INTERVAL FOR HIGHEST AND LOWEST BARS > Bars count" field.
In the indicator settings in the "STYLE" field you can change the position of the screener table relative to the chart window, the background color, the color and size of the text.
***
Скринер на основе стратегии Profitunity Билла Вильямса для нескольких таймфреймов (максимум 5, включая таймфрейм графика) и настраиваемого списка символов. Скринер анализирует индикаторы Alligator и Awesome Oscillator, Дивергентные бары и бары с высоким объемом.
Максимально допустимое количество запросов (символы и таймфреймы) ограничено 40 запросами, например, для 10 символов по 4 запроса разных таймфреймов. Поэтому в индикаторе автоматически ограничивается количество отображаемых символов в зависимости от количества таймфреймов для каждого символа, если символов больше чем отображено в таблице скринера, то слева от символов отображаются порядковые номера, в таком случае можно отобразить следующую группу символов, увеличив значение на 1 в настройках индикатора поле "Show tickers from", если включено поле "Group", или указать номер символа на 1 больше, чем последний символ в таблице скринера. 👀 Когда применяется фильтрация по таймфрейму, в таблице скринера отображаются только столбцы тех таймфреймов, для которых выбрано значение фильтрации, что позволяет отображать большее количество символов.
Для каждого таймфрейма в настройках индикатора в поле "TIMEFRAMES > Prev" можно включить отображение данных для предыдущего бара относительно последнего (текущего), если для запрашиваемого символа рынок открыт. В поле "TIMEFRAMES > Y" можно включить фильтрацию, в зависимости от расположения последних пяти баров относительно линий индикатора Alligator, которые обозначаются специальными символами в таблице скринера:
⬆️ — если Alligator открыт вверх (Lips > Teeth > Jaw) и ни один из баров не закрыт ниже линии Lips;
↗️ — если один из баров, кроме предпоследнего, закрыт ниже Lips, или два бара, кроме последнего, закрыты ниже Lips, или Alligator открыт вверх только ниже четырех баров, но ни один из баров не закрыт ниже Lips;
⬇️ — если Alligator открыт вниз (Lips < Teeth < Jaw), но ни один из баров не закрыт выше Lips;
↘️ — если один из баров, кроме предпоследнего, закрыт выше Lips, или два бара, кроме последнего, закрыты выше Lips, или Alligator открыт вниз только выше четырех баров, но ни один из баров не закрыт выше Lips;
➡️ — в остальных случаях, в то числе когда линии Alligator пересекаются и один из баров закрыт за линией Lips или два бара пересекают одну из линий Alligator.
В поле "TIMEFRAMES > Show bar change value for TF" можно добавить справа от выбранного столбца таймфрейма столбец с процентным изменением между ценой закрытия последнего бара (текущего) и ценой закрытия предыдущего бара ((close – previous close) / previous close * 100). В зависимости от величины процента будет меняться цвет фона ячейки таблицы скринера: темно-красный, если <= -3%; красный, если <= -2%, светло-красный, если <= -0.5%; темно-зеленый, если >= 3%; зеленый, если >= 2%; светло-зеленый, если >= 0.5%.
Для каждого таймфрейма в таблице скринера отображается символ последнего (текущего) бара, в зависимости от цены закрытия относительно середины бара ((high + low) / 2) и расположения относительно линий индикатора Alligator: ⎾ — цена закрытия бара выше его середины; ⎿ — цена закрытия бара ниже его середины; ├ — цена закрытия бара равна его середине; 🟢 — Бычий Дивергентный бар, т.е. цена закрытия бара выше его середины, максимум бара ниже всех линий Alligator, минимум бара ниже минимума предыдущего бара; 🔴 — Медвежий Дивергентный бар, т.е. цена закрытия бара ниже его середины, минимум бара выше всех линий Alligator, максимум бара выше максимума предыдущего бара. При включении фильтрации в поле "TIMEFRAMES > Filtering by Divergent bar" данные в ячейках таблицы скринера будут отображаться только для тех таймфреймов, где есть Дивергентный бар. Также отображается сигнал высокого объема бара — 📶/📶², если объем бара больше чем на 40%/70% среднего значения объема, рассчитанного с помощью простой скользящей средней (SMA) в интервале 140 баров от последнего бара.
В настройках индикатора в поле "SYMBOL LIST" каждый тикер (например: OANDA:SPX500USD) должен быть на отдельной строке. Если рынок закрыт, то данные для запрашиваемых символов будут ограничены временем последнего (текущего) бара на графике, например, если текущий символ торговался последний день вчера, а запрашиваемый символ торгуется сегодня, при запросе данных для часового таймфрейма, последний бар будет за вчерашний день, если таймфрейм текущего графика не выше 1 дня. Поэтому по умолчанию на графике будет отображаться предупреждение вместо таблицы скринера о том, что если рынок открыт, то необходимо дождаться загрузки скринера (после первого изменения цены на текущем графике), или если в скринере самый высокий таймфрейм 1 день, то будет предложено изменить на текущем графике таймфрейм на 1 неделю, если в скринере запрашиваются данные для таймфрейма 1 неделя, то будет предложено изменить на текущем графике таймфрейм на 1 месяц, или же переключиться на другой символ на текущем графике, для которого рынок открыт (например: BINANCE:BTCUSDT), или отключить предупреждение в поле "SYMBOL LIST > Do not display screener if market is close".
Количество последних столбцов с цветом индикатора AO, которые будут отображены в таблице скринера для каждого таймфрейма, указывается в настройках индикатора в поле "AWESOME OSCILLATOR > Number of columns".
Для каждого таймфрейма отображается направление тренда между ценой самого высокого и самого низкого баров в указанном интервале баров от последнего бара — ↑, если тренд направлен вверх (самый высокий бар справа от самого низкого), или ↓, если тренд направлен вниз (самый низкий бар справа от самого высокого). Если есть дивергенция на индикаторе AO в указанном интервале, то также отображается символ — ∇. В указанном интервале также рассчитывается среднее значение объема с помощью простой скользящей средней (SMA). Количество баров устанавливается в настройках индикатора в поле "INTERVAL FOR HIGHEST AND LOWEST BARS > Bars count".
В настройках индикатора в поле "STYLE" можно изменить положение таблицы скринера относительно окна графика, цвет фона, цвет и размер текста.

Adaptive ATR Limits█ OVERVIEW
This indicator plots adaptive ATR limits for intraday trading. A key feature of this indicator, which makes it different from other ATR limit indicators, is that the top and bottom ATR limit lines are always exactly one ATR apart from each other (in "auto" mode; there is also a "basic" mode, which plots the limits in the more traditional way—i.e., one ATR above the low and one ATR below the high at all times—and this can be used for comparison).
█ FEATURES
Provides an algorithm to plot the most reasonable intraday ATR top/bottom limits based on currently available information
Dynamically adapts limits as the price evolves during the day
Works correctly and consistently on both RTH and ETH charts
Has a user-selected ADR mode to base the limits on ADR instead of ATR
Option to include the current pre-market and previous day's post-market range in the calculation
Configurable ATR/ADR averaging length
Provides a visual smoothing option
Provides an information box showing the current numerical ATR/ADR values
Reasonable defaults that work well if the user changes nothing
Well-documented, high-quality, open-source code for those interested
█ HOW TO USE
At a minimum, there is nothing that needs to be set. The defaults work well. The ATR top line (red, configurable) gives you the most reasonable move given the currently available information. The line will move away from the price as the price approaches it; that is normal—it is reacting to new information. This happens until the ATR bottom limit hits the lower of the daily low and the previous day's close (in ATR mode). The ATR bottom line (green, configurable) works the same way, with reversed logic.
There is an option to use ADR instead of ATR. The ATR includes the previous day's RTH close in the range, whereas ADR does not. Another option allows the user to add the current day's pre-market range or the previous day's post-market into the current day's range, which has an effect if either of those went outside of today's RTH range, plus yesterday's RTH close (in the default ATR mode). Pre-market and post-market range is not typically included in the daily true range, so only change it if you really know you want it.
█ CONCEPTS
Most traditional ATR limit indicators plot the top ATR limit one ATR above the current daily low, and the bottom ATR limit one ATR below the current daily high. This indicator can also do that (in "basic" mode), but its value lies in its default "auto" mode, which uses an algorithm to dynamically adapt the ATR limits throughout the day, keeping them one ATR apart at all times. It tries to plot the most sensible ATR limits based on the current daily ATR, in order to provide a reasonable visual intraday target, given the available information at that point in time.
"Auto" mode is actually a weighted average of two methods: midpoint and relative (both of which can also be explicitly selected). The midpoint method places the midpoint of the ATR limit equal to the midpoint of the currently established daily range. The relative method measures the currently established daily range and calculates the position of the current price within it (as a ratio between 0 and 1). It then uses that value as a weight in a weighted average of extreme locations for the ATR limits, which are: the ATR top anchored to one ATR above the daily low, and the ATR bottom anchored to one ATR below the daily high.
