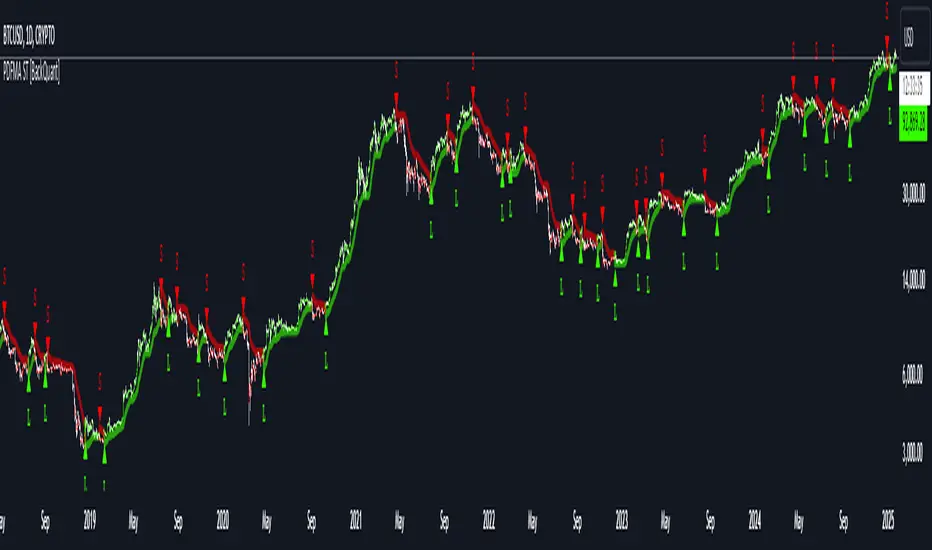
PDF Smoothed Moving Average [BackQuant]PDF Smoothed Moving Average
Introducing BackQuant’s PDF Smoothed Moving Average (PDF-MA) — an innovative trading indicator that applies Probability Density Function (PDF) weighting to moving averages, creating a unique, trend-following tool that offers adaptive smoothing to price movements. This advanced indicator gives traders an edge by blending PDF-weighted values with conventional moving averages, helping to capture trend shifts with enhanced clarity.
Core Concept: Probability Density Function (PDF) Smoothing
The Probability Density Function (PDF) provides a mathematical approach to applying adaptive weighting to data points based on a specified variance and mean. In the PDF-MA indicator, the PDF function is used to weight price data, adding a layer of probabilistic smoothing that enhances the detection of trend strength while reducing noise.
The PDF weights are controlled by two key parameters:
Variance: Determines the spread of the weights, where higher values spread out the weighting effect, providing broader smoothing.
Mean : Centers the weights around a particular price value, influencing the trend’s directionality and sensitivity.
These PDF weights are applied to each price point over the chosen period, creating an adaptive and smooth moving average that more closely reflects the underlying price trend.
Blending PDF with Standard Moving Averages
To further improve the PDF-MA, this indicator combines the PDF-weighted average with a traditional moving average, selected by the user as either an Exponential Moving Average (EMA) or Simple Moving Average (SMA). This blended approach leverages the strengths of each method: the responsiveness of PDF smoothing and the robustness of conventional moving averages.
Smoothing Method: Traders can choose between EMA and SMA for the additional moving average layer. The EMA is more responsive to recent prices, while the SMA provides a consistent average across the selected period.
Smoothing Period: Controls the length of the lookback period, affecting how sensitive the average is to price changes.
The result is a PDF-MA that provides a reliable trend line, reflecting both the PDF weighting and traditional moving average values, ideal for use in trend-following and momentum-based strategies.
Trend Detection and Candle Coloring
The PDF-MA includes a built-in trend detection feature that dynamically colors candles based on the direction of the smoothed moving average:
Uptrend: When the PDF-MA value is increasing, the trend is considered bullish, and candles are colored green, indicating potential buying conditions.
Downtrend: When the PDF-MA value is decreasing, the trend is considered bearish, and candles are colored red, signaling potential selling or shorting conditions.
These color-coded candles provide a quick visual reference for the trend direction, helping traders make real-time decisions based on the current market trend.
Customization and Visualization Options
This indicator offers a range of customization options, allowing traders to tailor it to their specific preferences and trading environment:
Price Source : Choose the price data for calculation, with options like close, open, high, low, or HLC3.
Variance and Mean : Fine-tune the PDF weighting parameters to control the indicator’s sensitivity and responsiveness to price data.
Smoothing Method : Select either EMA or SMA to customize the conventional moving average layer used in conjunction with the PDF.
Smoothing Period : Set the lookback period for the moving average, with a longer period providing more stability and a shorter period offering greater sensitivity.
Candle Coloring : Enable or disable candle coloring based on trend direction, providing additional clarity in identifying bullish and bearish phases.
Trading Applications
The PDF Smoothed Moving Average can be applied across various trading strategies and timeframes:
Trend Following : By smoothing price data with PDF weighting, this indicator helps traders identify long-term trends while filtering out short-term noise.
Reversal Trading : The PDF-MA’s trend coloring feature can help pinpoint potential reversal points by showing shifts in the trend direction, allowing traders to enter or exit positions at optimal moments.
Swing Trading : The PDF-MA provides a clear trend line that swing traders can use to capture intermediate price moves, following the trend direction until it shifts.
Final Thoughts
The PDF Smoothed Moving Average is a highly adaptable indicator that combines probabilistic smoothing with traditional moving averages, providing a nuanced view of market trends. By integrating PDF-based weighting with the flexibility of EMA or SMA smoothing, this indicator offers traders an advanced tool for trend analysis that adapts to changing market conditions with reduced lag and increased accuracy.
Whether you’re trading trends, reversals, or swings, the PDF-MA offers valuable insights into the direction and strength of price movements, making it a versatile addition to any trading strategy.
Komut dosyalarını "长江电子+半导体行业研究框架培训+pdf" için ara
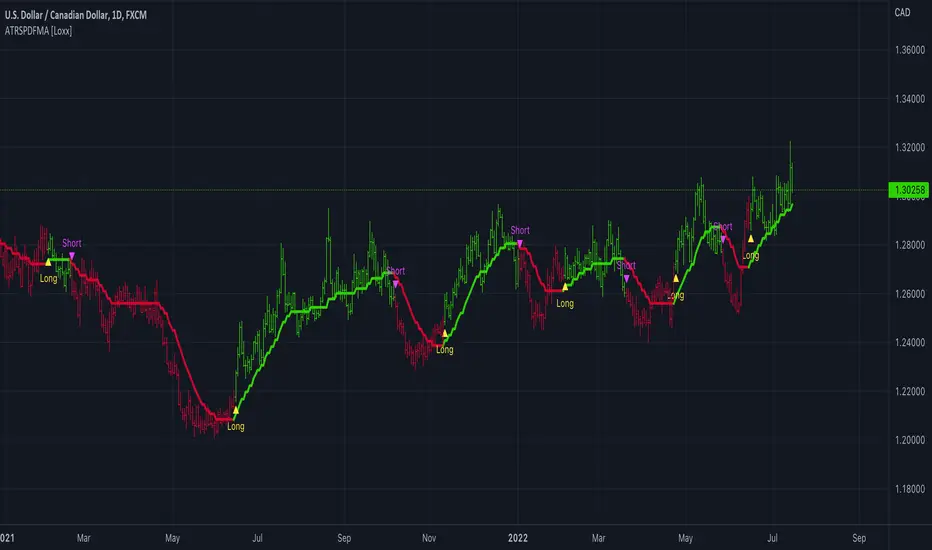
ATR-Stepped PDF MA [Loxx]ATR-Stepped PDF MA is and ATR-stepped moving average that uses a probability density function moving average.
What is Probability Density Function?
