Bitcoin Multibook v1.0 [Apollo Algo]Bitcoin Multibook v1.0 by Apollo Algo is an advanced market depth and order flow visualization tool that brings professional-grade multi-exchange order book analysis to TradingView. Inspired by Bookmap's multibook functionality and built upon LucF's original single "Tape" indicator concept, this tool aggregates real-time trading data from multiple Bitcoin exchanges into a unified tape display.
Credits & Attribution
This indicator is an evolution of the original "Tape" indicator created by LucF (TradingView: @LucF). The multibook enhancement and Bitcoin-specific optimizations were developed by Apollo Algo to provide traders with institutional-grade market microstructure visibility across major Bitcoin trading venues.
Purpose & Philosophy
Bitcoin leads the entire cryptocurrency market. By monitoring order flow across the primary Bitcoin exchanges simultaneously, traders gain crucial insights into:
Cross-exchange arbitrage opportunities
Institutional order flow patterns
Market maker positioning
True market sentiment beyond single-exchange data
Key Features
📊 Multi-Exchange Data Aggregation
Real-time tape from 3 major exchanges:
Binance (BTCUSDT)
Coinbase (BTCUSD)
Kraken (BTCUSD)
Customizable source inputs for any trading pair
Synchronized price and volume tracking
Exchange name identification in tape display
📈 Advanced Tape Display
Dynamic tape visualization with configurable line quantity (0-50 lines)
Directional flow indicators (+/- symbols for price changes)
Exchange identification for each trade
Volume precision control (0-16 decimal places)
Flexible positioning (9 screen positions available)
Real-time only operation for accurate order flow
🎯 Volume Delta Analysis
Real-time cumulative volume delta calculation
Divergence detection (price vs. volume direction)
Colored visual feedback for market sentiment
Total session delta displayed in footer
Cross-exchange delta aggregation
🚨 Smart Alert System
Marker 1: Volume Delta Bumps (⬆⬇)
Triggers on consecutive volume delta increases
Identifies momentum acceleration points
Filters out divergent movements
Marker 2: Volume Delta Thresholds (⇑⇓)
Fires when delta exceeds user-defined thresholds
Catches significant order imbalances
Excludes divergence conditions
Marker 3: Large Volume Detection (⤊⤋)
Highlights unusually large individual trades
Spots potential institutional activity
Direction-specific triggers
Configure Data Sources
Adjust exchange pairs if needed (e.g., for altcoin analysis)
Leave blank to disable specific exchanges
Use format: EXCHANGE:SYMBOL
Customize Display
Set tape line quantity based on screen size
Position the table for optimal visibility
Choose color scheme (text or background)
Adjust text size for readability
Configure Alerts
Enable desired markers (1, 2, or 3)
Set volume thresholds appropriate for your timeframe
Choose direction (Longs, Shorts, or Both)
Create TradingView alerts on marker signals
Trading Applications
Scalping (1-5 min)
Monitor tape speed for momentum shifts
Watch for cross-exchange divergences
Track large volume clusters
Use Marker 1 for quick momentum trades
Day Trading (5-60 min)
Identify accumulation/distribution phases
Spot institutional positioning
Confirm breakout validity with volume delta
Use Marker 2 for significant imbalances
Swing Trading (1H+)
Analyze volume delta trends
Detect smart money rotation
Time entries with order flow confirmation
Use Marker 3 for institutional footprints
Advanced Techniques
Cross-Exchange Arbitrage Detection
When price disparities appear between exchanges:
Immediate Opportunity: Price differences > 0.1%
Bot Activity: Rapid convergence patterns
Liquidity Vacuum: One exchange leading others
Divergence Trading Strategies
Volume delta diverging from price direction:
Absorption: Strong hands entering (price down, delta up)
Distribution: Smart money exiting (price up, delta down)
Reversal Setup: Sustained divergence over multiple bars
Institutional Footprint Recognition
Large volume characteristics:
Simultaneous Spikes: Same timestamp across exchanges
TWAP Patterns: Consistent volume over time
Iceberg Orders: Repeated same-size trades
Pine Script v6 Enhancements
Type Safety Improvements
Strict boolean type handling
Explicit type declarations
Enhanced error checking
Performance Optimizations
Improved request.security() function
Better memory management with arrays
Optimized table rendering
Modern Syntax Updates
indicator() instead of study()
Namespaced math functions (math.round())
Typed input functions (input.int(), input.float())
Performance Considerations
System Requirements
Real-time Data: Essential for tape operation
Multiple Security Calls: May impact performance
Array Operations: Memory intensive with high line counts
Table Rendering: CPU usage increases with tape size
Optimization Tips
Reduce tape lines for better performance
Increase volume filter to reduce noise
Disable unused markers
Use text-only coloring for faster rendering
"algo" için komut dosyalarını ara

Mustang Algo - Engulfing Detector🐎 MUSTANG ALGO - ENGULFING DETECTOR
An advanced engulfing candlestick pattern detector with customizable filters for more precise trading signals.
═══════════════════════════════════════
📊 WHAT IS THIS INDICATOR?
The Mustang Algo Engulfing Detector identifies bullish and bearish engulfing patterns with advanced filtering options to reduce false signals and improve trade quality. This indicator helps traders spot high-probability reversal opportunities based on candlestick patterns and trend confirmation.
═══════════════════════════════════════
✨ KEY FEATURES
🔹 Engulfing Pattern Detection
• Bullish Engulfing: Identifies potential bullish reversals
• Bearish Engulfing: Identifies potential bearish reversals
• Real-time signal labels (BUY/SELL)
🔹 Size Filter
• Filter out small, insignificant candles
• Adjustable minimum body size percentage
• Optional filter for the engulfed candle size
• Ensures only strong patterns are detected
🔹 EMA Trend Filter
• Customizable EMA period (default: 200)
• BUY signals only above EMA (uptrend)
• SELL signals only below EMA (downtrend)
• Visual EMA line on chart
• Reduces counter-trend false signals
═══════════════════════════════════════
🎯 HOW TO USE
1. Add the indicator to your chart
2. Adjust the filters according to your trading style
3. Wait for BUY (green) or SELL (red) labels
4. Confirm with your own analysis and risk management
5. Trade in the direction of the signal
⚠️ IMPORTANT: This indicator should be used in conjunction with proper risk management and additional analysis. No indicator is 100% accurate.
═══════════════════════════════════════
⚙️ CUSTOMIZABLE SETTINGS
📏 Size Filter Group:
• Enable/Disable size filtering
• Min Body Size (%): Minimum candle body size to generate signals (0.01% - 10%)
• Check Engulfed Candle Size: Also verify the size of the engulfed candle
• Min Engulfed Body Size (%): Minimum size for the engulfed candle
📈 EMA Filter Group:
• Enable/Disable EMA filtering
• EMA Length: Period for the EMA calculation (default: 200)
• Show EMA on Chart: Display the EMA line
═══════════════════════════════════════
💡 BEST PRACTICES
✅ Use on higher timeframes (4H, Daily) for better reliability
✅ Combine with support/resistance levels
✅ Wait for candle close confirmation before entering
✅ Use proper stop-loss and take-profit levels
✅ Consider market context and overall trend
❌ Don't trade every signal blindly
❌ Don't ignore risk management
❌ Don't use on very low timeframes without additional filters
═══════════════════════════════════════
📈 RECOMMENDED SETTINGS
Conservative Trading:
• Min Body Size: 0.8% - 1.0%
• EMA Filter: Enabled (200 period)
• Check Engulfed Size: Enabled
Aggressive Trading:
• Min Body Size: 0.3% - 0.5%
• EMA Filter: Disabled or lower period (50-100)
• Check Engulfed Size: Disabled
═══════════════════════════════════════
🔒 DISCLAIMER
This indicator is provided for educational and informational purposes only. Past performance is not indicative of future results. Always conduct your own research and use proper risk management. Trading involves substantial risk of loss.
═══════════════════════════════════════
Created by Mustang Algo
Version 1.0
If you find this indicator helpful, please leave a like and comment! 🚀