The relative method is more advanced and better for most of the day; however, it can cause wild swings in the early market or pre-market before a reasonable range (as a percentage of ATR) has been established. "Auto" mode therefore takes another weighted average between the two methods, with the weight determined by the percentage of the ATR currently established within the day, more strongly weighting the calmer midpoint method before a good range is established. Once the full ATR has been achieved, the algorithm in "auto" mode will have fully switched to the relative method and will remain with that method for the rest of the day.
To explain the effect further, as an example, imagine that the price is approaching the full ATR range on the high side. At this point, the indicator will have almost fully transitioned to the second (relative) method. The lower ATR limit will now be anchored to the daily low as the price hits the upper ATR limit. If the price goes beyond the upper ATR, the lower ATR limit will stay anchored to the daily low, and the upper limit will stay anchored to one ATR above the lower limit. This allows you to see how far the price is going beyond the upper ATR limit. If the price then returns and backs off the upper ATR limit, the lower ATR limit will un-anchor from the daily low (it will actually rise, since the daily ATR range has been exceeded, so the lower ATR limit needs to come up because the actual daily range can’t fit into the ATR range anymore). The overall effect is to give you the best visual indication of where the price is in relation to a possible upper ATR-based target. Reverse this example for when the price low approaches the ATR range on the low side.
Care was taken so that the code uses no hard-coded time zones, exchanges, or session times. For this reason, it can in principle work globally. However, it very much depends on the information provided by the exchange, which is reflected in built-in Pine Script variables (see Limitations below).
█ LIMITATIONS
The indicator was developed for US/European equities and is tested on them only. It is also known to work on US futures; in this case, the whole 23-hour session is used, and the "Sessions to include in range" setting has no effect. It may or may not work as intended on security types and equities/futures for other countries.

MultiLayer Acceleration/Deceleration Strategy [Skyrexio]Overview
MultiLayer Acceleration/Deceleration Strategy leverages the combination of Acceleration/Deceleration Indicator(AC), Williams Alligator, Williams Fractals and Exponential Moving Average (EMA) to obtain the high probability long setups. Moreover, strategy uses multi trades system, adding funds to long position if it considered that current trend has likely became stronger. Acceleration/Deceleration Indicator is used for creating signals, while Alligator and Fractal are used in conjunction as an approximation of short-term trend to filter them. At the same time EMA (default EMA's period = 100) is used as high probability long-term trend filter to open long trades only if it considers current price action as an uptrend. More information in "Methodology" and "Justification of Methodology" paragraphs. The strategy opens only long trades.
Unique Features
No fixed stop-loss and take profit: Instead of fixed stop-loss level strategy utilizes technical condition obtained by Fractals and Alligator to identify when current uptrend is likely to be over (more information in "Methodology" and "Justification of Methodology" paragraphs)
Configurable Trading Periods: Users can tailor the strategy to specific market windows, adapting to different market conditions.
Multilayer trades opening system: strategy uses only 10% of capital in every trade and open up to 5 trades at the same time if script consider current trend as strong one.
Short and long term trend trade filters: strategy uses EMA as high probability long-term trend filter and Alligator and Fractal combination as a short-term one.
Methodology
The strategy opens long trade when the following price met the conditions:
1. Price closed above EMA (by default, period = 100). Crossover is not obligatory.
2. Combination of Alligator and Williams Fractals shall consider current trend as an upward (all details in "Justification of Methodology" paragraph)
3. Acceleration/Deceleration shall create one of two types of long signals (all details in "Justification of Methodology" paragraph). Buy stop order is placed one tick above the candle's high of last created long signal.
4. If price reaches the order price, long position is opened with 10% of capital.
5. If currently we have opened position and price creates and hit the order price of another one long signal, another one long position will be added to the previous with another one 10% of capital. Strategy allows to open up to 5 long trades simultaneously.
6. If combination of Alligator and Williams Fractals shall consider current trend has been changed from up to downtrend, all long trades will be closed, no matter how many trades has been opened.
Script also has additional visuals. If second long trade has been opened simultaneously the Alligator's teeth line is plotted with the green color. Also for every trade in a row from 2 to 5 the label "Buy More" is also plotted just below the teeth line. With every next simultaneously opened trade the green color of the space between teeth and price became less transparent.
Strategy settings
In the inputs window user can setup strategy setting: EMA Length (by default = 100, period of EMA, used for long-term trend filtering EMA calculation). User can choose the optimal parameters during backtesting on certain price chart.
Justification of Methodology
Let's explore the key concepts of this strategy and understand how they work together. We'll begin with the simplest: the EMA.
The Exponential Moving Average (EMA) is a type of moving average that assigns greater weight to recent price data, making it more responsive to current market changes compared to the Simple Moving Average (SMA). This tool is widely used in technical analysis to identify trends and generate buy or sell signals. The EMA is calculated as follows:
1.Calculate the Smoothing Multiplier:
Multiplier = 2 / (n + 1), Where n is the number of periods.
2. EMA Calculation
EMA = (Current Price) × Multiplier + (Previous EMA) × (1 − Multiplier)
In this strategy, the EMA acts as a long-term trend filter. For instance, long trades are considered only when the price closes above the EMA (default: 100-period). This increases the likelihood of entering trades aligned with the prevailing trend.
Next, let’s discuss the short-term trend filter, which combines the Williams Alligator and Williams Fractals. Williams Alligator
Developed by Bill Williams, the Alligator is a technical indicator that identifies trends and potential market reversals. It consists of three smoothed moving averages:
Jaw (Blue Line): The slowest of the three, based on a 13-period smoothed moving average shifted 8 bars ahead.
Teeth (Red Line): The medium-speed line, derived from an 8-period smoothed moving average shifted 5 bars forward.
Lips (Green Line): The fastest line, calculated using a 5-period smoothed moving average shifted 3 bars forward.
When the lines diverge and align in order, the "Alligator" is "awake," signaling a strong trend. When the lines overlap or intertwine, the "Alligator" is "asleep," indicating a range-bound or sideways market. This indicator helps traders determine when to enter or avoid trades.
Fractals, another tool by Bill Williams, help identify potential reversal points on a price chart. A fractal forms over at least five consecutive bars, with the middle bar showing either:
Up Fractal: Occurs when the middle bar has a higher high than the two preceding and two following bars, suggesting a potential downward reversal.
Down Fractal: Happens when the middle bar shows a lower low than the surrounding two bars, hinting at a possible upward reversal.
Traders often use fractals alongside other indicators to confirm trends or reversals, enhancing decision-making accuracy.
How do these tools work together in this strategy? Let’s consider an example of an uptrend.
When the price breaks above an up fractal, it signals a potential bullish trend. This occurs because the up fractal represents a shift in market behavior, where a temporary high was formed due to selling pressure. If the price revisits this level and breaks through, it suggests the market sentiment has turned bullish.
The breakout must occur above the Alligator’s teeth line to confirm the trend. A breakout below the teeth is considered invalid, and the downtrend might still persist. Conversely, in a downtrend, the same logic applies with down fractals.
In this strategy if the most recent up fractal breakout occurs above the Alligator's teeth and follows the last down fractal breakout below the teeth, the algorithm identifies an uptrend. Long trades can be opened during this phase if a signal aligns. If the price breaks a down fractal below the teeth line during an uptrend, the strategy assumes the uptrend has ended and closes all open long trades.
By combining the EMA as a long-term trend filter with the Alligator and fractals as short-term filters, this approach increases the likelihood of opening profitable trades while staying aligned with market dynamics.
Now let's talk about Acceleration/Deceleration signals. AC indicator is calculated using the Awesome Oscillator, so let's first of all briefly explain what is Awesome Oscillator and how it can be calculated. The Awesome Oscillator (AO), developed by Bill Williams, is a momentum indicator designed to measure market momentum by contrasting recent price movements with a longer-term historical perspective. It helps traders detect potential trend reversals and assess the strength of ongoing trends.
The formula for AO is as follows:
AO = SMA5(Median Price) − SMA34(Median Price)
where:
Median Price = (High + Low) / 2
SMA5 = 5-period Simple Moving Average of the Median Price
SMA 34 = 34-period Simple Moving Average of the Median Price
The Acceleration/Deceleration (AC) Indicator, introduced by Bill Williams, measures the rate of change in market momentum. It highlights shifts in the driving force of price movements and helps traders spot early signs of trend changes. The AC Indicator is particularly useful for identifying whether the current momentum is accelerating or decelerating, which can indicate potential reversals or continuations. For AC calculation we shall use the AO calculated above is the following formula:
AC = AO − SMA5(AO), where SMA5(AO)is the 5-period Simple Moving Average of the Awesome Oscillator
When the AC is above the zero line and rising, it suggests accelerating upward momentum.
When the AC is below the zero line and falling, it indicates accelerating downward momentum.