Probability density function based MA is a sort of weighted moving average that uses probability density function to calculate the weights.
Included:
-Toggle on/off bar coloring
-Toggle on/off signals
-Alerts long/short
PDF MA For Loop [BackQuant]PDF MA For Loop
Introducing the PDF MA For Loop, an innovative trading indicator that combines Probability Density Function (PDF) smoothing with a dynamic for-loop scoring mechanism. This advanced tool provides traders with precise trend-following signals, helping to identify long and short opportunities with improved clarity and adaptability to market conditions.
If you would like to check out the stand alone PDF Moving Average:
Core Concept: Probability Density Function (PDF) Smoothing
The PDF smoothing method is a unique approach that applies adaptive weights to price data based on a Probability Density Function. This ensures that recent data points receive appropriate emphasis while maintaining a smooth transition across the data set. The result is a moving average that is not only smoother but also more responsive to market changes.
Key parameters in PDF smoothing:
Variance : Controls the spread of the PDF, where a higher value results in broader smoothing and a lower value makes the moving average more sensitive.
Mean : Centers the PDF around a specific value, influencing the weighting and responsiveness of the smoothing process.
By combining PDF smoothing with traditional moving averages (EMA or SMA), the indicator creates a hybrid signal that balances responsiveness and reliability.
For-Loop Scoring Mechanism
At the heart of this indicator is the for-loop scoring mechanism, which evaluates the smoothed PDF moving average over a defined range of historical data points. This process assigns a score to the current market condition based on whether the PDF moving average is greater than or less than previous values.
Long Signal: A long signal is generated when the score exceeds the Long Threshold (default set at 40), indicating upward momentum.
Short Signal: A short signal is triggered when the score crosses below the Short Threshold (default set at -10), suggesting potential downward momentum.
This dynamic scoring system ensures that the indicator remains adaptive, capturing trends and shifts in market sentiment effectively.
Customization Options
The PDF MA For Loop includes a variety of customizable settings to fit different trading styles and strategies:
Calculation Settings
Price Source : Select the input price for the calculation (default is the close price).
Smoothing Method : Choose between EMA or SMA for the additional smoothing layer, providing flexibility to adapt to market conditions.
Smoothing Period : Adjust the lookback period for the smoothing function, with shorter periods providing more sensitivity and longer periods offering greater stability.
Variance & Mean : Fine-tune the PDF function parameters to control the weighting of the smoothing process.
Signal Settings
Thresholds : Customize the upper and lower thresholds to define the sensitivity of the long and short signals.
For Loop Range : Set the range of historical data points analyzed by the for-loop, influencing the depth of the scoring mechanism.
UI Settings
Signal Line Width: Adjust the thickness of the plotted signal line for better visibility.
Candle Coloring: Enable or disable the coloring of candlesticks based on trend direction (green for long, red for short, gray for neutral).
Background Coloring: Add background shading to highlight long and short signals for an enhanced visual experience.
Alerts and Automation
The indicator includes built-in alert conditions to notify traders of important market events:
Long Signal Alert: Notifies when the score exceeds the upper threshold, indicating a bullish trend.
Short Signal Alert: Notifies when the score crosses below the lower threshold, signaling a bearish trend.
These alerts can be configured for real-time notifications, allowing traders to respond quickly to market changes without constant chart monitoring.
Trading Applications
The PDF MA For Loop is versatile and can be applied across various trading strategies and market conditions:
Trend Following: The PDF smoothing method combined with for-loop scoring makes this indicator particularly effective for identifying and following trends.
Reversal Trading: By observing the thresholds and score, traders can anticipate potential reversals when the trend shifts from long to short (or vice versa).
Risk Management: The dynamic thresholds and scoring provide clear signals, allowing traders to enter and exit trades with greater confidence and precision.
Final Thoughts
The PDF MA For Loopis merges advanced mathematical concepts with practical trading tools. By leveraging Probability Density Function smoothing and a dynamic for-loop scoring system, it provides traders with clear, actionable signals while adapting to market conditions.
Whether you’re looking for an edge in trend-following strategies or seeking precision in identifying reversals, this indicator offers the flexibility and power to enhance your trading decisions
As always, backtesting and integrating the PDF MA For Loop into a comprehensive trading strategy is recommended for optimal performance, as no single indicator should be used in isolation.
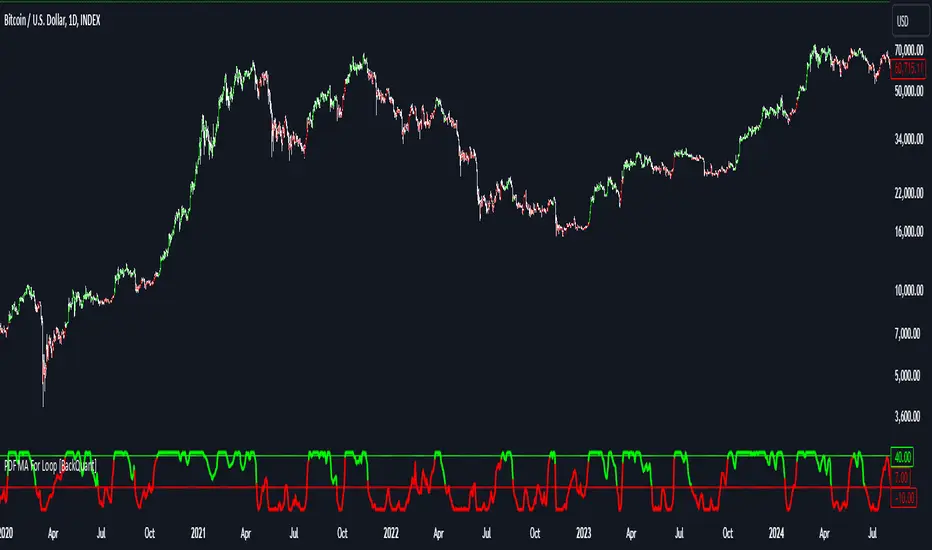
Thus following all of the key points here are some sample backtests on the 1D Chart
Disclaimer: Backtests are based off past results, and are not indicative of the future.
INDEX:BTCUSD
INDEX:ETHUSD
BINANCE:SOLUSD
PDF-MA Supertrend [BackQuant]PDF-MA Supertrend
The PDF-MA Supertrend combines the innovative Probability Density Function (PDF) smoothing with the widely popular Supertrend methodology, creating a robust tool for identifying trends and generating actionable trading signals. This indicator is designed to provide precise entries and exits by dynamically adapting to market volatility while visualizing long and short opportunities directly on the chart.
Core Feature: PDF Smoothing
At the foundation of this indicator is the PDF smoothing technique, which applies a Probability Density Function to calculate a smoothed moving average. This method allows the indicator to assign adaptive weights to data points, making it responsive to market changes without overreacting to short-term volatility.
Key parameters include:
Variance: Controls the spread of the PDF weighting. A smaller variance results in sharper responses, while a larger variance smooths out the curve.
Mean: Shifts the PDF’s center, allowing traders to tweak how weights are distributed around the data points.
Smoothing Method: Offers the choice between EMA (Exponential Moving Average) and SMA (Simple Moving Average) for blending the PDF-smoothed data with traditional moving average methods.
By combining these parameters, the PDF smoothing creates a moving average that effectively captures underlying trends.
Supertrend: Adaptive Trend and Volatility Tracking
The Supertrend is a well-known volatility-based indicator that dynamically adjusts to market conditions using the ATR (Average True Range). In this script, the PDF-smoothed moving average acts as the price input, making the Supertrend calculation more adaptive and precise.
Key Supertrend Features:
ATR Period: Determines the lookback period for calculating market volatility.
Factor: Multiplies the ATR to set the distance between the Supertrend and the price. A higher factor creates wider bands, filtering out smaller price movements, while a lower factor captures tighter trends.