Otekura Range Trade Algorithm [Tradebuddies]The Range Trade Algorithm calculates the levels for Monday.
On the chart you will see that the Monday levels will be marked as 1 0 -1.
The M High level calculates Monday's high close and plots it on the screen.
M Low calculates the low close of Monday and plots it on the screen.
The coloured lines on the screen are the points of the range levels formulated with fibonacci values.
The indicator has its own Value table. The prices of the levels are written.
Potential Range breakout targets tell prices at points matching the fibonacci values. These are Take profit or reversal points.
Buy and Sell indicators are determined by the range breakout.
Users can set an alarm on the indicator and receive direct notification with their targets when a new range occurs.
Fib values are multiplied by range values and create an average target according to the price situation. These values represent an area. Breakdown targets show that the target is targeted until the area.

UNITY[ALGO] PO3 V3Of course. Here is a complete and professional description in English for the indicator we have built, detailing all of its features and functionalities.
Indicator: UNITY PO3 V7.2
Overview
The UNITY PO3 is an advanced, multi-faceted technical analysis tool designed to identify high-probability reversal setups based on the Swing Failure Pattern (SFP). It combines real-time SFP detection on the current timeframe with a sophisticated analysis of key institutional liquidity zones from the H4 timeframe, presenting all information in a clear, dynamic, and interactive visual interface.
This indicator is built for traders who use liquidity concepts, providing a complete dashboard of entries, targets, and invalidation levels directly on the chart.
Core Features & Functionality
1. Swing Failure Pattern (SFP) Detection (Current Timeframe)
The indicator's primary engine identifies SFPs on the chart's active timeframe with two layers of logic:
Standard SFP: Detects a classic liquidity sweep where the current candle's wick takes out the high or low of the previous candle and the body closes back within the previous candle's range.
Outside Bar SFP Logic: Intelligently analyzes engulfing candles that sweep both the high and low of the previous candle. A valid signal is only generated if the candle has a clear directional close:
Bullish Signal: If the outside bar closes higher than its open.
Bearish Signal: If the outside bar closes lower than its open.
Neutral (doji-like) outside bars are ignored to filter for indecision.
2. Comprehensive On-Chart SFP Markings
When a valid SFP is detected, a full suite of dynamic drawings appears on the chart:
Failure Line: A dashed line (red for bearish, green for bullish) marking the precise price level of the liquidity sweep.
PREMIUM ZONE (SFP Candle Wick): A transparent, colored rectangle highlighting the rejection wick of the signal candle (the upper wick for bearish SFPs, the lower wick for bullish SFPs). This zone automatically extends to the right, following the current price, until the DOL is hit.
CRT BOX (Reference Candle): A transparent box with a colored border drawn around the entire range of the candle that was swept (Candle 1). This highlights the full liquidity zone and also extends dynamically until the DOL is hit.
Dynamic Target Line: A blue dashed line marking the primary objective (the low of the signal candle for shorts, the high for longs).
The line begins with a "⏳ Target" label and extends with the current price.
Upon being touched by price, the line freezes, and its label permanently changes to "✅ Target".
Dynamic DOL (Draw on Liquidity) Line: An orange dashed line marking the invalidation level, defined as the opposite extremity of the swept candle (Candle 1).
It begins with a "⏳ dol" label and extends with the price.
Upon being touched, it freezes, and its label changes to "✅ dol".
3. Multi-Session Killzone Liquidity Levels (H4 Analysis)
The indicator automatically analyzes the H4 timeframe in the background to identify and plot key liquidity levels from three major trading sessions, based on their UTC opening times.
1am Killzone (London Lunch): Tracks the high/low of the 05:00 UTC H4 candle.
5am Killzone (London Open): Tracks the high/low of the 09:00 UTC H4 candle.
9am Killzone (NY Open): Tracks the high/low of the 13:00 UTC H4 candle.
For each of these Killzones, the indicator provides two types of analysis:
Last KZ Lines: Plots the high and low of the most recent qualifying Killzone candle. These lines are dynamic, extending with price and showing a ⏳/✅ status when touched.
Fresh Zones: A powerful feature that scans the entire available history of Killzones to find and display the closest untouched high (above the current price) and the closest untouched low (below the current price). These "Fresh" lines are also fully dynamic and provide a real-time view of the most relevant nearby liquidity targets.
4. Advanced User Settings & Chart Management
The indicator is designed for a clean and user-centric experience with powerful customization:
Show Only Last SFP: Keeps the chart clean by automatically deleting the previous SFP setup when a new one appears.
Hide SFP on DOL Reset: When checked, automatically removes all drawings related to an SFP setup the moment its invalidation level (DOL line) is touched. This leaves only active, valid setups on the chart.
Hide Consumed KZ: When checked, automatically removes any Killzone or Fresh Zone line from the chart as soon as it is touched by the price.
Independent Toggles: Every visual element—SFP signals, each of the three Killzones, and their respective "Fresh" zone counterparts—can be turned on or off independently from the settings menu for complete control over the visual display.
Z-Order Priority: All indicator drawings are rendered in front of the chart candles, ensuring they are always clearly visible and never hidden from view.
Week Window AlgorithmWeek Window Algorithm
The Week Window Algorithm is an advanced intraday trading overlay built for precision session tracking and key level visualization.
🔹 Features:
1. Time Lines
Automatically plots vertical lines 30 minutes ahead of specific London times (07, 08, 09, 13, 14, 15UK), with adjustable height in pips and custom color.
2. Session Boxes
Draws price range boxes for:
Asia (22:00–06:00 UK)
Europe AM (08:00–09:00 UK)
Europe PM (14:00–15:00 UK)
Each box auto-updates during the session and fades after 3 days. Fill color is fully customizable via settings.
3. Yesterday’s High/Low Levels
Captures and plots yesterday’s high and low at 23:00 UK. Lines extend through today and highlight first-time hits.
🛠️ Customization:
Enable/disable sessions individually
Set pip size for early lines
Choose colors for each session box and line style
🕒 Recommended Timeframes:
Optimized for 1–15 minute charts. Works best on intraday setups.