When the AC is below zero line and rising it suggests the decelerating the downtrend momentum. When AC is above the zero line and falling, it suggests the decelerating the uptrend momentum.
Now we can explain which AC signal types are used in this strategy. The first type of long signal is when AC value is below zero line. In this cases we need to see three rising bars on the histogram in a row after the falling one. The second type of signals occurs above the zero line. There we need only two rising AC bars in a row after the falling one to create the signal. The signal bar is the last green bar in this sequence. The strategy places the buy stop order one tick above the candle's high, which corresponds to the signal bar on AC indicator.
After that we can have the following scenarios:
Price hit the order on the next candle in this case strategy opened long with this price.
Price doesn't hit the order price, the next candle set lower high. If current AC bar is increasing buy stop order changes by the script to the high of this new bar plus one tick. This procedure repeats until price finally hit buy order or current AC bar become decreasing. In the second case buy order cancelled and strategy wait for the next AC signal.
If long trades are initiated, the strategy continues utilizing subsequent signals until the total number of trades reaches a maximum of 5. All open trades are closed when the trend shifts to a downtrend, as determined by the combination of the Alligator and Fractals described earlier.
Why we use AC signals? If currently strategy algorithm considers the high probability of the short-term uptrend with the Alligator and Fractals combination pointed out above and the long-term trend is also suggested by the EMA filter as bullish. Rising AC bars after period of falling AC bars indicates the high probability of local pull back end and there is a high chance to open long trade in the direction of the most likely main uptrend. The numbers of rising bars are different for the different AC values (below or above zero line). This is needed because if AC below zero line the local downtrend is likely to be stronger and needs more rising bars to confirm that it has been changed than if AC is above zero.
Why strategy use only 10% per signal? Sometimes we can see the false signals which appears on sideways. Not risking that much script use only 10% per signal. If the first long trade has been open and price continue going up and our trend approximation by Alligator and Fractals is uptrend, strategy add another one 10% of capital to every next AC signal while number of active trades no more than 5. This capital allocation allows to take part in long trades when current uptrend is likely to be strong and use only 10% of capital when there is a high probability of sideways.
Backtest Results
Operating window: Date range of backtests is 2023.01.01 - 2024.11.01. It is chosen to let the strategy to close all opened positions.
Commission and Slippage: Includes a standard Binance commission of 0.1% and accounts for possible slippage over 5 ticks.
Initial capital: 10000 USDT
Percent of capital used in every trade: 10%
Maximum Single Position Loss: -5.15%
Maximum Single Profit: +24.57%
Net Profit: +2108.85 USDT (+21.09%)
Total Trades: 111 (36.94% win rate)
Profit Factor: 2.391
Maximum Accumulated Loss: 367.61 USDT (-2.97%)
Average Profit per Trade: 19.00 USDT (+1.78%)
Average Trade Duration: 75 hours
How to Use
Add the script to favorites for easy access.
Apply to the desired timeframe and chart (optimal performance observed on 3h BTC/USDT).
Configure settings using the dropdown choice list in the built-in menu.
Set up alerts to automate strategy positions through web hook with the text: {{strategy.order.alert_message}}
Disclaimer:
Educational and informational tool reflecting Skyrex commitment to informed trading. Past performance does not guarantee future results. Test strategies in a simulated environment before live implementation
These results are obtained with realistic parameters representing trading conditions observed at major exchanges such as Binance and with realistic trading portfolio usage parameters.
Hybrid Adaptive Double Exponential Smoothing🙏🏻 This is HADES (Hybrid Adaptive Double Exponential Smoothing) : fully data-driven & adaptive exponential smoothing method, that gains all the necessary info directly from data in the most natural way and needs no subjective parameters & no optimizations. It gets applied to data itself -> to fit residuals & one-point forecast errors, all at O(1) algo complexity. I designed it for streaming high-frequency univariate time series data, such as medical sensor readings, orderbook data, tick charts, requests generated by a backend, etc.
The HADES method is:
fit & forecast = a + b * (1 / alpha + T - 1)
T = 0 provides in-sample fit for the current datum, and T + n provides forecast for n datapoints.
y = input time series
a = y, if no previous data exists
b = 0, if no previous data exists
otherwise:
a = alpha * y + (1 - alpha) * a
b = alpha * (a - a ) + (1 - alpha) * b
alpha = 1 / sqrt(len * 4)
len = min(ceil(exp(1 / sig)), available data)
sig = sqrt(Absolute net change in y / Sum of absolute changes in y)
For the start datapoint when both numerator and denominator are zeros, we define 0 / 0 = 1
...
The same set of operations gets applied to the data first, then to resulting fit absolute residuals to build prediction interval, and finally to absolute forecasting errors (from one-point ahead forecast) to build forecasting interval:
prediction interval = data fit +- resoduals fit * k
forecasting interval = data opf +- errors fit * k
where k = multiplier regulating intervals width, and opf = one-point forecasts calculated at each time t
...
How-to:
0) Apply to your data where it makes sense, eg. tick data;
1) Use power transform to compensate for multiplicative behavior in case it's there;
2) If you have complete data or only the data you need, like the full history of adjusted close prices: go to the next step; otherwise, guided by your goal & analysis, adjust the 'start index' setting so the calculations will start from this point;
3) Use prediction interval to detect significant deviations from the process core & make decisions according to your strategy;
4) Use one-point forecast for nowcasting;
5) Use forecasting intervals to ~ understand where the next datapoints will emerge, given the data-generating process will stay the same & lack structural breaks.
I advise k = 1 or 1.5 or 4 depending on your goal, but 1 is the most natural one.
...
Why exponential smoothing at all? Why the double one? Why adaptive? Why not Holt's method?
1) It's O(1) algo complexity & recursive nature allows it to be applied in an online fashion to high-frequency streaming data; otherwise, it makes more sense to use other methods;
2) Double exponential smoothing ensures we are taking trends into account; also, in order to model more complex time series patterns such as seasonality, we need detrended data, and this method can be used to do it;
3) The goal of adaptivity is to eliminate the window size question, in cases where it doesn't make sense to use cumulative moving typical value;
4) Holt's method creates a certain interaction between level and trend components, so its results lack symmetry and similarity with other non-recursive methods such as quantile regression or linear regression. Instead, I decided to base my work on the original double exponential smoothing method published by Rob Brown in 1956, here's the original source , it's really hard to find it online. This cool dude is considered the one who've dropped exponential smoothing to open access for the first time🤘🏻
R&D; log & explanations
If you wanna read this, you gotta know, you're taking a great responsability for this long journey, and it gonna be one hell of a trip hehe
Machine learning, apprentissage automatique, машинное обучение, digital signal processing, statistical learning, data mining, deep learning, etc., etc., etc.: all these are just artificial categories created by the local population of this wonderful world, but what really separates entities globally in the Universe is solution complexity / algorithmic complexity.
In order to get the game a lil better, it's gonna be useful to read the HTES script description first. Secondly, let me guide you through the whole R&D; process.
To discover (not to invent) the fundamental universal principle of what exponential smoothing really IS, it required the review of the whole concept, understanding that many things don't add up and don't make much sense in currently available mainstream info, and building it all from the beginning while avoiding these very basic logical & implementation flaws.
Given a complete time t, and yet, always growing time series population that can't be logically separated into subpopulations, the very first question is, 'What amount of data do we need to utilize at time t?'. Two answers: 1 and all. You can't really gain much info from 1 datum, so go for the second answer: we need the whole dataset.
So, given the sequential & incremental nature of time series, the very first and basic thing we can do on the whole dataset is to calculate a cumulative , such as cumulative moving mean or cumulative moving median.
Now we need to extend this logic to exponential smoothing, which doesn't use dataset length info directly, but all cool it can be done via a formula that quantifies the relationship between alpha (smoothing parameter) and length. The popular formulas used in mainstream are:
alpha = 1 / length
alpha = 2 / (length + 1)
The funny part starts when you realize that Cumulative Exponential Moving Averages with these 2 alpha formulas Exactly match Cumulative Moving Average and Cumulative (Linearly) Weighted Moving Average, and the same logic goes on:
alpha = 3 / (length + 1.5) , matches Cumulative Weighted Moving Average with quadratic weights, and
alpha = 4 / (length + 2) , matches Cumulative Weighted Moving Average with cubic weghts, and so on...
It all just cries in your shoulder that we need to discover another, native length->alpha formula that leverages the recursive nature of exponential smoothing, because otherwise, it doesn't make sense to use it at all, since the usual CMA and CMWA can be computed incrementally at O(1) algo complexity just as exponential smoothing.
From now on I will not mention 'cumulative' or 'linearly weighted / weighted' anymore, it's gonna be implied all the time unless stated otherwise.