Dynamic Direction: The Supertrend flips its direction based on price interactions with the calculated upper and lower bands:
Uptrend : When the price is above the Supertrend, the direction turns bullish.
Downtrend : When the price is below the Supertrend, the direction turns bearish.
This combination of PDF smoothing and Supertrend calculation ensures that trends are detected with greater accuracy, while volatility filters out market noise.
Long and Short Signal Generation
The PDF-MA Supertrend generates actionable trading signals by detecting transitions in the trend direction:
Long Signal (𝕃): Triggered when the trend transitions from bearish to bullish. This is visually represented with a green triangle below the price bars.
Short Signal (𝕊): Triggered when the trend transitions from bullish to bearish. This is marked with a red triangle above the price bars.
These signals provide traders with clear entry and exit points, ensuring they can capitalize on emerging trends while avoiding false signals.
Customizable Visualization Options
The indicator offers a range of visualization settings to help traders interpret the data with ease:
Show Supertrend: Option to toggle the visibility of the Supertrend line.
Candle Coloring: Automatically colors candlesticks based on the trend direction:
Green for long trends.
Red for short trends.
Long and Short Signals (𝕃 + 𝕊): Displays long (𝕃) and short (𝕊) signals directly on the chart for quick identification of trade opportunities.
Line Color Customization: Allows users to customize the colors for long and short trends.
Alert Conditions
To ensure traders never miss an opportunity, the PDF-MA Supertrend includes built-in alerts for trend changes:
Long Signal Alert: Notifies when a bullish trend is identified.
Short Signal Alert: Notifies when a bearish trend is identified.
These alerts can be configured for real-time notifications via SMS, email, or push notifications, making it easier to stay updated on market movements.
Suggested Parameter Adjustments
The indicator’s effectiveness can be fine-tuned using the following guidelines:
Variance:
For low-volatility assets (e.g., indices): Use a smaller variance (1.0–1.5) for smoother trends.
For high-volatility assets (e.g., cryptocurrencies): Use a larger variance (1.5–2.0) to better capture rapid price changes.
ATR Factor:
A higher factor (e.g., 2.0) is better suited for long-term trend-following strategies.
A lower factor (e.g., 1.5) captures shorter-term trends.
Smoothing Period:
Shorter periods provide more reactive signals but may increase noise.
Longer periods offer stability and better alignment with significant trends.
Experimentation is encouraged to find the optimal settings for specific assets and trading strategies.
Trading Applications
The PDF-MA Supertrend is a versatile indicator suited to a variety of trading approaches:
Trend Following : Use the Supertrend line and signals to follow market trends and ride sustained price movements.
Reversal Trading : Spot potential trend reversals as the Supertrend flips direction.
Volatility Analysis : Adjust the ATR factor to filter out minor price fluctuations or capture sharp movements.
Final Thoughts
The PDF-MA Supertrend combines the precision of Probability Density Function smoothing with the adaptability of the Supertrend methodology, offering traders a powerful tool for identifying trends and volatility. With its customizable parameters, actionable signals, and built-in alerts, this indicator is an excellent choice for traders seeking a robust and reliable system for trend detection and entry/exit timing.
As always, backtesting and incorporating this indicator into a broader strategy are recommended for optimal results.
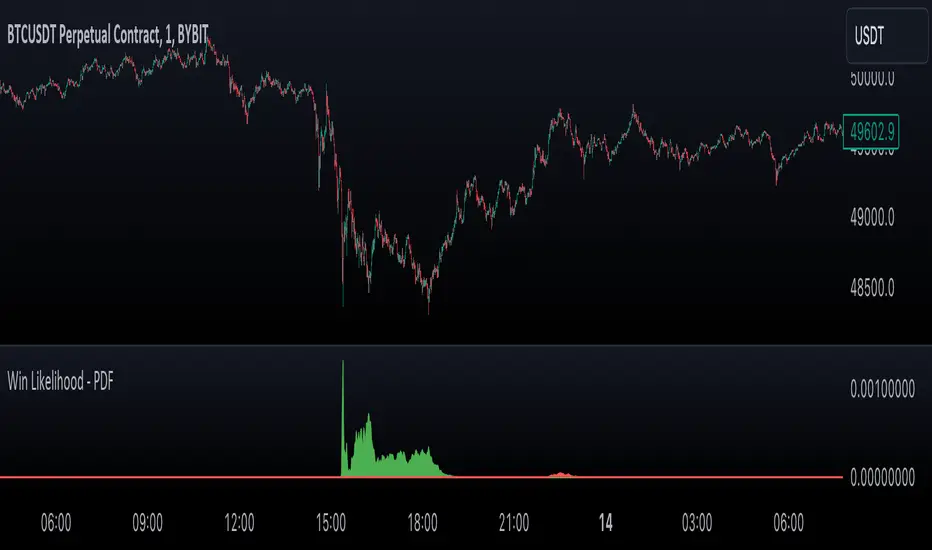
Likelihood of Winning - Probability Density FunctionIn developing the "Likelihood of Winning - Probability Density Function (PDF)" indicator, my aim was to offer traders a statistical tool to quantify the probability of reaching target prices. This indicator, grounded in risk assessment principles, enables users to analyze potential outcomes based on the normal distribution, providing insights into market dynamics.
The tool's flexibility allows for customization of the data series, lookback periods, and target settings for both long and short scenarios. It features a color-coded visualization to easily distinguish between probabilities of hitting specified targets, enhancing decision-making in trading strategies.
I'm excited to share this indicator with the trading community, hoping it will enhance data-driven decision-making and offer a deeper understanding of market risks and opportunities. My goal is to continuously improve this tool based on user feedback and market evolution, contributing to more informed trading practices.
This indicator leverages the "NormalDistributionFunctions" library, enabling easy integration into other indicators or strategies. Users can readily embed advanced statistical analysis into their trading tools, fostering innovation within the Pine Script community.
Stress DashboardEnglish:
The Stress Dashboard is based on the Kansas City Financial Stress Index. In most general terms, financial stress can be thought of as an interruption to the normal functioning of financial markets.
For more information about the Stress index read the pdf from kansascityfed.org:
www.kansascityfed.org
If the value is above 0 it indicates that financial stress is above the long-run average, while a value below 0 signifies that financial stress is below the long-run average.
You can use it as a early warning system to bigger down moves or possible crashes and left the market early.
I use it in combine with my Volatility Dashboard as my own early warning system because the Stess Index only get updated monthly so that the Volatility Dashboard warning me much faster.
I dont want to have only one crash indicator so I search for another and found these. If you transfer the red areas of the indicator into the S&P 500 Chart then you can see how good these Dashboard warning you for a following crash/ downtrend/ bigger correction.
Deutsch:
Das Stress Dashboard basiert auf dem Kansas City Financial Stress Index. Finanzielle Belastungen können im Allgemeinen als Unterbrechung des normalen Funktionierens der Finanzmärkte angesehen werden.
Weitere Informationen zum Stress-Index finden Sie im PDF von kansascityfed.org:
www.kansascityfed.org
Wenn der Wert über 0 liegt bedeutet dies, dass die finanzielle Belastung über dem langfristigen Durchschnitt liegt, während ein Wert unter 0 bedeutet, dass die finanzielle Belastung unter dem langfristigen Durchschnitt liegt.
Sie können es als Frühwarnsystem für größere Abwärtsbewegungen oder mögliche Abstürze verwenden und den Markt frühzeitig verlassen.
Ich verwende es in Kombination mit meinem Volatility Dashboard als mein eigenes Frühwarnsystem, da der Stess-Index nur monatlich aktualisiert wird, sodass mich das Volatility Dashboard viel schneller warnt.