Harish algo for nifty and bankniftyHarish algo for nifty and banknifty
Overview
Harish Algo - Buy and Sell 11 is a powerful trading indicator designed for intraday traders, incorporating multiple technical analysis concepts to identify potential breakout and breakdown levels. It uses pivot points, exponential moving averages (EMAs), and volatility-based levels to generate buy and sell signals with visual markers for better decision-making.
Features & Functionality
✅ Pivot Points Calculation:
The indicator calculates daily pivot points along with resistance (R1) and support (S1) levels.
Helps in identifying potential reversal or breakout areas.
✅ EMA Trend Confirmation:
Uses three EMAs (21, 55, and 200) to confirm trend direction.
Ensures that buy signals align with uptrends and sell signals align with downtrends.
✅ 15-Minute Candle Analysis for Precision:
Captures the last three 15-minute closes of the previous day.
Computes an average and determines volatility-based price levels to anticipate price movements.
✅ Dynamic Buy & Sell Signals:
Bullish (Buy) Signals:
Price breaks above key resistance levels and EMAs confirm an uptrend.
Displayed as yellow (tiny) or green (small) upward triangles below candles.
Bearish (Sell) Signals:
Price drops below key support levels with EMA confirmation of a downtrend.
Displayed as fuchsia (tiny) or red (small) downward triangles above candles.
✅ Alerts for Trade Execution:
Get notified instantly with alerts when a buy or sell signal is triggered.
✅ Customizable Settings:
Modify EMA lengths and adjust parameters to fit different trading strategies.
Usage & Benefits
🔹 Helps traders identify potential entry and exit points with precision.
🔹 Reduces false signals by combining pivot points, EMAs, and price action.
🔹 Works best for intraday traders in the Indian stock markets, but can be applied to other markets as well.
🔹 Suitable for both beginners and experienced traders looking for a structured approach to trading.
How to Use
Add the indicator to your chart.
Observe the plotted pivot points, EMAs, and price levels.
Watch for triangle markers (buy/sell signals).
Use alerts to receive real-time notifications.
Combine with your own risk management strategy for best results.
🔹 Works on all timeframes but optimized for intraday trading.
Disclaimer
📢 This indicator is for educational purposes only and should not be considered financial advice. Always perform your own analysis before taking trades.