What we can do is to approach the thing logically and model the response with a little help from synthetic data, a sine wave would suffice. Then we can think of relationships: Based on algo complexity from lower to higher, we have this sequence: exponential smoothing @ O(1) -> parametric statistics (mean) @ O(n) -> non-parametric statistics (50th percentile / median) @ O(n log n). Based on Initial response from slow to fast: mean -> median Based on convergence with the real expected value from slow to fast: mean (infinitely approaches it) -> median (gets it quite fast).
Based on these inputs, we need to discover such a length->alpha formula so the resulting fit will have the slowest initial response out of all 3, and have the slowest convergence with expected value out of all 3. In order to do it, we need to have some non-linear transformer in our formula (like a square root) and a couple of factors to modify the response the way we need. I ended up with this formula to meet all our requirements:
alpha = sqrt(1 / length * 2) / 2
which simplifies to:
alpha = 1 / sqrt(len * 8)
^^ as you can see on the screenshot; where the red line is median, the blue line is the mean, and the purple line is exponential smoothing with the formulas you've just seen, we've met all the requirements.
Now we just have to do the same procedure to discover the length->alpha formula but for double exponential smoothing, which models trends as well, not just level as in single exponential smoothing. For this comparison, we need to use linear regression and quantile regression instead of the mean and median.
Quantile regression requires a non-closed form solution to be solved that you can't really implement in Pine Script, but that's ok, so I made the tests using Python & sklearn:
paste.pics
^^ on this screenshot, you can see the same relationship as on the previous screenshot, but now between the responses of quantile regression & linear regression.
I followed the same logic as before for designing alpha for double exponential smoothing (also considered the initial overshoots, but that's a little detail), and ended up with this formula:
alpha = sqrt(1 / length) / 2
which simplifies to:
alpha = 1 / sqrt(len * 4)
Btw, given the pattern you see in the resulting formulas for single and double exponential smoothing, if you ever want to do triple (not Holt & Winters) exponential smoothing, you'll need len * 2 , and just len * 1 for quadruple exponential smoothing. I hope that based on this sequence, you see the hint that Maybe 4 rounds is enough.
Now since we've dealt with the length->alpha formula, we can deal with the adaptivity part.
Logically, it doesn't make sense to use a slower-than-O(1) method to generate input for an O(1) method, so it must be something universal and minimalistic: something that will help us measure consistency in our data, yet something far away from statistics and close enough to topology.
There's one perfect entity that can help us, this is fractal efficiency. The way I define fractal efficiency can be checked at the very beginning of the post, what matters is that I add a square root to the formula that is not typically added.
As explained in the description of my metric QSFS , one of the reasons for SQRT-transformed values of fractal efficiency applied in moving window mode is because they start to closely resemble normal distribution, yet with support of (0, 1). Data with this interesting property (normally distributed yet with finite support) can be modeled with the beta distribution.
Another reason is, in infinitely expanding window mode, fractal efficiency of every time series that exhibits randomness tends to infinitely approach zero, sqrt-transform kind of partially neutralizes this effect.
Yet another reason is, the square root might better reflect the dimensional inefficiency or degree of fractal complexity, since it could balance the influence of extreme deviations from the net paths.
And finally, fractals exhibit power-law scaling -> measures like length, area, or volume scale in a non-linear way. Adding a square root acknowledges this intrinsic property, while connecting our metric with the nature of fractals.
---
I suspect that, given analogies and connections with other topics in geometry, topology, fractals and most importantly positive test results of the metric, it might be that the sqrt transform is the fundamental part of fractal efficiency that should be applied by default.
Now the last part of the ballet is to convert our fractal efficiency to length value. The part about inverse proportionality is obvious: high fractal efficiency aka high consistency -> lower window size, to utilize only the last data that contain brand new information that seems to be highly reliable since we have consistency in the first place.
The non-obvious part is now we need to neutralize the side effect created by previous sqrt transform: our length values are too low, and exponentiation is the perfect candidate to fix it since translating fractal efficiency into window sizes requires something non-linear to reflect the fractal dynamics. More importantly, using exp() was the last piece that let the metric shine, any other transformations & formulas alike I've tried always had some weird results on certain data.
That exp() in the len formula was the last piece that made it all work both on synthetic and on real data.
^^ a standalone script calculating optimal dynamic window size
Omg, THAT took time to write. Comment and/or text me if you need
...
"Versace Pip-Boy, I'm a young gun coming up with no bankroll" 👻
∞
MultiLayer Awesome Oscillator Saucer Strategy [Skyrexio]Overview
MultiLayer Awesome Oscillator Saucer Strategy leverages the combination of Awesome Oscillator (AO), Williams Alligator, Williams Fractals and Exponential Moving Average (EMA) to obtain the high probability long setups. Moreover, strategy uses multi trades system, adding funds to long position if it considered that current trend has likely became stronger. Awesome Oscillator is used for creating signals, while Alligator and Fractal are used in conjunction as an approximation of short-term trend to filter them. At the same time EMA (default EMA's period = 100) is used as high probability long-term trend filter to open long trades only if it considers current price action as an uptrend. More information in "Methodology" and "Justification of Methodology" paragraphs. The strategy opens only long trades.
Unique Features
No fixed stop-loss and take profit: Instead of fixed stop-loss level strategy utilizes technical condition obtained by Fractals and Alligator to identify when current uptrend is likely to be over (more information in "Methodology" and "Justification of Methodology" paragraphs)
Configurable Trading Periods: Users can tailor the strategy to specific market windows, adapting to different market conditions.
Multilayer trades opening system: strategy uses only 10% of capital in every trade and open up to 5 trades at the same time if script consider current trend as strong one.
Short and long term trend trade filters: strategy uses EMA as high probability long-term trend filter and Alligator and Fractal combination as a short-term one.
Methodology
The strategy opens long trade when the following price met the conditions:
1. Price closed above EMA (by default, period = 100). Crossover is not obligatory.
2. Combination of Alligator and Williams Fractals shall consider current trend as an upward (all details in "Justification of Methodology" paragraph)
3. Awesome Oscillator shall create the "Saucer" long signal (all details in "Justification of Methodology" paragraph). Buy stop order is placed one tick above the candle's high of last created "Saucer signal".
4. If price reaches the order price, long position is opened with 10% of capital.
5. If currently we have opened position and price creates and hit the order price of another one "Saucer" signal another one long position will be added to the previous with another one 10% of capital. Strategy allows to open up to 5 long trades simultaneously.
6. If combination of Alligator and Williams Fractals shall consider current trend has been changed from up to downtrend, all long trades will be closed, no matter how many trades has been opened.
Script also has additional visuals. If second long trade has been opened simultaneously the Alligator's teeth line is plotted with the green color. Also for every trade in a row from 2 to 5 the label "Buy More" is also plotted just below the teeth line. With every next simultaneously opened trade the green color of the space between teeth and price became less transparent.
Strategy settings
In the inputs window user can setup strategy setting: EMA Length (by default = 100, period of EMA, used for long-term trend filtering EMA calculation). User can choose the optimal parameters during backtesting on certain price chart.
Justification of Methodology
Let's go through all concepts used in this strategy to understand how they works together. Let's start from the easies one, the EMA. Let's briefly explain what is EMA. The Exponential Moving Average (EMA) is a type of moving average that gives more weight to recent prices, making it more responsive to current price changes compared to the Simple Moving Average (SMA). It is commonly used in technical analysis to identify trends and generate buy or sell signals. It can be calculated with the following steps:
1.Calculate the Smoothing Multiplier:
Multiplier = 2 / (n + 1), Where n is the number of periods.
2. EMA Calculation
EMA = (Current Price) × Multiplier + (Previous EMA) × (1 − Multiplier)
In this strategy uses EMA an initial long term trend filter. It allows to open long trades only if price close above EMA (by default 50 period). It increases the probability of taking long trades only in the direction of the trend.
Let's go to the next, short-term trend filter which consists of Alligator and Fractals. Let's briefly explain what do these indicators means. The Williams Alligator, developed by Bill Williams, is a technical indicator designed to spot trends and potential market reversals. It uses three smoothed moving averages, referred to as the jaw, teeth, and lips:
Jaw (Blue Line): The slowest of the three, based on a 13-period smoothed moving average shifted 8 bars ahead.
Teeth (Red Line): The medium-speed line, derived from an 8-period smoothed moving average shifted 5 bars forward.
Lips (Green Line): The fastest line, calculated using a 5-period smoothed moving average shifted 3 bars forward.
When these lines diverge and are properly aligned, the "alligator" is considered "awake," signaling a strong trend. Conversely, when the lines overlap or intertwine, the "alligator" is "asleep," indicating a range-bound or sideways market. This indicator assists traders in identifying when to act on or avoid trades.
The Williams Fractals, another tool introduced by Bill Williams, are used to pinpoint potential reversal points on a price chart. A fractal forms when there are at least five consecutive bars, with the middle bar displaying the highest high (for an up fractal) or the lowest low (for a down fractal), relative to the two bars on either side.