Ich möchte nicht nur einen Crash Indikator haben, also suchte ich nach einer weiteren und fand diesen. Wenn Sie die roten Bereiche des Indikators in den S&P 500 Chart übertragen, können Sie sehen wie gut dieses Dashboard Sie vor einem folgenden Absturz / Abwärtstrend / einer größeren Korrektur warnt.

CauchyTrend [InvestorUnknown]The CauchyTrend is an experimental tool that leverages a Cauchy-weighted moving average combined with a modified Supertrend calculation. This unique approach provides traders with insight into trend direction, while also offering an optional ATR-based range analysis to understand how often the market closes within, above, or below a defined volatility band.
Core Concepts
Cauchy Distribution and Gamma Parameter
The Cauchy distribution is a probability distribution known for its heavy tails and lack of a defined mean or variance. It is characterized by two parameters: a location parameter (x0, often 0 in our usage) and a scale parameter (γ, "gamma").
Gamma (γ): Determines the "width" or scale of the distribution. Smaller gamma values produce a distribution more concentrated near the center, giving more weight to recent data points, while larger gamma values spread the weight more evenly across the sample.
In this indicator, gamma influences how much emphasis is placed on values closer to the current price versus those further away in time. This makes the resulting weighted average either more reactive or smoother, depending on gamma’s value.
// Cauchy PDF formula used for weighting:
// f(x; γ) = (1/(π*γ)) *
f_cauchyPDF(offset, gamma) =>
numerator = gamma * gamma
denominator = (offset * offset) + (gamma * gamma)
pdf = (1 / (math.pi * gamma)) * (numerator / denominator)
pdf
A chart showing different Cauchy PDFs with various gamma values, illustrating how gamma affects the weight distribution.
Cauchy-Weighted Moving Average (CWMA)
Using the Cauchy PDF, we calculate normalized weights to create a custom Weighted Moving Average. Each bar in the lookback period receives a weight according to the Cauchy PDF. The result is a Cauchy Weighted Average (cwm_avg) that differs from typical moving averages, potentially offering unique sensitivity to price movements.
// Summation of weighted prices using Cauchy distribution weights
cwm_avg = 0.0
for i = 0 to length - 1
w_norm = array.get(weights, i) / sum_w
cwm_avg += array.get(values, i) * w_norm
Supertrend with a Cauchy Twist
The indicator integrates a modified Supertrend calculation using the cwm_avg as its reference point. The Supertrend logic typically sets upper and lower bands based on volatility (ATR), and flips direction when price crosses these bands.
In this case, the Cauchy-based average replaces the usual baseline, aiming to capture trend direction via a different weighting mechanism.
When price closes above the upper band, the trend is considered bullish; closing below the lower band signals a bearish trend.
ATR Stats Range (Optional)
Beyond the fundamental trend detection, the indicator optionally computes ATR-based stats to understand price distribution relative to a volatility corridor centered on the cwm_avg line:
Volatility Range:
Defined as cwm_avg ± (ATR * atr_mult), this range creates upper and lower bands. Turning on atr_stats computes how often the daily close falls: Within the range, Above the upper ATR boundary, Below the lower ATR boundary, Within the range but above cwm_avg, Within the range but below cwm_avg
These statistics can help traders gauge how the market behaves relative to this volatility envelope and possibly identify if the market tends to revert to the mean or break out more often.
Backtesting and Performance Metrics
The code is integrated with a backtesting library that allows users to assess strategy performance historically:
Equity Curve Calculation: Compares CauchyTrend-based signals against the underlying asset.
Performance Metrics Table: Once enabled, displays key metrics such as mean returns, Sharpe Ratio, Sortino Ratio, and more, comparing the strategy to a simple Buy & Hold approach.
Alerts and Notifications
The indicator provides Alerts for key events:
Long Alert: Triggered when the trend flips bullish.
Short Alert: Triggered when the trend flips bearish.
Customization and Calibration
Important: The default parameters are not optimized for any specific instrument or time frame. Traders should:
Adjust the length and gamma parameters to influence how sharply or broadly the cwm_avg reacts to price changes.
Tune the atr_len and atr_mult for the Supertrend logic to better match the asset’s volatility characteristics.
Experiment with atr_stats on/off to see if that additional volatility distribution information provides helpful insights.
Traders may find certain sets of parameters that align better with their preferred trading style, risk tolerance, or asset volatility profile.
Disclaimer: This indicator is for educational and informational purposes only. Past performance in backtesting does not guarantee future results. Always perform due diligence, and consider consulting a qualified financial advisor before trading.

CM Stochastic POP Method 2-Jake Bernstein_V1Yesterday Jake Bernstein authorized me to post his updated results with the Stochastic Pop Trading System he developed many years ago.
You can take a look at the Original System with Updated Settings at
This indicator is a different set of rules Jake mentioned in the PDF he allowed me to post.
To view the PDF use this link:
dl.dropboxusercontent.com
Today we’re releasing the version described in the PDF that uses the StochK values of 55, 50, and 45. The rules are discussed in the PDF but here is a simple breakdown:
Enter Long when StochK is below 50 and Crosses Above 55
Exit Long on Cross Below 55
Enter Short when StochK is Above 50 and crosses Below 45
Exit Short on Cross Above 45
Two Important Items to understand about this method:
To code the rules Precisely we need a function that will be available when Strategy Capabilities are released on TradingView.
There is one of Jakes Profit Maximizing Strategies that needs to be integrated with this code…which again we need the Strategy based Function that will be coming soon.
To Compare this system to the Stochastic Pop Method 1 System shown yesterday at I used the same Symbol and dates for you to compare…but remember to give this Method 2 System a Fair Look/Evaluation…we need the Soon To Be Released…TradingView Strategy Capabilities.
BackTesting Results Example: EUR-USD Daily Chart Since 01/01/2005
Strategy 1 – Stochastic Pop Method 2 System:
Go Long When Stochasticis below 50 and Crosses Above 55. Go Short When Stochastic is above 50 and Crosses Below 45. Exit Long/Short When Stochastic has a Reverse Cross of Entry Value.
Results:
Total Trades = 151
Profit = 40,758 Pips
Win% = 37.1%
Profit Factor = 1.26
Avg Trade = 270 Pips Profit
***Most Consecutive Wins = 4 ... Most Consecutive Losses = 7
Strategy 2:
Rules - Proprietary Optimization Jake Will Teach. Only Added 1 Additional Exit Rule.
Results:
Total Trades = 151
Profit = 60.305 Pips
Win% = 37.1%
Profit Factor = 1.38
Avg Trade = 399 Pips Profit
***Most Consecutive Wins = 4 ... Most Consecutive Losses = 7
Indicator Includes:
-Ability to Color Candles (CheckBox In Inputs Tab)
Green = Long Trade
Blue = No Trade
Red = Short Trade
Jake Bernstein will be a contributor on TradingView when Backtesting/Strategies are released. Jake is one of the Top Trading System Developers in the world with 45+ years experience and he is going to teach TradingView.com’s community how to create Trading Systems and how to Optimize the correct way.
Link To PDF:
dl.dropboxusercontent.com
Link to Original Version of Indicator with Updated Settings.