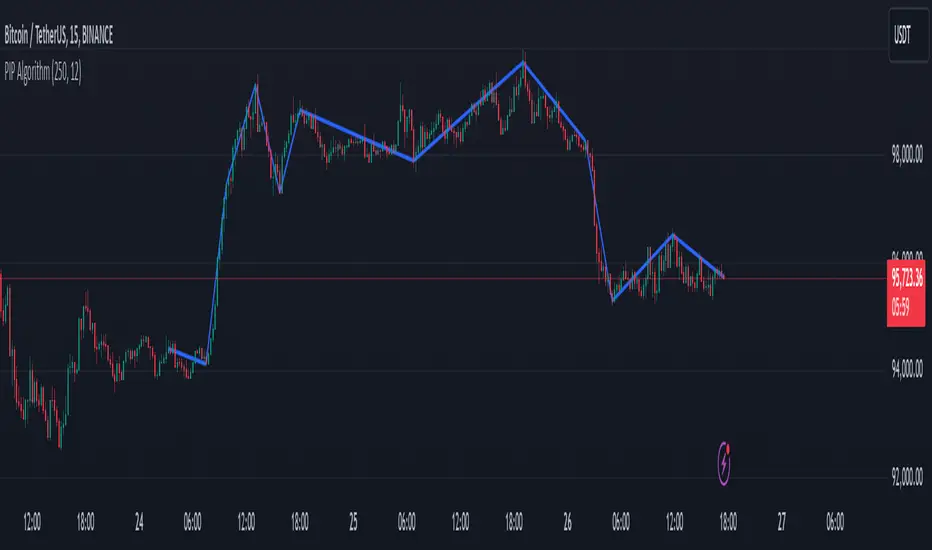
PIP Algorithm
# **Script Overview (For Non-Coders)**
1. **Purpose**
- The script tries to capture the essential “shape” of price movement by selecting a limited number of “key points” (anchors) from the latest bars.
- After selecting these anchors, it draws straight lines between them, effectively simplifying the price chart into a smaller set of points without losing major swings.
2. **How It Works, Step by Step**
1. We look back a certain number of bars (e.g., 50).
2. We start by drawing a straight line from the **oldest** bar in that range to the **newest** bar—just two points.
3. Next, we find the bar whose price is *farthest away* from that straight line. That becomes a new anchor point.
4. We “snap” (pin) the line to go exactly through that new anchor. Then we re-draw (re-interpolate) the entire line from the first anchor to the last, in segments.
5. We repeat the process (adding more anchors) until we reach the desired number of points. Each time, we choose the biggest gap between our line and the actual price, then re-draw the entire shape.
6. Finally, we connect these anchors on the chart with red lines, visually simplifying the price curve.
3. **Why It’s Useful**
- It highlights the most *important* bends or swings in the price over the chosen window.
- Instead of plotting every single bar, it condenses the information down to the “key turning points.”
4. **Key Takeaway**
- You’ll see a small number of red line segments connecting the **most significant** points in the price data.
- This is especially helpful if you want a simplified view of recent price action without minor fluctuations.
## **Detailed Logic Explanation**
# **Script Breakdown (For Coders)**
//@version=5
indicator(title="PIP Algorithm", overlay=true)
// 1. Inputs
length = input.int(50, title="Lookback Length")
num_points = input.int(5, title="Number of PIP Points (≥ 3)")
// 2. Helper Functions
// ---------------------------------------------------------------------
// reInterpSubrange(...):
// Given two “anchor” indices in `linesArr`, linearly interpolate
// the array values in between so that the subrange forms a straight line
// from linesArr to linesArr .
reInterpSubrange(linesArr, segmentLeft, segmentRight) =>
float leftVal = array.get(linesArr, segmentLeft)
float rightVal = array.get(linesArr, segmentRight)
int segmentLen = segmentRight - segmentLeft
if segmentLen > 1
for i = segmentLeft + 1 to segmentRight - 1
float ratio = (i - segmentLeft) / segmentLen
float interpVal = leftVal + (rightVal - leftVal) * ratio
array.set(linesArr, i, interpVal)
// reInterpolateAllSegments(...):
// For the entire “linesArr,” re-interpolate each subrange between
// consecutive breakpoints in `lineBreaksArr`.
// This ensures the line is globally correct after each new anchor insertion.
reInterpolateAllSegments(linesArr, lineBreaksArr) =>
array.sort(lineBreaksArr, order.asc)
for i = 0 to array.size(lineBreaksArr) - 2
int leftEdge = array.get(lineBreaksArr, i)
int rightEdge = array.get(lineBreaksArr, i + 1)
reInterpSubrange(linesArr, leftEdge, rightEdge)
// getMaxDistanceIndex(...):
// Return the index (bar) that is farthest from the current “linesArr.”
// We skip any indices already in `lineBreaksArr`.
getMaxDistanceIndex(linesArr, closeArr, lineBreaksArr) =>
float maxDist = -1.0
int maxIdx = -1
int sizeData = array.size(linesArr)
for i = 1 to sizeData - 2
bool isBreak = false
for b = 0 to array.size(lineBreaksArr) - 1
if i == array.get(lineBreaksArr, b)
isBreak := true
break
if not isBreak
float dist = math.abs(array.get(linesArr, i) - array.get(closeArr, i))
if dist > maxDist
maxDist := dist
maxIdx := i
maxIdx
// snapAndReinterpolate(...):
// "Snap" a chosen index to its actual close price, then re-interpolate the entire line again.
snapAndReinterpolate(linesArr, closeArr, lineBreaksArr, idxToSnap) =>
if idxToSnap >= 0
float snapVal = array.get(closeArr, idxToSnap)
array.set(linesArr, idxToSnap, snapVal)
reInterpolateAllSegments(linesArr, lineBreaksArr)
// 3. Global Arrays and Flags
// ---------------------------------------------------------------------
// We store final data globally, then use them outside the barstate.islast scope to draw lines.
var float finalCloseData = array.new_float()
var float finalLines = array.new_float()
var int finalLineBreaks = array.new_int()
var bool didCompute = false
var line pipLines = array.new_line()
// 4. Main Logic (Runs Once at the End of the Current Bar)
// ---------------------------------------------------------------------
if barstate.islast
// A) Prepare closeData in forward order (index 0 = oldest bar, index length-1 = newest)
float closeData = array.new_float()
for i = 0 to length - 1
array.push(closeData, close )
// B) Initialize linesArr with a simple linear interpolation from the first to the last point
float linesArr = array.new_float()
float firstClose = array.get(closeData, 0)
float lastClose = array.get(closeData, length - 1)
for i = 0 to length - 1
float ratio = (length > 1) ? (i / float(length - 1)) : 0.0
float val = firstClose + (lastClose - firstClose) * ratio
array.push(linesArr, val)
// C) Initialize lineBreaks with two anchors: 0 (oldest) and length-1 (newest)
int lineBreaks = array.new_int()
array.push(lineBreaks, 0)
array.push(lineBreaks, length - 1)
// D) Iteratively insert new breakpoints, always re-interpolating globally
int iterationsNeeded = math.max(num_points - 2, 0)
for _iteration = 1 to iterationsNeeded
// 1) Re-interpolate entire shape, so it's globally up to date
reInterpolateAllSegments(linesArr, lineBreaks)
// 2) Find the bar with the largest vertical distance to this line
int maxDistIdx = getMaxDistanceIndex(linesArr, closeData, lineBreaks)
if maxDistIdx == -1
break
// 3) Insert that bar index into lineBreaks and snap it
array.push(lineBreaks, maxDistIdx)
array.sort(lineBreaks, order.asc)
snapAndReinterpolate(linesArr, closeData, lineBreaks, maxDistIdx)
// E) Save results into global arrays for line drawing outside barstate.islast
array.clear(finalCloseData)
array.clear(finalLines)
array.clear(finalLineBreaks)
for i = 0 to array.size(closeData) - 1
array.push(finalCloseData, array.get(closeData, i))
array.push(finalLines, array.get(linesArr, i))
for b = 0 to array.size(lineBreaks) - 1
array.push(finalLineBreaks, array.get(lineBreaks, b))
didCompute := true
// 5. Drawing the Lines in Global Scope
// ---------------------------------------------------------------------
// We cannot create lines inside barstate.islast, so we do it outside.
array.clear(pipLines)
if didCompute
// Connect each pair of anchors with red lines
if array.size(finalLineBreaks) > 1
for i = 0 to array.size(finalLineBreaks) - 2
int idxLeft = array.get(finalLineBreaks, i)
int idxRight = array.get(finalLineBreaks, i + 1)
float x1 = bar_index - (length - 1) + idxLeft
float x2 = bar_index - (length - 1) + idxRight
float y1 = array.get(finalCloseData, idxLeft)
float y2 = array.get(finalCloseData, idxRight)
line ln = line.new(x1, y1, x2, y2, extend=extend.none)
line.set_color(ln, color.red)
line.set_width(ln, 2)
array.push(pipLines, ln)
1. **Data Collection**
- We collect the **most recent** `length` bars in `closeData`. Index 0 is the oldest bar in that window, index `length-1` is the newest bar.
2. **Initial Straight Line**
- We create an array called `linesArr` that starts as a simple linear interpolation from `closeData ` (the oldest bar’s close) to `closeData ` (the newest bar’s close).
3. **Line Breaks**
- We store “anchor points” in `lineBreaks`, initially ` `. These are the start and end of our segment.
4. **Global Re-Interpolation**
- Each time we want to add a new anchor, we **re-draw** (linear interpolation) for *every* subrange ` [lineBreaks , lineBreaks ]`, ensuring we have a globally consistent line.
- This avoids the “local subrange only” approach, which can cause clustering near existing anchors.
5. **Finding the Largest Distance**
- After re-drawing, we compute the vertical distance for each bar `i` that isn’t already a line break. The bar with the biggest distance from the line is chosen as the next anchor (`maxDistIdx`).
6. **Snapping and Re-Interpolate**
- We “snap” that bar’s line value to the actual close, i.e. `linesArr = closeData `. Then we globally re-draw all segments again.
7. **Repeat**
- We repeat these insertions until we have the desired number of points (`num_points`).
8. **Drawing**
- Finally, we connect each consecutive pair of anchor points (`lineBreaks`) with a `line.new(...)` call, coloring them red.
- We offset the line’s `x` coordinate so that the anchor at index 0 lines up with `bar_index - (length - 1)`, and the anchor at index `length-1` lines up with `bar_index` (the current bar).
**Result**:
You get a simplified representation of the price with a small set of line segments capturing the largest “jumps” or swings. By re-drawing the entire line after each insertion, the anchors tend to distribute more *evenly* across the data, mitigating the issue where anchors bunch up near each other.
Enjoy experimenting with different `length` and `num_points` to see how the simplified lines change!
Han Algo - Moving average strategyHan Algo Indicator Strategy Description
Overview:
The Han Algo Indicator is designed to identify trend directions and signal potential buy and sell opportunities based on moving average crossovers. It aims to provide clear signals while filtering out noise and minimizing false signals.
Indicators Used:
Moving Averages:
200 SMA (Simple Moving Average): Used as a long-term trend indicator.
100 SMA: Provides a medium-term perspective on price movements.
50 SMA: Offers insights into shorter-term trends.
20 SMA: Provides a very short-term perspective on recent price actions.
Trend Identification:
The indicator identifies the trend based on the relationship between the closing price (close) and the 200 SMA (ma_long):
Uptrend: When the closing price is above the 200 SMA.
Downtrend: When the closing price is below the 200 SMA.
Sideways: When the closing price is equal to the 200 SMA.
Buy and Sell Signals:
Buy Signal: Generated when transitioning from a downtrend to an uptrend (buy_condition):
Displayed as a green "BUY" label above the price bar.
Sell Signal: Generated when transitioning from an uptrend to a downtrend (sell_condition):
Displayed as a red "SELL" label below the price bar.
Signal Filtering:
Signals are filtered to prevent consecutive signals occurring too closely (min_distance_bars parameter):
Ensures that only significant trend reversals are captured, minimizing false signals.
Visualization:
Background Color:
Changes to green for uptrend and red for downtrend (bgcolor function):
Provides visual cues for current market sentiment.
Usage:
Traders can customize the indicator's parameters (long_term_length, medium_term_length, short_term_length, very_short_term_length, min_distance_bars) to align with their trading preferences and timeframes.
The Han Algo Indicator helps traders make informed decisions by highlighting potential trend reversals and aligning with market trends identified through moving average analysis.
Disclaimer:
This indicator is intended for educational purposes and as a visual aid to support trading decisions. It should be used in conjunction with other technical analysis tools and risk management strategies.