Key Points:
Up Fractal: Occurs when the middle bar has a higher high than the two preceding and two following bars, suggesting a potential downward reversal.
Down Fractal: Happens when the middle bar shows a lower low than the surrounding two bars, hinting at a possible upward reversal.
Traders often combine fractals with other indicators to confirm trends or reversals, improving the accuracy of trading decisions.
How we use their combination in this strategy? Let’s consider an uptrend example. A breakout above an up fractal can be interpreted as a bullish signal, indicating a high likelihood that an uptrend is beginning. Here's the reasoning: an up fractal represents a potential shift in market behavior. When the fractal forms, it reflects a pullback caused by traders selling, creating a temporary high. However, if the price manages to return to that fractal’s high and break through it, it suggests the market has "changed its mind" and a bullish trend is likely emerging.
The moment of the breakout marks the potential transition to an uptrend. It’s crucial to note that this breakout must occur above the Alligator's teeth line. If it happens below, the breakout isn’t valid, and the downtrend may still persist. The same logic applies inversely for down fractals in a downtrend scenario.
So, if last up fractal breakout was higher, than Alligator's teeth and it happened after last down fractal breakdown below teeth, algorithm considered current trend as an uptrend. During this uptrend long trades can be opened if signal was flashed. If during the uptrend price breaks down the down fractal below teeth line, strategy considered that uptrend is finished with the high probability and strategy closes all current long trades. This combination is used as a short term trend filter increasing the probability of opening profitable long trades in addition to EMA filter, described above.
Now let's talk about Awesome Oscillator's "Sauser" signals. Briefly explain what is the Awesome Oscillator. The Awesome Oscillator (AO), created by Bill Williams, is a momentum-based indicator that evaluates market momentum by comparing recent price activity to a broader historical context. It assists traders in identifying potential trend reversals and gauging trend strength.
AO = SMA5(Median Price) − SMA34(Median Price)
where:
Median Price = (High + Low) / 2
SMA5 = 5-period Simple Moving Average of the Median Price
SMA 34 = 34-period Simple Moving Average of the Median Price
Now we know what is AO, but what is the "Saucer" signal? This concept was introduced by Bill Williams, let's briefly explain it and how it's used by this strategy. Initially, this type of signal is a combination of the following AO bars: we need 3 bars in a row, the first one shall be higher than the second, the third bar also shall be higher, than second. All three bars shall be above the zero line of AO. The price bar, which corresponds to third "saucer's" bar is our signal bar. Strategy places buy stop order one tick above the price bar which corresponds to signal bar.
After that we can have the following scenarios.
Price hit the order on the next candle in this case strategy opened long with this price.
Price doesn't hit the order price, the next candle set lower low. If current AO bar is increasing buy stop order changes by the script to the high of this new bar plus one tick. This procedure repeats until price finally hit buy order or current AO bar become decreasing. In the second case buy order cancelled and strategy wait for the next "Saucer" signal.
If long trades has been opened strategy use all the next signals until number of trades doesn't exceed 5. All trades are closed when the trend changes to downtrend according to combination of Alligator and Fractals described above.
Why we use "Saucer" signals? If AO above the zero line there is a high probability that price now is in uptrend if we take into account our two trend filters. When we see the decreasing bars on AO and it's above zero it's likely can be considered as a pullback on the uptrend. When we see the stop of AO decreasing and the first increasing bar has been printed there is a high probability that this local pull back is finished and strategy open long trade in the likely direction of a main trend.
Why strategy use only 10% per signal? Sometimes we can see the false signals which appears on sideways. Not risking that much script use only 10% per signal. If the first long trade has been open and price continue going up and our trend approximation by Alligator and Fractals is uptrend, strategy add another one 10% of capital to every next saucer signal while number of active trades no more than 5. This capital allocation allows to take part in long trades when current uptrend is likely to be strong and use only 10% of capital when there is a high probability of sideways.
Backtest Results
Operating window: Date range of backtests is 2023.01.01 - 2024.11.25. It is chosen to let the strategy to close all opened positions.
Commission and Slippage: Includes a standard Binance commission of 0.1% and accounts for possible slippage over 5 ticks.
Initial capital: 10000 USDT
Percent of capital used in every trade: 10%
Maximum Single Position Loss: -5.10%
Maximum Single Profit: +22.80%
Net Profit: +2838.58 USDT (+28.39%)
Total Trades: 107 (42.99% win rate)
Profit Factor: 3.364
Maximum Accumulated Loss: 373.43 USDT (-2.98%)
Average Profit per Trade: 26.53 USDT (+2.40%)
Average Trade Duration: 78 hours
These results are obtained with realistic parameters representing trading conditions observed at major exchanges such as Binance and with realistic trading portfolio usage parameters.
How to Use
Add the script to favorites for easy access.
Apply to the desired timeframe and chart (optimal performance observed on 3h BTC/USDT).
Configure settings using the dropdown choice list in the built-in menu.
Set up alerts to automate strategy positions through web hook with the text: {{strategy.order.alert_message}}
Disclaimer:
Educational and informational tool reflecting Skyrex commitment to informed trading. Past performance does not guarantee future results. Test strategies in a simulated environment before live implementation
Harmonic Pattern Detector (75 patterns)Harmonic Pattern Detector offers a record amount of "Harmonic Patterns" in one script, with 75 different patterns detected, together with up to 99 different swing lengths.
🔶 USAGE
Harmonic Patterns are detected from several different ZigZag lines, derived from Swings with different lengths (shorter - longer term)
Depending on the settings ' Minimum/Maximum Swing Length ', the user will see more or less patterns from shorter and/or longer-term swing points.
🔹 Fibonacci Ratio
Certain patterns have only one ratio for a specific retrace/extension instead of one upper and one lower limit. In this case, we add a ' Tolerance ', which adds a percentage tolerance below/above the ratio, creating two limits.
A higher number may show more patterns but may become less valid.
Hoovering over points B, C, and D will show a tooltip with the concerning limits; adjusted limits will be seen if applicable.
Tooltips in settings will also show which patterns the Fibonacci Ratio applies to.
🔹 Triangle Area Ratio
Using Heron's formula , the triangle area is calculated after the X-Y axis is normalized.
Users can filter patterns based on the ratio of the smallest triangle to the largest triangle.
A lower Triangle Area Ratio number leads to more symmetrical patterns but may appear less frequently.
🔶 DETAILS
Harmonic patterns are based on geometric patterns, where the retracement/extension of a swing point must be located between specific Fibonacci ratios of the previous swing/leg. Different Harmonic Patterns require unique ratios to become valid patterns.
In the above example there is a valid 'Max Butterfly' pattern where:
Point B is located between 0.618 - 0.886 retracement level of the X-A leg
Point C is located between 0.382 - 0.886 retracement level of the A-B leg
Point D is located between 1.272 - 2.618 extension level of the B-C leg
Point D is located between 1.272 - 1.618 extension level of the X-A leg
Harmonic Pattern Detector uses ZigZag lines, where swing highs and swing lows alternate. Each ZigZag line is checked for valid Harmonic Patterns . When multiple types of Harmonic Patterns are valid for the same sequence, the pattern will be named after the first one found.
Different swing lengths form different ZigZag lines.
By evaluating different ZigZag lines (up to 99!), shorter—and longer-term patterns can be drawn on the same chart.
🔹 Blocks
The patterns are organized into blocks that can be toggled on or off with a single click.
When a block is enabled, the user can still select which specific patterns within that block are enabled or disabled.
🔹 Visuals
Besides color settings, labels can show pattern names or arrows at point D of the pattern.
Note this will happen 1 bar after validation because one extra bar is needed for confirmation.
An option is included to show only arrows without the patterns.
🔹 Updated Patterns
When a Swing Low is followed by a lower low or a Swing High followed by a higher high , triggering a pattern identical to a previous one except with a different point D, the pattern will be updated. The previous C-D line will be visible as a dashed line to highlight the event. Only the last dashed line is shown when this happens more than once.
🔹 Optimization
The script only verifies the last leg in the initial phase, significantly reducing the time spent on pattern validation. If this leg doesn't align with a potential Harmonic Pattern , the pattern is immediately disregarded. In the subsequent phase, the remaining patterns are quickly scrutinized to ensure the next leg is valid. This efficient process continues, with only valid patterns progressing to the next phase until all sequences have been thoroughly examined.
This process can check up to 99 ZigZag lines for 75 different Harmonic Patterns , showcasing its high capacity and versatility.
🔹 Ratios
The following table shows the different ratios used for each Harmonic Pattern .
' min ' and ' max ' are used when only one limit is provided instead of 2. This limit is given a percentage tolerance above and below, customizable by the setting ' Tolerance - Fibonacci Ratio '.