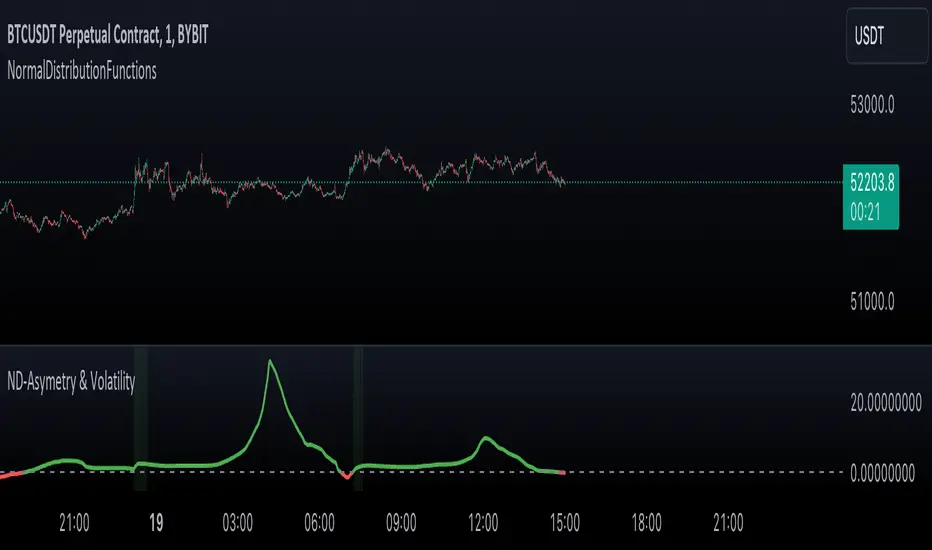
NormalDistributionFunctionsLibrary "NormalDistributionFunctions"
The NormalDistributionFunctions library encompasses a comprehensive suite of statistical tools for financial market analysis. It provides functions to calculate essential statistical measures such as mean, standard deviation, skewness, and kurtosis, alongside advanced functionalities for computing the probability density function (PDF), cumulative distribution function (CDF), Z-score, and confidence intervals. This library is designed to assist in the assessment of market volatility, distribution characteristics of asset returns, and risk management calculations, making it an invaluable resource for traders and financial analysts.
meanAndStdDev(source, length)
Calculates and returns the mean and standard deviation for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
length (int) : int: The lookback period for the calculation.
Returns: Returns an array where the first element is the mean and the second element is the standard deviation of the data series for the given period.
skewness(source, mean, stdDev, length)
Calculates and returns skewness for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns skewness value
kurtosis(source, mean, stdDev, length)
Calculates and returns kurtosis for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns kurtosis value
pdf(x, mean, stdDev)
pdf: Calculates the probability density function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the PDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the probability density function value for x.
cdf(x, mean, stdDev)
cdf: Calculates the cumulative distribution function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the CDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the cumulative distribution function value for x.
confidenceInterval(mean, stdDev, size, confidenceLevel)
Calculates the confidence interval for a data series mean.
Parameters:
mean (float) : float: The mean of the data series.
stdDev (float) : float: The standard deviation of the data series.
size (int) : int: The sample size.
confidenceLevel (float) : float: The confidence level (e.g., 0.95 for 95% confidence).
Returns: Returns the lower and upper bounds of the confidence interval.
Inverse Fisher Transform on STOCHASTIC (modified graphics)Modified the graphic representation of the script from John Ehlers - From California, USA, he is a veteran trader. With 35 years trading experience he has seen it all. John has an engineering background that led to his technical approach to trading ignoring fundamental analysis (with one important exception). John strongly believes in cycles. He’d rather exit a trade when the cycle ends or a new one starts. He uses the MESA principle to make predictions about cycles in the market and trades one hundred percent automatically.
In the show John reveals:
• What is more appropriate than trading individual stocks
• The one thing he relies upon in his approach to the market
• The detail surrounding his unique trading style
• What important thing underpins the market and gives every trader an edge
About INVERSE FISHER TRANSFORM:
The purpose of technical indicators is to help with your timing decisions to buy or sell. Hopefully, the signals are clear and unequivocal. However, more often than not your decision to pull the trigger is accompanied by crossing your fingers. Even if you have placed only a few trades you know the drill. In this article I will show you a way to make your oscillator-type indicators make clear black-or-white indication of the time to buy or sell. I will do this by using the Inverse Fisher Transform to alter the Probability Distribution Function (PDF) of your indicators. In the past12 I have noted that the PDF of price and indicators do not have a Gaussian, or Normal, probability distribution. A Gaussian PDF is the familiar bell-shaped curve where the long “tails” mean that wide deviations from the mean occur with relatively low probability. The Fisher Transform can be applied to almost any normalized data set to make the resulting PDF nearly Gaussian, with the result that the turning points are sharply peaked and easy to identify. The Fisher Transform is defined by the equation
1)
Whereas the Fisher Transform is expansive, the Inverse Fisher Transform is compressive. The Inverse Fisher Transform is found by solving equation 1 for x in terms of y. The Inverse Fisher Transform is:
2)
The transfer response of the Inverse Fisher Transform is shown in Figure 1. If the input falls between –0.5 and +0.5, the output is nearly the same as the input. For larger absolute values (say, larger than 2), the output is compressed to be no larger than unity. The result of using the Inverse Fisher Transform is that the output has a very high probability of being either +1 or –1. This bipolar probability distribution makes the Inverse Fisher Transform ideal for generating an indicator that provides clear buy and sell signals.

Inverse Fisher Transform COMBO STO+RSI+CCIv2 by KIVANÇ fr3762A combined 3in1 version of pre shared INVERSE FISHER TRANSFORM indicators on RSI , on STOCHASTIC and on CCIv2 to provide space for 2 more indicators for users...
About John EHLERS:
From California, USA, John is a veteran trader. With 35 years trading experience he has seen it all. John has an engineering background that led to his technical approach to trading ignoring fundamental analysis (with one important exception).
John strongly believes in cycles. He’d rather exit a trade when the cycle ends or a new one starts. He uses the MESA principle to make predictions about cycles in the market and trades one hundred percent automatically.
In the show John reveals:
• What is more appropriate than trading individual stocks
• The one thing he relies upon in his approach to the market
• The detail surrounding his unique trading style
• What important thing underpins the market and gives every trader an edge
About INVERSE FISHER TRANSFORM:
The purpose of technical indicators is to help with your timing decisions to buy or
sell. Hopefully, the signals are clear and unequivocal. However, more often than
not your decision to pull the trigger is accompanied by crossing your fingers.
Even if you have placed only a few trades you know the drill.
In this article I will show you a way to make your oscillator-type indicators make
clear black-or-white indication of the time to buy or sell. I will do this by using the
Inverse Fisher Transform to alter the Probability Distribution Function ( PDF ) of
your indicators. In the past12 I have noted that the PDF of price and indicators do
not have a Gaussian, or Normal, probability distribution. A Gaussian PDF is the
familiar bell-shaped curve where the long “tails” mean that wide deviations from
the mean occur with relatively low probability. The Fisher Transform can be
applied to almost any normalized data set to make the resulting PDF nearly
Gaussian, with the result that the turning points are sharply peaked and easy to
identify. The Fisher Transform is defined by the equation
1)
Whereas the Fisher Transform is expansive, the Inverse Fisher Transform is
compressive. The Inverse Fisher Transform is found by solving equation 1 for x
in terms of y. The Inverse Fisher Transform is:
2)
The transfer response of the Inverse Fisher Transform is shown in Figure 1. If
the input falls between –0.5 and +0.5, the output is nearly the same as the input.
For larger absolute values (say, larger than 2), the output is compressed to be no
larger than unity . The result of using the Inverse Fisher Transform is that the
output has a very high probability of being either +1 or –1. This bipolar
probability distribution makes the Inverse Fisher Transform ideal for generating
an indicator that provides clear buy and sell signals.
Creator: John EHLERS
Inverse Fisher Transform on SMI (Stochastic Momentum Index)Inverse Fisher Transform on SMI (Stochastic Momentum Index)
About John EHLERS:
From California, USA, John is a veteran trader. With 35 years trading experience he has seen it all. John has an engineering background that led to his technical approach to trading ignoring fundamental analysis (with one important exception).
John strongly believes in cycles. He’d rather exit a trade when the cycle ends or a new one starts. He uses the MESA principle to make predictions about cycles in the market and trades one hundred percent automatically.