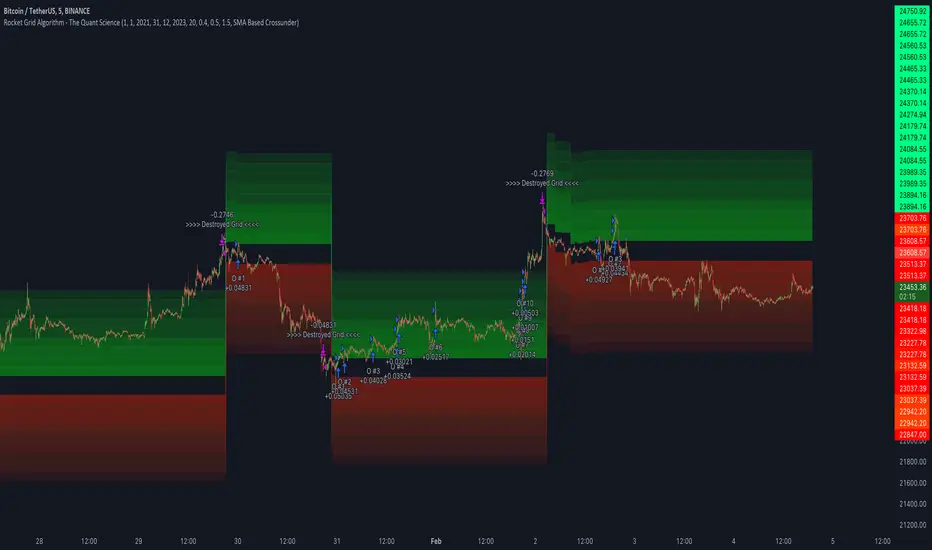
Rocket Grid Algorithm - The Quant ScienceThe Rocket Grid Algorithm is a trading strategy that enables traders to engage in both long and short selling strategies. The script allows traders to backtest their strategies with a date range of their choice, in addition to selecting the desired strategy - either SMA Based Crossunder or SMA Based Crossover.
The script is a combination of trend following and short-term mean reversing strategies. Trend following involves identifying the current market trend and riding it for as long as possible until it changes direction. This type of strategy can be used over a medium- to long-term time horizon, typically several months to a few years.
Short-term mean reversing, on the other hand, involves taking advantage of short-term price movements that deviate from the average price. This type of strategy is usually applied over a much shorter time horizon, such as a few days to a few weeks. By rapidly entering and exiting positions, the strategy seeks to capture small, quick gains in volatile market conditions.
Overall, the script blends the best of both worlds by combining the long-term stability of trend following with the quick gains of short-term mean reversing, allowing traders to potentially benefit from both short-term and long-term market trends.
Traders can configure the start and end dates, months, and years, and choose the length of the data they want to work with. Additionally, they can set the percentage grid and the upper and lower destroyers to manage their trades effectively. The script also calculates the Simple Moving Average of the chosen data length and plots it on the chart.
The trigger for entering a trade is defined as a crossunder or crossover of the close price with the Simple Moving Average. Once the trigger is activated, the script calculates the total percentage of the side and creates a grid range. The grid range is then divided into ten equal parts, with each part representing a unique grid level. The script keeps track of each grid level, and once the close price reaches the grid level, it opens a trade in the specified direction.
The equity management strategy in the script involves a dynamic allocation of equity to each trade. The first order placed uses 10% of the available equity, while each subsequent order uses 1% less of the available equity. This results in the allocation of 9% for the second order, 8% for the third order, and so on, until a maximum of 10 open trades. This approach allows for risk management and can help to limit potential losses.
Overall, the Rocket Grid Algorithm is a flexible and powerful trading strategy that can be customized to meet the specific needs of individual traders. Its user-friendly interface and robust backtesting capabilities make it an excellent tool for traders looking to enhance their trading experience.
tvbot Trend Following with Mean Reversion algoDefault settings are for the ETHUSDT 5 min Binance Chart regular candles.
Back test Default settings are 10,000 usd to start, Commission 0.075%, capital deployment per position is 10%, slippage value of 1.
This algo uses the EMA to set the trend line . You are also able to turn the trend line into a range instead of just a static line. The algo uses the VWMA to set the base entry parameters. When a candle closes above or below the VWMA it will record that price and then wait for the VWMA to meet the candle close price. When that happens the Base entry condition is met. (it causes the vwma to create a hook like structure. essentially tell you that the momentum has changed directions.)
The algo will always check to see if the trend line has either breached or has been tested and held. If this condition has been met it will then go to the base entry condition to check to see if the momentum has changed.
There is a mean reversion component in this algo as well. When the price has moved away from the mean(set by user) by a certain amount the algo will start to look for a top or bottom. Once that condition has been met it will then use the base entry condition to look for a change in momentum, but the mean reversion base entry condition uses the HMA to check for a change in momentum.
This algo effectively looks like a hamburger. Mean reversion being the tops and bottoms(bun) and the trend following(beef patty)

[Fedra Algotrading LR + TTP Indicator Lite]How it works?
- It calculates the linear regression of the last X candles and define a range based on a linear regression deviation (represented by the 3 parallel lines over the last candle).
-Open trades based on the breakout of the deviation of the linear regression (represented by the yellow triangle).
-Advanced trend filter to not open trades against the trend consist in 2 SMA cross and and a few other conditions, including sptionally super trend (Represented by the red and green background).
-Percentage take profit (represented by the horizontal green line. configurable)
-Percentage stop loss (represented by the horizontal red line. Configurable
-Break even when a trade has already opened and there is a change of trend. Calculated in 1.5% when the price is under the yellow SMA.
Alerts in each case to receive notifications (BUY & SELL, TP BE SL).
Added labels with entry price and PnL of each closed trade to facilitate optimization

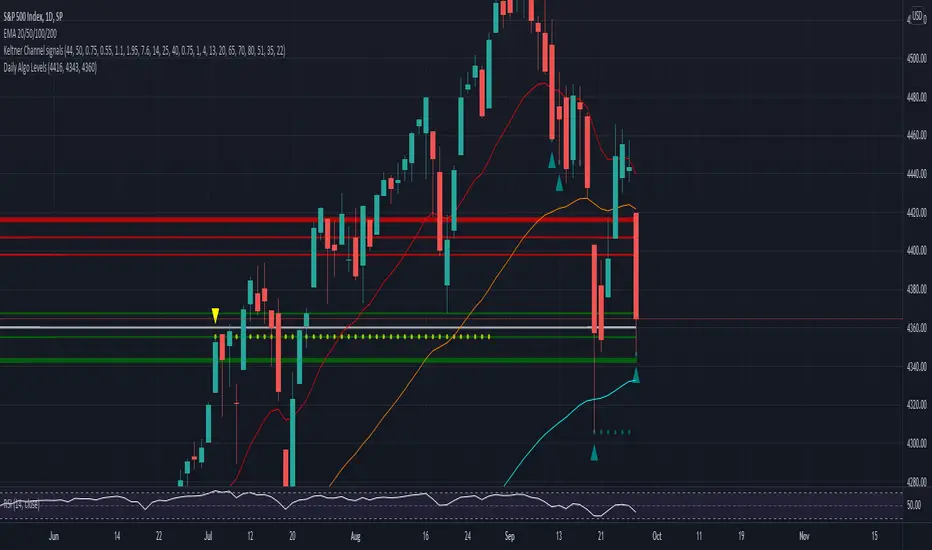
Daily Algo LevelsQuickly plot stoo's algo levels. Gives option to expand range based on algo error formula. Gives option to display suggested entry points.
FUNCTION: Goertzel algorithm -- DFT of a specific frequency binThis function implements the Goertzel algorithm (for integer N).
The Goertzel algorithm is a technique in digital signal processing (DSP) for efficient evaluation of the individual terms of the discrete Fourier transform (DFT).
In short, it measure the power of a specific frequency like one bin of a DFT, over a rolling window (N) of samples.
Here you see an input signal that changes frequency and amplitude (from 7 bars to 17). I am running the indicator 3 times to show it measuring both frequencies and one in between (13). You can see it very accurately measures the signals present and their power, but is noisy in the transition. Changing the block len will cause it to be more responsive but noisier.
Here is a picture of the same signal, but with white noise added.
If you have a cycle you think is present you could use this to test it, but the function is designed for integration in to more complicated scripts. I think power is best interrupted on a log scale.
Given a period (in bars or samples) and a block_len (N in Goertzel terminology) the function returns the Real (InPhase) and Quadrature (Imaginary) components of your signal as well as calculating the power and the instantaneous angle (in radians).
I hope this proves useful to the DSP folks here.