For example a ratio of 0.618 with a tolerance of 1% would result in:
an upper limit of 0.624
a lower limit of 0.612
|-------------------|------------------------|------------------------|-----------------------|-----------------------|
| NAME PATTERN | BCD (BD) | ABC (AC) | XAB (XB) | XAD (XD) |
| | min max | min max | min max | min max |
|-------------------|------------------------|------------------------|-----------------------|-----------------------|
| 'ABCD' | 1.272 - 1.618 | 0.618 - 0.786 | | |
| '5-0' | 0.5 *min - 0.5 *max | 1.618 - 2.24 | 1.13 - 1.618 | |
| 'Max Gartley' | 1.128 - 2.236 | 0.382 - 0.886 | 0.382 - 0.618 | 0.618 - 0.786 |
| 'Gartley' | 1.272 - 1.618 | 0.382 - 0.886 | 0.618*min - 0.618*max | 0.786*min - 0.786*max |
| 'A Gartley' | 1.618*min - 1.618*max | 1.128 - 2.618 | 0.618 - 0.786 | 1.272*min - 1.272*max |
| 'NN Gartley' | 1.128 - 1.618 | 0.382 - 0.886 | 0.618*min - 0.618*max | 0.786*min - 0.786*max |
| 'NN A Gartley' | 1.618*min - 1.618*max | 1.128 - 2.618 | 0.618 - 0.786 | 1.272*min - 1.272*max |
| 'Bat' | 1.618 - 2.618 | 0.382 - 0.886 | 0.382 - 0.5 | 0.886*min - 0.886*max |
| 'Alt Bat' | 2.0 - 3.618 | 0.382 - 0.886 | 0.382*min - 0.382*max | 1.128*min - 1.128*max |
| 'A Bat' | 2.0 - 2.618 | 1.128 - 2.618 | 0.382 - 0.618 | 1.128*min - 1.128*max |
| 'Max Bat' | 1.272 - 2.618 | 0.382 - 0.886 | 0.382 - 0.618 | 0.886*min - 0.886*max |
| 'NN Bat' | 1.618 - 2.618 | 0.382 - 0.886 | 0.382 - 0.5 | 0.886*min - 0.886*max |
| 'NN Alt Bat' | 2.0 - 4.236 | 0.382 - 0.886 | 0.382*min - 0.382*max | 1.128*min - 1.128*max |
| 'NN A Bat' | 2.0 - 2.618 | 1.128 - 2.618 | 0.382 - 0.618 | 1.128*min - 1.128*max |
| 'NN A Alt Bat' | 2.618*min - 2.618*max | 1.128 - 2.618 | 0.236 - 0.5 | 0.886*min - 0.886*max |
| 'Butterfly' | 1.618 - 2.618 | 0.382 - 0.886 | 0.786*min - 0.786*max | 1.272 - 1.618 |
| 'Max Butterfly' | 1.272 - 2.618 | 0.382 - 0.886 | 0.618 - 0.886 | 1.272 - 1.618 |
| 'Butterfly 113' | 1.128 - 1.618 | 0.618 - 1.0 | 0.786 - 1.0 | 1.128*min - 1.128*max |
| 'A Butterfly' | 1.272*min - 1.272*max | 1.128 - 2.618 | 0.382 - 0.618 | 0.618 - 0.786 |
| 'Crab' | 2.24 - 3.618 | 0.382 - 0.886 | 0.382 - 0.618 | 1.618*min - 1.618*max |
| 'Deep Crab' | 2.618 - 3.618 | 0.382 - 0.886 | 0.886*min - 0.886*max | 1.618*min - 1.618*max |
| 'A Crab' | 1.618 - 2.618 | 1.128 - 2.618 | 0.276 - 0.446 | 0.618*min - 0.618*max |
| 'NN Crab' | 2.236 - 4.236 | 0.382 - 0.886 | 0.382 - 0.618 | 1.618*min - 1.618*max |
| 'NN Deep Crab' | 2.618 - 4.236 | 0.382 - 0.886 | 0.886*min - 0.886*max | 1.618*min - 1.618*max |
| 'NN A Crab' | 1.128 - 2.618 | 1.128 - 2.618 | 0.236 - 0.447 | 0.618*min - 0.618*max |
| 'NN A Deep Crab' | 1.128*min - 1.128*max | 1.128 - 2.618 | 0.236 - 0.382 | 0.618*min - 0.618*max |
| 'Cypher' | 1.272 - 2.00 | 1.13 - 1.414 | 0.382 - 0.618 | 0.786*min - 0.786*max |
| 'New Cypher' | 1.272 - 2.00 | 1.414 - 2.14 | 0.382 - 0.618 | 0.786*min - 0.786*max |
| 'Anti New Cypher' | 1.618 - 2.618 | 0.467 - 0.707 | 0.5 - 0.786 | 1.272*min - 1.272*max |
| 'Shark 1' | 1.618 - 2.236 | 1.128 - 1.618 | 0.382 - 0.618 | 0.886*min - 0.886*max |
| 'Shark 1 Alt' | 1.618 - 2.618 | 0.618 - 0.886 | 0.446 - 0.618 | 1.128*min - 1.128*max |
| 'Shark 2' | 1.618 - 2.236 | 1.128 - 1.618 | 0.382 - 0.618 | 1.128*min - 1.128*max |
| 'Shark 2 Alt' | 1.618 - 2.618 | 0.618 - 0.886 | 0.446 - 0.618 | 0.886*min - 0.886*max |
| 'Leonardo' | 1.128 - 2.618 | 0.382 - 0.886 | 0.5*min - 0.5*max | 0.786*min - 0.786*max |
| 'NN A Leonardo' | 2.0*min - 2.0*max | 1.128 - 2.618 | 0.382 - 0.886 | 1.272*min - 1.272*max |
| 'Nen Star' | 1.272 - 2.0 | 1.414 - 2.14 | 0.382 - 0.618 | 1.272*min - 1.272*max |
| 'Anti Nen Star' | 1.618 - 2.618 | 0.467 - 0.707 | 0.5 - 0.786 | 0.786*min - 0.786*max |
| '3 Drives' | 1.272 - 1.618 | 0.618 - 0.786 | 1.272 - 1.618 | 1.618 - 2.618 |
| 'A 3 Drives' | 0.618 - 0.786 | 1.272 - 1.618 | 0.618 - 0.786 | 0.13 - 0.886 |
| '121' | 0.382 - 0.786 | 1.128 - 3.618 | 0.5 - 0.786 | 0.382 - 0.786 |
| 'A 121' | 1.272 - 2.0 | 0.5 - 0.786 | 1.272 - 2.0 | 1.272 - 2.618 |
| '121 BG' | 0.618 - 0.707 | 1.128 - 1.733 | 0.5 - 0.577 | 0.447 - 0.786 |
| 'Black Swan' | 1.128 - 2.0 | 0.236 - 0.5 | 1.382 - 2.618 | 1.128 - 2.618 |
| 'White Swan' | 0.5 - 0.886 | 2.0 - 4.237 | 0.382 - 0.786 | 0.238 - 0.886 |
| 'NN White Swan' | 0.5 - 0.886 | 2.0 - 4.236 | 0.382 - 0.724 | 0.382 - 0.886 |
| 'Sea Pony' | 1.618 - 2.618 | 0.382 - 0.5 | 0.128 - 3.618 | 0.618 - 3.618 |
| 'Navarro 200' | 0.886 - 3.618 | 0.886 - 1.128 | 0.382 - 0.786 | 0.886 - 1.128 |
| 'May-00' | 0.5 - 0.618 | 1.618 - 2.236 | 1.128 - 1.618 | 0.5 - 0.618 |
| 'SNORM' | 0.9 - 1.1 | 0.9 - 1.1 | 0.9 - 1.1 | 0.618 - 1.618 |
| 'COL Poruchik' | 1.0 *min - 1.0 *max | 0.382 - 2.618 | 0.128 - 3.618 | 0.618 - 3.618 |
| 'Henry – David' | 0.618 - 0.886 | 0.44 - 0.618 | 0.128 - 2.0 | 0.618 - 1.618 |
| 'DAVID VM 1' | 1.618 - 1.618 | 0.382*min - 0.382*max | 0.128 - 1.618 | 0.618 - 3.618 |
| 'DAVID VM 2' | 1.618 - 1.618 | 0.382*min - 0.382*max | 1.618 - 3.618 | 0.618 - 7.618 |
| 'Partizan' | 1.618*min - 1.618*max | 0.382*min - 0.382*max | 0.128 - 3.618 | 0.618 - 3.618 |
| 'Partizan 2' | 1.618 - 2.236 | 1.128 - 1.618 | 0.128 - 3.618 | 1.618 - 3.618 |
| 'Partizan 2.1' | 1.618*min - 1.618*max | 1.128*min - 1.128*max | 0.128 - 3.618 | 0.618 - 3.618 |
| 'Partizan 2.2' | 2.236*min - 2.236*max | 1.128*min - 1.128*max | 0.128 - 3.618 | 0.618 - 3.618 |
| 'Partizan 2.3' | 1.618*min - 1.618*max | 0.618 - 1.618 | 0.128 - 3.618 | 0.618 - 3.618 |
| 'Partizan 2.4' | 2.236*min - 2.236*max | 1.618*min - 1.618*max | 0.128 - 3.618 | 0.618 - 3.618 |
| 'TOTAL' | 1.272 - 3.618 | 0.382 - 2.618 | 0.276 - 0.786 | 0.618 - 1.618 |
| 'TOTAL NN' | 1.272 - 4.236 | 0.382 - 2.618 | 0.236 - 0.786 | 0.618 - 1.618 |
| 'TOTAL 1' | 1.272 - 2.618 | 0.382 - 0.886 | 0.382 - 0.786 | 0.786 - 0.886 |
| 'TOTAL 2' | 1.618 - 3.618 | 0.382 - 0.886 | 0.382 - 0.786 | 1.128 - 1.618 |
| 'TOTNN 2NN' | 1.618 - 4.236 | 0.382 - 0.886 | 0.382 - 0.786 | 1.128 - 1.618 |
| 'TOTAL 3' | 1.272 - 2.618 | 1.128 - 2.618 | 0.276 - 0.618 | 0.618 - 0.886 |
| 'TOTNN 3NN' | 1.272 - 2.618 | 1.128 - 2.618 | 0.236 - 0.618 | 0.618 - 0.886 |
| 'TOTAL 4' | 1.618 - 2.618 | 1.128 - 2.618 | 0.382 - 0.786 | 1.128 - 1.272 |
| 'BG 1' | 2.618*min - 2.618*max | 0.382*min - 0.382*max | 0.128 - 0.886 | 1.0 *min - 1.0 *max |
| 'BG 2' | 2.237*min - 2.237*max | 0.447*min - 0.447*max | 0.128 - 0.886 | 1.0 *min - 1.0 *max |
| 'BG 3' | 2.0 *min - 2.0 *max | 0.5 *min - 0.5 *max | 0.128 - 0.886 | 1.0 *min - 1.0 *max |
| 'BG 4' | 1.618*min - 1.618*max | 0.618*min - 0.618*max | 0.128 - 0.886 | 1.0 *min - 1.0 *max |
| 'BG 5' | 1.414*min - 1.414*max | 0.707*min - 0.707*max | 0.128 - 0.886 | 1.0 *min - 1.0 *max |
| 'BG 6' | 1.272*min - 1.272*max | 0.786*min - 0.786*max | 0.128 - 0.886 | 1.0 *min - 1.0 *max |
| 'BG 7' | 1.171*min - 1.171*max | 0.854*min - 0.854*max | 0.128 - 0.886 | 1.0 *min - 1.0 *max |
| 'BG 8' | 1.128*min - 1.128*max | 0.886*min - 0.886*max | 0.128 - 0.886 | 1.0 *min - 1.0 *max |
|-------------------|------------------------|------------------------|-----------------------|-----------------------|
🔶 SETTINGS
🔹 Swings
Minimum Swing Length: Minimum length used for the swing detection.
Maximum Swing Length: Maximum length used for the swing detection.
🔹 Patterns
Toggle Pattern Block
Toggle separate pattern in each Pattern Block
🔹 Tolerance