In the show John reveals:
• What is more appropriate than trading individual stocks
• The one thing he relies upon in his approach to the market
• The detail surrounding his unique trading style
• What important thing underpins the market and gives every trader an edge
About INVERSE FISHER TRANSFORM:
The purpose of technical indicators is to help with your timing decisions to buy or
sell. Hopefully, the signals are clear and unequivocal. However, more often than
not your decision to pull the trigger is accompanied by crossing your fingers.
Even if you have placed only a few trades you know the drill.
In this article I will show you a way to make your oscillator-type indicators make
clear black-or-white indication of the time to buy or sell. I will do this by using the
Inverse Fisher Transform to alter the Probability Distribution Function (PDF) of
your indicators. In the past12 I have noted that the PDF of price and indicators do
not have a Gaussian, or Normal, probability distribution. A Gaussian PDF is the
familiar bell-shaped curve where the long “tails” mean that wide deviations from
the mean occur with relatively low probability. The Fisher Transform can be
applied to almost any normalized data set to make the resulting PDF nearly
Gaussian, with the result that the turning points are sharply peaked and easy to
identify. The Fisher Transform is defined by the equation
1)
Whereas the Fisher Transform is expansive, the Inverse Fisher Transform is
compressive. The Inverse Fisher Transform is found by solving equation 1 for x
in terms of y. The Inverse Fisher Transform is:
2)
The transfer response of the Inverse Fisher Transform is shown in Figure 1. If
the input falls between –0.5 and +0.5, the output is nearly the same as the input.
For larger absolute values (say, larger than 2), the output is compressed to be no
larger than unity. The result of using the Inverse Fisher Transform is that the
output has a very high probability of being either +1 or –1. This bipolar
probability distribution makes the Inverse Fisher Transform ideal for generating
an indicator that provides clear buy and sell signals.

Gaussian Fisher Transform Price Reversals - FTRHello Traders !
Looking for better trading results ?
"This indicator shows you how to identify price reversals in a timely manner." John F. Ehlers
Introduction :
The Gaussian Fisher Transform Price Reversals indicator, dubbed FTR for short, is a stat based price reversal detection indicator inspired by and based on the work of the electrical engineer now private trader John F. Ehlers.
The Fisher Transform :
It is a common assumption that prices have a gaussian / normal probability density function(PDF), i.e. a sample of n close prices would be normally distributed if the probability of observing a price value say at any given standard deviation range is equal to that probability in the case of the normal distribution, e.g. 68% off all samples fell within one standard deviation around the mean, which is what we would expect if the data was normal.
However Price Action is not normally distributed and thus can not be conventionally interpreted in this way, Formally the Fisher Transform, transforms the distribution of bounded ranging price action (were price action takes values in a range from -1 to 1) into that of a normal distribution, alternatively it may be said the Fisher Transform changes the PDF of any waveform so that the transformed output has n approximately Gaussian PDF, It does so through the following equations. taken directly from the work of John F. Ehlers - Using The Fisher Transform
By substituting price data in the above formulas, bounded ranging price actions (over a given user defined period lookback - this determines the range price ranges in, see the Intermediate formula above) distribution is transformed to that in the normal case. This means when the input, the Intermediate ,(the Midpoint - see formula above) approaches either limit within the range the outputs are greatly amplified, this amplification accentuates /puts more weight on the larger deviations or limits within the range, conversely when price action is varying round the mean of the range the output is approximately equal to unity (the input is approximately equal to the input, the intermediate)
The inputs (Intermediates) are converted to normal outputs and the nonlinear Transfer of the Fisher Transform with varying senesitivity's (gammas) can be seen in the graph / image above. Although sensitivity adjustments are not currently available in this script (I forgot to add it) the outputs may be greatly amplified as gamma (the coefficient of the Fisher Transformation - see Fish equation) approaches 1. the purple line show this graphically, as a higher gamma leads to a greater amplification than in the standard case (the red line which is the standard fisher transformation, the black plot is the Fish with a gamma of 1, which is unity sensativity)
Reversal plots and Breakouts :
- Support lines are plotted with their corresponding Fish value when there is a crossover of the Fish and Fish SMA <= a given standard deviation of Fish
- Resistance lines are plotted with their corresponding Fish value when there is a crossunder of the Fish and Fish SMA >= a given standard deviation of Fish
- Reversals are these support and resistance line plots
Breakouts and Volume bars :
Breakouts cause the reversal lines to break (when the high/low is above the resistance/support), Breakouts are more "high quality" when they occur conditional on high volume, the highlighted bars represent volume standard deviations ranging from -3 to 3. When breakouts occure on high volume this may be a sign of the continutaion of the trend (reversals would signify the start of a new trend).
Hope you enjoy, Happy Trading !
(be sure to rocket the script if you liked it, this helps me know which of my scripts are the most useful)

Dual Volume Profiles: Session + Rolling (Range Delineation)Dual Volume Profiles: Session + Rolling (Range Delineation)
INTRO
This is a probability-centric take on volume profile. I treat the volume histogram as an empirical PDF over price, updated in real time, which makes multi-modality (multiple acceptance basins) explicit rather than assumed away. The immediate benefit is operational: if we can read the shape of the distribution, we can infer likely reversion levels (POC), acceptance boundaries (VAH/VAL), and low-friction corridors (LVNs).
My working hypothesis is that what traders often label “fat tails” or “power-law behavior” at short horizons is frequently a tail-conditioned view of a higher-level Gaussian regime. In other words, child distributions (shorter periodicities) sit within parent distributions (longer periodicities); when price operates in the parent’s tail, the child regime looks heavy-tailed without being fundamentally non-Gaussian. This is consistent with a hierarchical/mixture view and with the spirit of the central limit theorem—Gaussian structure emerges at aggregate scales, while local scales can look non-Gaussian due to nesting and conditioning.
This indicator operationalizes that view by plotting two nested empirical PDFs: a rolling (local) profile and a session-anchored profile. Their confluence makes ranges explicit and turns “regime” into something you can see. For additional nesting, run multiple instances with different lookbacks. When using the default settings combined with a separate daily VP, you effectively get three nested distributions (local → session → daily) on the chart.
This indicator plots two nested distributions side-by-side:
Rolling (Local) Profile — short-window, prorated histogram that “breathes” with price and maps the immediate auction.
Session Anchored Profile — cumulative distribution since the current session start (Premkt → RTH → AH anchoring), revealing the parent regime.
Use their confluence to identify range floors/ceilings, mean-reversion magnets, and low-volume “air pockets” for fast traverses.
What it shows
POC (dashed): central tendency / “magnet” (highest-volume bin).
VAH & VAL (solid): acceptance boundaries enclosing an exact Value Area % around each profile’s POC.
Volume histograms:
Rolling can auto-color by buy/sell dominance over the lookback (green = buying ≥ selling, red = selling > buying).
Session uses a fixed style (blue by default).
Session anchoring (exchange timezone):
Premarket → anchors at 00:00 (midnight).
RTH → anchors at 09:30.
After-hours → anchors at 16:00.
Session display span:
Session Max Span (bars) = 0 → draw from session start → now (anchored).
> 0 → draw a rolling window N bars back → now, while still measuring all volume since session start.
Why it’s useful
Think in terms of nested probability distributions: the rolling node is your local Gaussian; the session node is its parent.
VA↔VA overlap ≈ strong range boundary.
POC↔POC alignment ≈ reliable mean-reversion target.
LVNs (gaps) ≈ low-friction corridors—expect quick moves to the next node.
Quick start
Add to chart (great on 5–10s, 15–60s, 1–5m).
Start with: bins = 240, vaPct = 0.68, barsBack = 60.
Watch for:
First test & rejection at overlapping VALs/VAHs → fade back toward POC.
Acceptance beyond VA (several closes + growing outer-bin mass) → traverse to the next node.