Patient Trendfollower (7)(alpha) Backtesting AlgorithmThis is an alpha version of backtesting algorithm for my Patient Trendfollower (7) strategy. It can help you adapt the indicator to other charts than EURUSD. Please bear in mind that price action, volume profiles and supzistences are a catalyst for successful trading, not an indicator. You can get significantly better results if you use these things in your trading and use Trendfollower only as a secondary tool.
Patient Trendfollower Indicator
Thanks belongs to @everget and Satik FX, their contributions are highlighted on an indicator page.

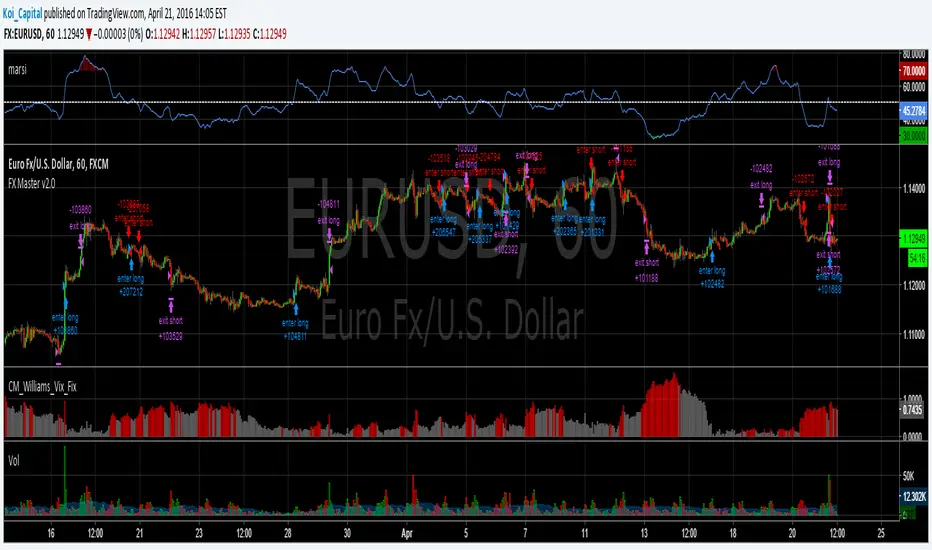
Forex Master v2.0 (EUR/USD)This is version 2 of my Forex Master algorithm originally posted here:
BACKTEST CONDITIONS:
Initial equity = $100,000 (no leverage)
Order size = 100% of equity
Pyramiding = disabled
TRADING RULES:
Long entry = EMA5(RSI20) cross> 50
Profit limit = 50 pips
Stop loss = 50 pips
Short entry = EMA5(RSI20) cross< 50
Profit limit = 50 pips
Stop loss = 50 pips
Long entry = Short exit
Short entry = long exit
DISCLAIMER: None of my ideas and posts are investment advice. Past performance is not an indication of future results. This strategy was constructed with the benefit of hindsight and its future performance cannot be guaranteed.
RSI Min/Max Tracker - HD AlgoRSI Min/Max Tracker – HD Algo
RSI Min/Max Tracker is a momentum analysis indicator designed to enhance traditional RSI usage by continuously tracking the lowest and highest RSI values reached over the visible chart history. This provides immediate context on whether the current RSI is relatively extended or compressed compared to prior market behavior.
How it works
Calculates the Relative Strength Index (RSI) using a user-defined length and price source.
Dynamically records the minimum and maximum RSI values observed since the indicator started.
Updates these extremes in real time as new bars form.
Visual elements
RSI Line (Blue): The current RSI value.
Lowest RSI (Red): The historical minimum RSI reached.
Highest RSI (Green): The historical maximum RSI reached.
Reference Levels:
70 – Overbought (dashed red)
50 – Midline (dotted gray)
30 – Oversold (dashed green)
Info Table
A compact table in the top-right corner displays:
Current RSI
Lowest recorded RSI
Highest recorded RSI
Use cases
Identify whether RSI is near historical extremes.
Improve overbought/oversold context beyond fixed 30/70 levels.
Support mean-reversion, momentum, and divergence-based strategies.
Best used for
Intraday and swing traders who want a clearer perspective on RSI behavior relative to recent market conditions, rather than relying solely on static thresholds.

My Swift-like Algo ALIMOJANIDSwift Algo Chart is a trend-following trading indicator designed to provide clear bias, precise entries, and visual risk management.
It combines EMA trend direction, pullback-based signals, market structure (HH/HL/LH/LL), and ATR-based Stop Loss & Take Profit levels to help traders make disciplined decisions.
🔑 Key Features
Trend Regime Detection
Identifies LONG, SHORT, or NO TRADE conditions using Fast & Slow EMAs.
Pullback Entry Signals
Signals appear only in the direction of the active trend, with optional RSI confirmation.
ATR-Based Risk Levels
Automatically plots SL, TP1, and TP2, including exact price values on the chart.
Preview Levels
Shows projected SL/TP levels when a trend is active, even before an entry.
Market Structure Visualization
Marks HH / HL / LH / LL, draws structure lines, and highlights BOS and CHOCH.
Clean & Non-Repainting Logic
Uses confirmed pivots and closed candles for stability.
Strategy-Compatible
Can be used for discretionary trading or full strategy backtesting.
🧠 Best Used For
Crypto, Forex, Indices
15m to 4H timeframes
Traders who want structure + trend + risk clarity in one tool

My Swiftlike Algo Backtest ATR SL/TP HH/HL/LH/LL BOS/CHOCHSwift-Like Algo is a trend-following strategy that trades pullbacks using EMA trend direction, market structure (HH/HL/LH/LL), and ATR-based risk management.
It enters only in the direction of the trend, with automatic Stop-Loss, TP1, and TP2, and supports full strategy backtesting.
Best used on 15m–4H timeframes for crypto, forex, and indices.
⚠️ For educational and testing purposes only.

Swift-like Algo (V1) Trend Pullback ATR Risk AlimojanidThis indicator is a simple, rule-based trend-following system designed to help identify potential LONG and SHORT opportunities using market structure, momentum, and volatility.
It is inspired by professional “algo-style” tools, but built from scratch for learning, transparency, and flexibility.
🔹 How it works
1️⃣ Trend Detection
Uses Fast EMA vs Slow EMA
Only looks for:
LONGs in bullish trends
SHORTs in bearish trends
2️⃣ Entry Logic
Waits for a pullback toward the fast EMA
Confirms direction using price behavior
Optional RSI filter to avoid weak momentum trades
3️⃣ Risk Management
Stop Loss (SL) and Take Profit (TP) levels are calculated using ATR
Risk is defined in R-multiples (TP1, TP2)
Designed to adapt to market volatility
4️⃣ Visual & Alerts
Clear LONG / SHORT arrows
Automatic SL / TP level plotting
Built-in alert conditions for trade notifications
⚙️ Settings You Can Adjust
EMA lengths (trend sensitivity)
RSI confirmation (on/off)
ATR stop size
Risk-reward targets
Cooldown bars to avoid over-trading
⚠️ Disclaimer
This indicator is NOT a guaranteed trading system and should not be used as financial advice.
Always:
Backtest on your own market and timeframe
Use proper risk management
Paper trade before using real funds
The author is not responsible for any trading losses.
💡 Notes
Best used on trending markets
Works on Forex, Crypto, Indices, and Commodities
Timeframes: 15m and higher recommended

Friendly IT Algo System_2026Friendly IT Algo System V1 is a comprehensive trend-following system that combines SMC (Smart Money Concepts) order blocks with powerful volume filters.
🧠 Key Features:
Smart Trend Signals: EMA 7/20 crossover filtered by market energy.
SMC Order Blocks: Automated key supply/demand zones.
Regular Divergence: RSI-based trend reversal tracking.
Auto Fib & Pivot: Displays 0.618 golden level and pivot S/R.
Sideways Filter: ADX-based gray background to avoid choppy markets.