Fibonacci Ratio: Adds a percentage tolerance below/above the ratio when only one ratio applies, creating two limits.
Triangle Area Ratio: Filters patterns based on the ratio of the smallest triangle to the largest triangle.
🔹 Display
Labels: Display Pattern Names, Arrows or nothing
Patterns: Display or not
Last Line: Display previous C-D line when updated
🔹 Style
Colors: Pattern Lines/Names/Arrows - background color of patterns
Text Size: Text Size of Pattern Names/Arrows
🔹 Calculation
Calculated Bars: Allows the usage of fewer bars for performance/speed improvement
Correlation Clusters [LuxAlgo]The Correlation Clusters is a machine learning tool that allows traders to group sets of tickers with a similar correlation coefficient to a user-set reference ticker.
The tool calculates the correlation coefficients between 10 user-set tickers and a user-set reference ticker, with the possibility of forming up to 10 clusters.
🔶 USAGE
Applying clustering methods to correlation analysis allows traders to quickly identify which set of tickers are correlated with a reference ticker, rather than having to look at them one by one or using a more tedious approach such as correlation matrices.
Tickers belonging to a cluster may also be more likely to have a higher mutual correlation. The image above shows the detailed parts of the Correlation Clusters tool.
The correlation coefficient between two assets allows traders to see how these assets behave in relation to each other. It can take values between +1.0 and -1.0 with the following meaning
Value near +1.0: Both assets behave in a similar way, moving up or down at the same time
Value close to 0.0: No correlation, both assets behave independently
Value near -1.0: Both assets have opposite behavior when one moves up the other moves down, and vice versa
There is a wide range of trading strategies that make use of correlation coefficients between assets, some examples are:
Pair Trading: Traders may wish to take advantage of divergences in the price movements of highly positively correlated assets; even highly positively correlated assets do not always move in the same direction; when assets with a correlation close to +1.0 diverge in their behavior, traders may see this as an opportunity to buy one and sell the other in the expectation that the assets will return to the likely same price behavior.
Sector rotation: Traders may want to favor some sectors that are expected to perform in the next cycle, tracking the correlation between different sectors and between the sector and the overall market.
Diversification: Traders can aim to have a diversified portfolio of uncorrelated assets. From a risk management perspective, it is useful to know the correlation between the assets in your portfolio, if you hold equal positions in positively correlated assets, your risk is tilted in the same direction, so if the assets move against you, your risk is doubled. You can avoid this increased risk by choosing uncorrelated assets so that they move independently.
Hedging: Traders may want to hedge positions with correlated assets, from a hedging perspective, if you are long an asset, you can hedge going long a negatively correlated asset or going short a positively correlated asset.
Grouping different assets with similar behavior can be very helpful to traders to avoid over-exposure to those assets, traders may have multiple long positions on different assets as a way of minimizing overall risk when in reality if those assets are part of the same cluster traders are maximizing their risk by taking positions on assets with the same behavior.
As a rule of thumb, a trader can minimize risk via diversification by taking positions on assets with no correlations, the proposed tool can effectively show a set of uncorrelated candidates from the reference ticker if one or more clusters centroids are located near 0.
🔶 DETAILS
K-means clustering is a popular machine-learning algorithm that finds observations in a data set that are similar to each other and places them in a group.
The process starts by randomly assigning each data point to an initial group and calculating the centroid for each. A centroid is the center of the group. K-means clustering forms the groups in such a way that the variances between the data points and the centroid of the cluster are minimized.
It's an unsupervised method because it starts without labels and then forms and labels groups itself.
🔹 Execution Window
In the image above we can see how different execution windows provide different correlation coefficients, informing traders of the different behavior of the same assets over different time periods.
Users can filter the data used to calculate correlations by number of bars, by time, or not at all, using all available data. For example, if the chart timeframe is 15m, traders may want to know how different assets behave over the last 7 days (one week), or for an hourly chart set an execution window of one month, or one year for a daily chart. The default setting is to use data from the last 50 bars.
🔹 Clusters
On this graph, we can see different clusters for the same data. The clusters are identified by different colors and the dotted lines show the centroids of each cluster.
Traders can select up to 10 clusters, however, do note that selecting 10 clusters can lead to only 4 or 5 returned clusters, this is caused by the machine learning algorithm not detecting any more data points deviating from already detected clusters.
Traders can fine-tune the algorithm by changing the 'Cluster Threshold' and 'Max Iterations' settings, but if you are not familiar with them we advise you not to change these settings, the defaults can work fine for the application of this tool.
🔹 Correlations
Different correlations mean different behaviors respecting the same asset, as we can see in the chart above.
All correlations are found against the same asset, traders can use the chart ticker or manually set one of their choices from the settings panel. Then they can select the 10 tickers to be used to find the correlation coefficients, which can be useful to analyze how different types of assets behave against the same asset.
🔶 SETTINGS
Execution Window Mode: Choose how the tool collects data, filter data by number of bars, time, or no filtering at all, using all available data.
Execute on Last X Bars: Number of bars for data collection when the 'Bars' execution window mode is active.
Execute on Last: Time window for data collection when the `Time` execution window mode is active. These are full periods, so `Day` means the last 24 hours, `Week` means the last 7 days, and so on.
🔹 Clusters
Number of Clusters: Number of clusters to detect up to 10. Only clusters with data points are displayed.
Cluster Threshold: Number used to compare a new centroid within the same cluster. The lower the number, the more accurate the centroid will be.
Max Iterations: Maximum number of calculations to detect a cluster. A high value may lead to a timeout runtime error (loop takes too long).
🔹 Ticker of Reference
Use Chart Ticker as Reference: Enable/disable the use of the current chart ticker to get the correlation against all other tickers selected by the user.
Custom Ticker: Custom ticker to get the correlation against all the other tickers selected by the user.