Inputs (detailed)
General
Lookback Bars (Rolling)
Count of most-recent bars for the rolling/local histogram. Larger = smoother node that shifts slower; smaller = more reactive, “breathing” profile.
• Typical: 40–80 on 5–10s charts; 60–120 on 1–5m.
• If you increase this but keep Number of Bins fixed, each bin aggregates more volume (coarser bins).
Number of Bins
Vertical resolution (price buckets) for both rolling and session histograms. Higher = finer detail and crisper LVNs, but more line objects (closer to platform limits).
• Typical: 120–240 on 5–10s; 80–160 on 1–5m.
• If you hit performance or object limits, reduce this first.
Value Area %
Exact central coverage for VAH/VAL around POC. Computed empirically from the histogram (no Gaussian assumption): the algorithm expands from POC outward until the chosen % is enclosed.
• Common: 0.68 (≈“1σ-like”), 0.70 for slightly wider core.
• Smaller = tighter VA (more breakout flags). Larger = wider VA (more reversion bias).
Max Local Profile Width (px)
Horizontal length (in pixels) of the rolling bars/lines and its VA/POC overlays. Visual only (does not affect calculations).
Session Settings
RTH Start/End (exchange tz)
Defines the current session anchor (Premkt=00:00, RTH=your start, AH=your end). The session histogram always measures from the most recent session start and resets at each boundary.
Session Max Span (bars, 0 = full session)
Display window for session drawings (POC/VA/Histogram).
• 0 → draw from session start → now (anchored).
• > 0 → draw N bars back → now (rolling look), while still measuring all volume since session start.
This keeps the “parent” distribution measurable while letting the display track current action.
Local (Rolling) — Visibility
Show Local Profile Bars / POC / VAH & VAL
Toggle each overlay independently. If you approach object limits, disable bars first (POC/VA lines are lighter).
Local (Rolling) — Colors & Widths
Color by Buy/Sell Dominance
Fast uptick/downtick proxy over the rolling window (close vs open):
• Buying ≥ Selling → Bullish Color (default lime).
• Selling > Buying → Bearish Color (default red).
This color drives local bars, local POC, and local VA lines.
• Disable to use fixed Bars Color / POC Color / VA Lines Color.
Bars Transparency (0–100) — alpha for the local histogram (higher = lighter).
Bars Line Width (thickness) — draw thin-line profiles or chunky blocks.
POC Line Width / VA Lines Width — overlay thickness. POC is dashed, VAH/VAL solid by design.
Session — Visibility
Show Session Profile Bars / POC / VAH & VAL
Independent toggles for the session layer.
Session — Colors & Widths
Bars/POC/VA Colors & Line Widths
Fixed palette by design (default blue). These do not change with buy/sell dominance.
• Use transparency and width to make the parent profile prominent or subtle.
• Prefer minimal? Hide session bars; keep only session VA/POC.
Reading the signals (detailed playbook)
Core definitions
POC — highest-volume bin (fair price “magnet”).
VAH/VAL — upper/lower bounds enclosing your Value Area % around POC.
Node — contiguous block of high-volume bins (acceptance).
LVN — low-volume gap between nodes (low friction path).
Rejection vs Acceptance (practical rule)
Rejection at VA edge: 0–1 closes beyond VA and no persistent growth in outer bins.
Acceptance beyond VA: ≥3 closes beyond VA and outer-bin mass grows (e.g., added volume beyond the VA edge ≥ 5–10% of node volume over the last N bars). Treat acceptance as regime change.
Confluence scores (make boundary/target quality objective)
VA overlap strength (range boundary):
C_VA = 1 − |VA_edge_local − VA_edge_session| / ATR(n)
Values near 1.0 = tight overlap (stronger boundary).
Use: if C_VA ≥ 0.6–0.8, treat as high-quality fade zone.
POC alignment (magnet quality):
C_POC = 1 − |POC_local − POC_session| / ATR(n)
Higher C_POC = greater chance a rotation completes to that fair price.
(You can estimate these by eye.)
Setups
1) Range Fade at VA Confluence (mean reversion)
Context: Local VAL/VAH near Session VAL/VAH (tight overlap), clear node, local color not screaming trend (or flips to your side).
Entry: First test & rejection at the overlapped band (wick through ok; prefer close back inside).
Stop: A tick/pip beyond the wider of the two VA edges or beyond the nearest LVN, a small buffer zone can be used to judge whether price is truly rejecting a VAL/VAH or simply probing.
Targets: T1 node mid; T2 POC (size up when C_POC is high).
Flip: If acceptance (rule above) prints, flip bias or stand down.
2) LVN Traverse (continuation)
Context: Price exits VA and enters an LVN with acceptance and growing outer-bin volume.
Entry: Aggressive—first close into LVN; Conservative—retest of the VA edge from the far side (“kiss goodbye”).
Stop: Back inside the prior VA.
Targets: Next node’s VA edge or POC (edge = faster exits; POC = fuller rotations).
Note: Flatter VA edge (shallower curvature) tends to breach more easily.
3) POC→POC Magnet Trade (rotation completion)
Context: Local POC ≈ Session POC (high C_POC).
Entry: Fade a VA touch or pullback inside node, aiming toward the shared POC.
Stop: Past the opposite VA edge or LVN beyond.
Target: The shared POC; optional runner to opposite VA if the node is broad and time-of-day is supportive.
4) Failed Break (Reversion Snap-back)
Context: Push beyond VA fails acceptance (re-enters VA, outer-bin growth stalls/shrinks).
Entry: On the re-entry close, back toward POC.
Stop/Target: Stop just beyond the failed VA; target POC, then opposite VA if momentum persists.
How to read color & shape
Local color = most recent sentiment:
Green = buying ≥ selling; Red = selling > buying (over the rolling window). Treat as context, not a standalone signal. A green local node under a blue session VAH can still be a fade if the parent says “over-valued.”
Shape tells friction:
Fat nodes → rotation-friendly (fade edges).
Sharp LVN gaps → traversal-friendly (momentum continuation).
Time-of-day intuition
Right after session anchor (e.g., RTH 09:30): Session profile is young and moves quickly—treat confluence cautiously.
Mid-session: Cleanest behavior for rotations.
Close / news: Expect more traverses and POC migrations; tighten risk or switch playbooks.
Risk & execution guidance
Use tight, mechanical stops at/just beyond VA or LVN. If you need wide stops to survive noise, your entry is late or the node is unstable.
On micro-timeframes, account for fees & slippage—aim for targets paying ≥2–3× average cost.
If acceptance prints, don’t fight it—flip, reduce size, or stand aside.
Suggested presets
Scalp (5–10s): bins 120–240, barsBack 40–80, vaPct 0.68–0.70, local bars thin (small bar width).
Intraday (1–5m): bins 80–160, barsBack 60–120, vaPct 0.68–0.75, session bars more visible for parent context.
Performance & limits
Reuses line objects to stay under TradingView’s max_lines_count.
Very large bins × multiple overlays can still hit limits—use visibility toggles (hide bars first).
Session drawings use time-based coordinates to avoid “bar index too far” errors.
Known nuances
Rolling buy/sell dominance uses a simple uptick/downtick proxy (close vs open). It’s fast and practical, but it’s not a full tape classifier.
VA boundaries are computed from the empirical histogram—no Gaussian assumption.
This script does not calculate the full daily volume profile. Several other tools already provide that, including TradingView’s built-in Volume Profile indicators. Instead, this indicator focuses on pairing a rolling, short-term volume distribution with a session-wide distribution to make ranges more explicit. It is designed to supplement your use of standard or periodic volume profiles, not replace them. Think of it as a magnifying lens that helps you see where local structure aligns with the broader session.
How to trade it (TL;DR)
Fade overlapping VA bands on first rejection → target POC.
Continue through LVN on acceptance beyond VA → target next node’s VA/POC.