Institutional Zone Detector [Scalping-Algo]█ OVERVIEW
The Institutional Zone Detector identifies key supply and demand zones where large market participants (institutions, banks, hedge funds) have likely placed significant orders. These zones often act as powerful support and resistance levels, making them strategic areas for trade entries and exits.
This indicator is non-repainting, meaning once a signal appears on your chart, it will never disappear or change position. What you see in backtesting is exactly what you would have seen in real-time.
█ CORE CONCEPT
Markets move when large players execute substantial orders. These orders leave footprints in the form of specific candlestick patterns:
Demand Zones (Bullish)
When institutions accumulate positions, we often see a bearish candle followed by a strong bullish sequence. The last bearish candle before this move marks the demand zone - an area where buying pressure overwhelmed sellers.
Supply Zones (Bearish)
When institutions distribute positions, we typically see a bullish candle followed by a strong bearish sequence. The last bullish candle before this move marks the supply zone - an area where selling pressure overwhelmed buyers.
Price has a tendency to revisit these zones, offering potential trade opportunities.
█ HOW IT WORKS
The indicator scans for:
1. A potential zone candle (bearish for demand, bullish for supply)
2. A sequence of consecutive candles in the opposite direction
3. Optional: A minimum percentage move to filter weak signals
When all conditions are met, the zone is marked on your chart with:
• Upper and lower boundaries (solid lines)
• Equilibrium/midpoint level (cross marker)
• Extended channel lines for easy visualization
█ SETTINGS
Consecutive Candles Required (Default: 5)
Number of same-direction candles needed after the zone candle to confirm the pattern. Higher values = fewer but stronger signals.
Minimum Move Threshold % (Default: 0.0)
Minimum percentage price movement required to validate a zone. Increase this to filter out weak moves and focus on significant institutional activity.
Display Full Candle Range (Default: Off)
• Off: Shows Open-to-Low for demand zones, Open-to-High for supply zones
• On: Shows complete High-to-Low range of the zone candle
Show Demand/Supply Zone Channel (Default: On)
Toggle extended horizontal lines that project the zone levels across your chart.
Visual Theme (Default: Dark)
Choose between Dark (white/blue) or Light (green/red) color schemes.
Show Statistics Panel (Default: Off)
Displays a floating panel with exact price levels of the most recent zones.
Display Info Tooltip (Default: Off)
Shows an information label with indicator documentation.
█ HOW TO USE
Entry Strategies
1. Zone Bounce (Mean Reversion)
• Wait for price to return to a previously identified zone
• Look for rejection candles (pin bars, engulfing patterns) at zone levels
• Enter in the direction of the original zone (long at demand, short at supply)
• Place stops beyond the zone boundary
2. Zone Break (Momentum)
• When price breaks through a zone with strong momentum
• The broken zone often becomes the opposite type (broken demand becomes supply)
• Use for trend continuation trades
3. Equilibrium Trades
• The midpoint (cross marker) often acts as a magnet for price
• Can be used as a first target or as an entry point for scaled positions
Risk Management
• Always place stop-loss orders beyond zone boundaries
• Consider the zone width when calculating position size
• Wider zones = wider stops = smaller position size
• Use the equilibrium level for partial profit taking
Best Practices
• Higher timeframes produce more reliable zones
• Zones on multiple timeframes (confluence) are stronger
• Fresh/untested zones are more powerful than zones that have been touched multiple times
• Combine with other analysis methods (trend direction, volume, market structure)
█ ALERTS
Two alert conditions are available:
• "Demand Zone Identified" - Triggers when a new demand zone is detected
• "Supply Zone Identified" - Triggers when a new supply zone is detected
To set up alerts: Click on the indicator name → Add Alert → Select condition
█ IMPORTANT NOTES
• This indicator is a tool for analysis, not a complete trading system
• Signals are NOT automatic buy/sell recommendations
• Always use proper risk management
• Past performance does not guarantee future results
• Works on all markets and timeframes
• Non-repainting: Signals appear only after bar close confirmation
█ ACKNOWLEDGMENTS
Inspired by institutional order flow concepts and smart money trading methodologies. Built with a focus on reliability and practical application.