🔹 Correlation Tickers
Select the 10 tickers for which you wish to obtain the correlation against the reference ticker.
🔹 Style
Text Size: Select the size of the text to be displayed.
Display Size: Select the size of the correlation chart to be displayed, up to 500 bars.
Box Height: Select the height of the boxes to be displayed. A high height will cause overlapping if the boxes are close together.
Clusters Colors: Choose a custom colour for each cluster.

Ichimoku Theories [LuxAlgo]The Ichimoku Theories indicator is the most complete Ichimoku tool you will ever need. Four tools combined into one to harness all the power of Ichimoku Kinkō Hyō.
This tool features the following concepts based on the work of Goichi Hosoda:
Ichimoku Kinkō Hyō: Original Ichimoku indicator with its five main lines and kumo.
Time Theory: automatic time cycle identification and forecasting to understand market timing.
Wave Theory: automatic wave identification to understand market structure.
Price Theory: automatic identification of developing N waves and possible price targets to understand future price behavior.
🔶 ICHIMOKU KINKŌ HYŌ
Ichimoku with lines only, Kumo only and both together
Let us start with the basics: the Ichimoku original indicator is a tool to understand the market, not to predict it, it is a trend-following tool, so it is best used in trending markets.
Ichimoku tells us what is happening in the market and what may happen next, the aim of the tool is to provide market understanding, not trading signals.
The tool is based on calculating the mid-point between the high and low of three pre-defined ranges as the equilibrium price for short (9 periods), medium (26 periods), and long (52 periods) time horizons:
Tenkan sen: middle point of the range of the last 9 candles
Kinjun sen: middle point of the range of the last 26 candles
Senkou span A: middle point between Tankan Sen and Kijun Sen, plotted 26 candles into the future
Senkou span B: midpoint of the range of the last 52 candles, plotted 26 candles into the future
Chikou span: closing price plotted 26 candles into the past
Kumo: area between Senkou pans A and B (kumo means cloud in Japanese)
The most basic use of the tool is to use the Kumo as an area of possible support or resistance.
🔶 TIME THEORY
Current cycles and forecast
Time theory is a critical concept used to identify historical and current market cycles, and use these to forecast the next ones. This concept is based on the Kihon Suchi (translating to "Basic Numbers" in Japanese), these are 9 and 26, and from their combinations we obtain the following sequence:
9, 17, 26, 33, 42, 51, 65, 76, 129, 172, 200, 257
The main idea is that the market moves in cycles with periods set by the Kihon Suchi sequence.
When the cycle has the same exact periods, we obtain the Taito Suchi (translating to "Same Number" in Japanese).
This tool allows traders to identify historical and current market cycles and forecast the next one.
🔹 Time Cycle Identification
Presentation of 4 different modes: SWINGS, HIGHS, KINJUN, and WAVES .
The tool draws a horizontal line at the bottom of the chart showing the cycles detected and their size.
The following settings are used:
Time Cycle Mode: up to 7 different modes
Wave Cycle: Which wave to use when WAVE mode is selected, only active waves in the Wave Theory settings will be used.
Show Time Cycles: keep a cleaner chart by disabling cycles visualisation
Show last X time cycles: how many cycles to display
🔹 Time Cycle Forecast
Showcasing the two forecasting patterns: Kihon Suchi and Taito Suchi
The tool plots horizontal lines, a solid anchor line, and several dotted forecast lines.
The following settings are used:
Show time cycle forecast: to keep things clean
Forecast Pattern: comes in two flavors
Kihon Suchi plots a line from the anchor at each number in the Kihon Suchi sequence.
Taito Suchi plot lines from the anchor with the same size detected in the anchored cycle
Anchor forecast on last X time cycle: traders can place the anchor in any detected cycle
🔶 WAVE THEORY
All waves activated with overlapping
The main idea behind this theory is that markets move like waves in the sea, back and forth (making swing lows and highs). Understanding the current market structure is key to having realistic expectations of what the market may do next. The waves are divided into Simple and Complex.
The following settings are used:
Basic Waves: allows traders to activate waves I, V and N
Complex Waves: allows traders to activate waves P, Y and W
Overlapping waves: to avoid missing out on any of the waves activated
Show last X waves: how many waves will be displayed
🔹 Basic Waves
The three basic waves
The basic waves from which all waves are made are I, V, and N
I wave: one leg moves
V wave: two legs move, one against the other
N wave: Three legs move, push, pull back, and another push
🔹 Complex Waves
Three complex waves
There are other waves like
P wave: contracting market
Y wave: expanding market
W wave: double top or double bottom
🔶 PRICE THEORY
All targets for the current N wave with their calculations
This theory is based on identifying developing N waves and predicting potential price targets based on that developing wave.
The tool displays 4 basic targets (V, E, N, and NT) and 3 extended targets (2E and 3E) according to the calculations shown in the chart above. Traders can enable or disable each target in the settings panel.
🔶 USING EVERYTHING TOGETHER
Please DON'T do this. This is not how you use it
Now the real example:
Daily chart of Nasdaq 100 futures (NQ1!) with our Ichimoku analysis
Time, waves, and price theories go together as one:
First, we identify the current time cycles and wave structure.
Then we forecast the next cycle and possible key price levels.
We identify a Taito Suchi with both legs of exactly 41 candles on each I wave, both together forming a V wave, the last two I waves are part of a developing N wave, and the time cycle of the first one is 191 candles. We forecast this cycle into the future and get 22nd April as a key date, so in 6 trading days (as of this writing) the market would have completed another Taito Suchi pattern if a new wave and time cycle starts. As we have a developing N wave we can see the potential price targets, the price is actually between the NT and V targets. We have a bullish Kumo and the price is touching it, if this Kumo provides enough support for the price to go further, the market could reach N or E targets.
So we have identified the cycle and wave, our expectations are that the current cycle is another Taito Suchi and the current wave is an N wave, the first I wave went for 191 candles, and we expect the second and third I waves together to amount to 191 candles, so in theory the N wave would complete in the next 6 trading days making a swing high. If this is indeed the case, the price could reach the V target (it is almost there) or even the N target if the bulls have the necessary strength.
We do not predict the future, we can only aim to understand the current market conditions and have future expectations of when (time), how (wave), and where (price) the market will make the next turning point where one side of the market overcomes the other (bulls vs bears).
To generate this chart, we change the following settings from the default ones:
Swing length: 64
Show lines: disabled
Forecast pattern: TAITO SUCHI
Anchor forecast: 2
Show last time cycles: 5
I WAVE: enabled
N WAVE: disabled
Show last waves: 5
🔶 SETTINGS
Show Swing Highs & Lows: Enable/Disable points on swing highs and swing lows.
Swing Length: Number of candles to confirm a swing high or swing low. A higher number detects larger swings.
🔹 Ichimoku Kinkō Hyō
Show Lines: Enable/Disable the 5 Ichimoku lines: Kijun sen, Tenkan sen, Senkou span A & B and Chikou Span.
Show Kumo: Enable/Disable the Kumo (cloud). The Kumo is formed by 2 lines: Senkou Span A and Senkou Span B.
Tenkan Sen Length: Number of candles for Tenkan Sen calculation.
Kinjun Sen Length: Number of candles for the Kijun Sen calculation.
Senkou Span B Length: Number of candles for Senkou Span B calculation.
Chikou & Senkou Offset: Number of candles for Chikou and Senkou Span calculation. Chikou Span is plotted in the past, and Senkou Span A & B in the future.
🔹 Time Theory
Show Time Cycle Forecast: Enable/Disable time cycle forecast vertical lines. Disable for better performance.
Forecast Pattern: Choose between two patterns: Kihon Suchi (basic numbers) or Taito Suchi (equal numbers).
Anchor forecast on last X time cycle: Number of time cycles in the past to anchor the time cycle forecast. The larger the number, the deeper in the past the anchor will be.
Time Cycle Mode: Choose from 7 time cycle detection modes: Tenkan Sen cross, Kijun Sen cross, Kumo change between bullish & bearish, swing highs only, swing lows only, both swing highs & lows and wave detection.
Wave Cycle: Choose which type of wave to detect from 6 different wave types when the time cycle mode is set to WAVES.
Show Time Cycles: Enable/Disable time cycle horizontal lines. Disable for better performance.
how last X time cycles: Maximum number of time cycles to display.
🔹 Wave Theory
Basic Waves: Enable/Disable the display of basic waves, all at once or one at a time. Disable for better performance.
Complex Waves: Enable/Disable complex wave display, all at once or one by one. Disable for better performance.
Overlapping Waves: Enable/Disable the display of waves ending on the same swing point.
Show last X waves: 'Maximum number of waves to display.
🔹 Price Theory
Basic Targets: Enable/Disable horizontal price target lines. Disable for better performance.
Extended Targets: Enable/Disable extended price target horizontal lines. Disable for better performance.