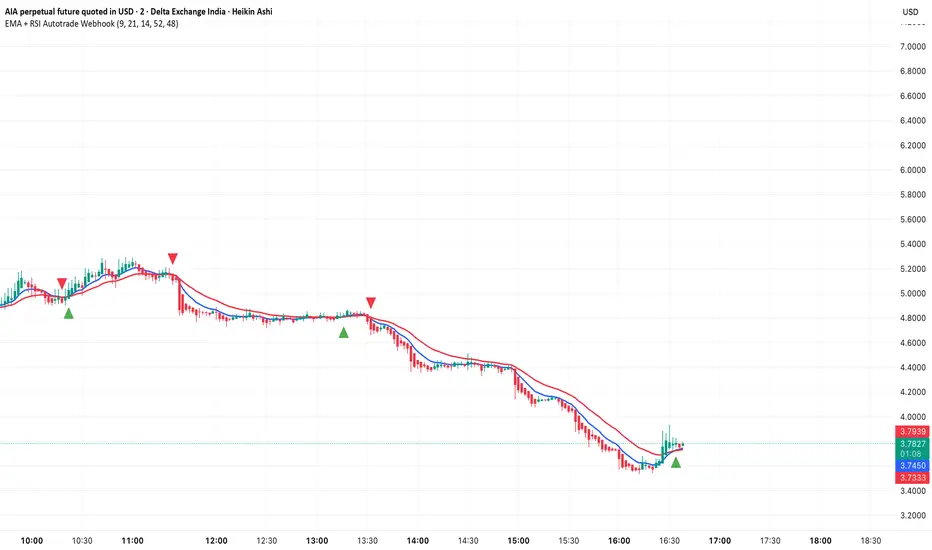
EMA + RSI Autotrade Webhook - VarunOverview
The EMA + RSI Autotrade Webhook is a powerful trend-following indicator designed for automated crypto futures trading. This indicator combines the reliability of Exponential Moving Average (EMA) crossovers with RSI momentum filtering to generate high-probability buy and sell signals optimized for webhook integration with crypto exchanges like Delta Exchange, Binance Futures, and Bybit.Key Features
Simple & Effective: Uses proven EMA 9/21 crossover strategy
RSI Momentum Filter: Eliminates low-probability trades in ranging markets
Webhook Ready: Two clean alerts (LONG Entry, SHORT Entry) for seamless automation
Exchange Compatible: Works with Delta Exchange, 3Commas, Alertatron, and other webhook platforms
Zero Lag Signals: Real-time alerts on crossover confirmation
Visual Clarity: Clean chart markers for easy signal identification
How It Works
Entry Signals:
LONG Entry: Triggers when EMA 9 crosses above EMA 21 AND RSI is above 52 (bullish momentum confirmed)
SHORT Entry: Triggers when EMA 9 crosses under EMA 21 AND RSI is below 48 (bearish momentum confirmed)
Technical Components:
Fast EMA: 9-period (tracks short-term price action)
Slow EMA: 21-period (identifies primary trend)
RSI: 14-period (confirms momentum strength)
RSI Long Threshold: 52 (filters weak bullish signals)
RSI Short Threshold: 48 (filters weak bearish signals)
Best Use Cases
Crypto Futures Trading: Bitcoin, Ethereum, Altcoin perpetual contracts
Automated Trading Bots: Integration with Delta Exchange webhooks, TradingView alerts
Timeframes: Optimized for 15-minute charts (works on 5min-1H)
Markets: Trending crypto markets with clear directional moves
Risk Management: Best used with 1-2% stop loss per trade (managed externally)
Webhook Automation Setup
Add indicator to your TradingView chart
Create alerts for "LONG Entry" and "SHORT Entry"
Configure webhook URL from your exchange (Delta Exchange, Binance, etc.)
Use alert message: Entry LONG {{ticker}} @ {{close}} or Entry SHORT {{ticker}} @ {{close}}
Exchange automatically reverses positions on opposite signals
Advantages
✅ No manual trading required - fully automated
✅ Eliminates emotional trading decisions
✅ Catches trending moves early with EMA crossovers
✅ RSI filter reduces whipsaws in choppy markets
✅ Works 24/7 without monitoring
✅ Simple two-alert system (easy to manage)
✅ Compatible with multiple exchanges via webhooksStrategy Philosophy
This indicator follows a trend-following with momentum confirmation approach. By waiting for both EMA crossover AND RSI confirmation, it ensures you're entering trades with genuine momentum behind them, not just random price noise. The tight RSI thresholds (52/48) keep you aligned with the prevailing trend.Recommended Settings
Timeframe: 15-minute (primary), 5-minute (scalping), 1-hour (swing)
Markets: BTC/USDT, ETH/USDT, high-liquidity altcoin perpetuals
Position Sizing: 100% capital per signal (exchange manages reversals)
Stop Loss: 2% (managed via exchange or external bot)
Leverage: 1-2x for conservative approach, up to 5x for aggressive
Important Notes
⚠️ This indicator generates entry signals only - position reversals are handled automatically by your exchange
⚠️ Always backtest on historical data before live trading
⚠️ Use proper risk management and position sizing
⚠️ Best performance in trending markets; may generate false signals in tight ranges
⚠️ Requires TradingView Premium or higher for webhook functionalityTags
cryptocurrency futures automated-trading ema-crossover rsi webhook delta-exchange tradingview-alerts trend-following momentum bitcoin ethereum crypto-bot algo-trading 15-minute-strategy
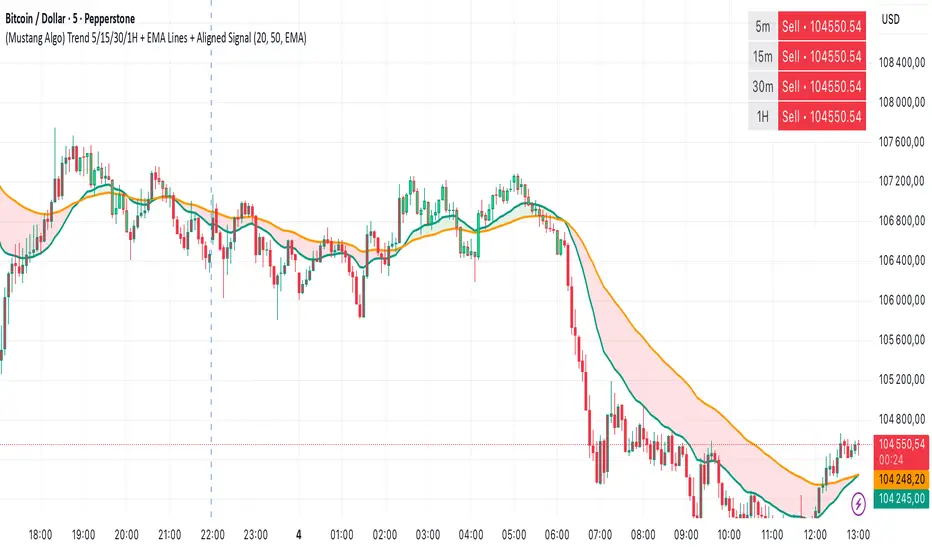
(Mustang Algo) Trend 5/15/30/1H + EMA Lines + Aligned Signal═══════════════════════════════════════════════════════════
MUSTANG ALGO - MULTI-TIMEFRAME TREND ALIGNMENT
═══════════════════════════════════════════════════════════
📊 OVERVIEW:
This indicator analyzes trend alignment across four key timeframes (5m, 15m, 30m, 1H) using customizable moving averages. It helps traders identify high-probability setups when multiple timeframes confirm the same trend direction.
🎯 KEY FEATURES:
✓ Multi-Timeframe Analysis (5m/15m/30m/1H)
- Monitors trend direction on 4 different timeframes simultaneously
- Visual table showing real-time trend status for each period
- Optional price display for each timeframe
✓ Flexible Moving Average System
- Choose from 5 MA types: EMA, SMA, SMMA (RMA), WMA, VWMA
- Customizable Fast MA (default: 20) and Slow MA (default: 50)
- Visual cloud between moving averages (green=bullish, red=bearish)
✓ Alignment Signals
- "4x UP" triangle: All 4 timeframes bullish (strong uptrend)
- "4x DOWN" triangle: All 4 timeframes bearish (strong downtrend)
- Signals appear only when ALL timeframes agree
✓ Visual Enhancements
- MA cloud with transparency for better chart readability
- Optional candle coloring based on local trend
- Clean, customizable dashboard display
✓ Alert System
- Built-in alerts for bullish alignment (4 TF aligned up)
- Built-in alerts for bearish alignment (4 TF aligned down)
- Perfect for automated trading setups
📈 HOW TO USE:
1. **Trend Confirmation**: Wait for alignment signals (triangles) before entering trades
2. **Dashboard Monitoring**: Check the top-right table to see individual TF trends
3. **MA Cloud**: Use the cloud as dynamic support/resistance
4. **Entry Timing**: Enter on local timeframe when higher TFs are aligned
⚙️ CUSTOMIZABLE PARAMETERS:
- Fast MA Length (default: 20)
- Slow MA Length (default: 50)
- MA Type (EMA/SMA/SMMA/WMA/VWMA)
- Toggle dashboard display
- Toggle price display in dashboard
- Toggle MA cloud
- Toggle candle coloring
⚠️ BEST PRACTICES:
- Use on 5m or 15m charts for optimal multi-TF analysis
- Combine with price action and volume for best results
- Alignment signals are rare but highly significant
- Not a standalone system - use as confluence tool
💡 STRATEGY IDEAS:
- Scalping: Enter on local TF when all TFs aligned
- Swing Trading: Hold positions while alignment maintained
- Risk Management: Exit if alignment breaks
- Confluence: Combine with support/resistance levels
📌 NOTES:
- Works on all markets (Crypto, Forex, Stocks, Indices)
- Repaints minimally (only on MA calculations)
- Low resource usage, efficient code
═══════════════════════════════════════════════════════════
Created by Mustang Spirit Trading Academy
For educational purposes - Always manage your risk!
═══════════════════════════════════════════════════════════