Respect acceptance: ≥3 closes beyond VA + growing outer-bin volume = regime change.
FAQ
Q: Why 68% Value Area?
A: It mirrors the “~1σ” idea, but we compute it exactly from empirical volume, not by assuming a normal distribution.
Q: Why are my profiles thin lines?
A: Increase Bars Line Width for chunkier blocks; reduce for fine, thin-line profiles.
Q: Session bars don’t reach session start—why?
A: Set Session Max Span (bars) = 0 for full anchoring; any positive value draws a rolling window while still measuring from session start.
Changelog (v1.0)
Dual profiles: Rolling + Session with independent POC/VA lines.
Session anchoring (Premkt/RTH/AH) with optional rolling display span.
Dynamic coloring for the rolling profile (buying vs selling).
Fully modular toggles + per-feature colors/widths.
Thin-line rendering via bar line width.

Transient Impact Model [ScorsoneEnterprises]This indicator is an implementation of the Transient Impact Model. This tool is designed to show the strength the current trades have on where price goes before they decay.
Here are links to more sophisticated research articles about Transient Impact Models than this post arxiv.org and arxiv.org
The way this tool is supposed to work in a simple way, is when impact is high price is sensitive to past volume, past trades being placed. When impact is low, it moves in a way that is more independent from past volume. In a more sophisticated system, perhaps transient impact should be calculated for each trade that is placed, not just the total volume of a past bar. I didn't do it to ensure parameters exist and aren’t na, as well as to have more iterations for optimization. Note that the value will change as volume does, as soon as a new candle occurs with no volume, the values could be dramatically different.
How it works
There are a few components to this script, so we’ll go into the equation and then the other functions used in this script.
// Transient Impact Model
transient_impact(params, price_change, lkb) =>
alpha = array.get(params, 0)
beta = array.get(params, 1)
lambda_ = array.get(params, 2)
instantaneous = alpha * volume
transient = 0.0
for t = 1 to lkb - 1
if na(volume )
break
transient := transient + beta * volume * math.exp(-lambda_ * t)
predicted_change = instantaneous + transient
math.pow(price_change - predicted_change, 2)
The parameters alpha, beta, and lambda all represent a different real thing.
Alpha (α):
Represents the instantaneous impact coefficient. It quantifies the immediate effect of the current volume on the price change. In the equation, instantaneous = alpha * volume , alpha scales the current bar's volume (volume ) to determine how much of the price change is due to immediate market impact. A larger alpha suggests that current volume has a stronger instantaneous influence on price.
Beta (β):
Represents the transient impact coefficient.It measures the lingering effect of past volumes on the current price change. In the loop calculating transient, beta * volume * math.exp(-lambda_ * t) shows that beta scales the volume from previous bars (volume ), contributing to a decaying effect over time. A higher beta indicates a stronger influence from past volumes, though this effect diminishes with time due to the exponential decay factor.
Lambda (λ):
Represents the decay rate of the transient impact.It controls how quickly the influence of past volumes fades over time in the transient component. In the term math.exp(-lambda_ * t), lambda determines the rate of exponential decay, where t is the time lag (in bars). A larger lambda means the impact of past volumes decays faster, while a smaller lambda implies a longer-lasting effect.
So in full.
The instantaneous term, alpha * volume , captures the immediate price impact from the current volume.
The transient term, sum of beta * volume * math.exp(-lambda_ * t) over the lookback period, models the cumulative, decaying effect of past volumes.
The total predicted_change combines these two components and is compared to the actual price change to compute an error term, math.pow(price_change - predicted_change, 2), which the script minimizes to optimize alpha, beta, and lambda.
Other parts of the script.
Objective function:
This is a wrapper function with a function to minimize so we get the best alpha, beta, and lambda values. In this case it is the Transient Impact Function, not something like a log-likelihood function, helps with efficiency for a high iteration count.
Finite Difference Gradient:
This function calculates the gradient of the objective function we spoke about. The gradient is like a directional derivative. Which is like the direction of the rate of change. Which is like the direction of the slope of a hill, we can go up or down a hill. It nudges around the parameter, and calculates the derivative of the parameter. The array of these nudged around parameters is what is returned after they are optimized.
Minimize:
This is the function that actually has the loop and calls the Finite Difference Gradient each time. Here is where the minimizing happens, how we go down the hill. If we are below a tolerance, we are at the bottom of the hill.
Applied
After an initial guess, we optimize the parameters and get the transient impact value. This number is huge, so we apply a log to it to make it more readable. From here we need some way to tell if the value is low or high. We shouldn’t use standard deviation because returns are not normally distributed, an IQR is similar and better for non normal data. We store past transient impact values in an array, so that way we can see the 25th and 90th percentiles of the data as a rolling value. If the current transient impact is above the 90th percentile, it is notably high. If below the 25th percentile, notably low. All of these values are plotted so we can use it as a tool.
Tool examples:
The idea around it is that when impact is low, there is room for big money to get size quickly and move prices around.
Here we see the price reacting in the IQR Bands. We see multiple examples where the value above the 90th percentile, the red line, corresponds to continuations in the trend, and below the 25th percentile, the purple line, corresponds to reversals. There is no guarantee these tools will be perfect, that is outlined in these situations, however there is clearly a correlation in this tool and trend.
This tool works on any timeframe, daily as we saw before, or lower like a two minute. The bands don’t represent a direction, like bullish or bearish, we need to determine that by interpreting price action. We see at open and at close there are the highest values for the transient impact. This is to be expected as these are the times with the highest volume of the trading day.
This works on futures as well as equities with the same context. Volume can be attributed to volatility as well. In volatile situations, more volatility comes in, and we can perceive it through the transient impact value.
Inputs
Users can enter the lookback value.
No tool is perfect, the transient impact value is also not perfect and should not be followed blindly. It is good to use any tool along with discretion and price action.
ctndLibrary "ctnd"
Description:
Double precision algorithm to compute the cumulative trivariate normal distribution
found in A.Genz, Numerical computation of rectangular bivariate and trivariate normal
and t probabilities”, Statistics and Computing, 14, (3), 2004. The cumulative trivariate
normal is needed to price window barrier options, see G.F. Armstrong, Valuation formulae
or window barrier options”, Applied Mathematical Finance, 8, 2001.
References:
link.springer.com
www.tandfonline.com
citeseerx.ist.psu.edu
The Complete Guide to Option Pricing Formulas, 2nd ed. (Espen Gaarder Haug)
CTND(LIMIT1, LIMIT2, LIMIT3, SIGMA1, SIGMA2, SIGMA3)
Returns the Cumulative Trivariate Normal Distribution
Parameters:
LIMIT1 : float,
LIMIT2 : float,
LIMIT3 : float,
SIGMA1 : float,
SIGMA2 : float,
SIGMA3 : float,
Returns: float.

Variety N-Tuple Moving Averages w/ Variety Stepping [Loxx]Variety N-Tuple Moving Averages w/ Variety Stepping is a moving average indicator that allows you to create 1- 30 tuple moving average types; i.e., Double-MA, Triple-MA, Quadruple-MA, Quintuple-MA, ... N-tuple-MA. This version contains 2 different moving average types. For example, using "50" as the depth will give you Quinquagintuple Moving Average. If you'd like to find the name of the moving average type you create with the depth input with this indicator, you can find a list of tuples here: Tuples extrapolated
Due to the coding required to adapt a moving average to fit into this indicator, additional moving average types will be added as they are created to fit into this unique use case. Since this is a work in process, there will be many future updates of this indicator. For now, you can choose from either EMA or RMA.
This indicator is also considered one of the top 10 forex indicators. See details here: forex-station.com
Additionally, this indicator is a computationally faster, more streamlined version of the following indicators with the addition of 6 stepping functions and 6 different bands/channels types.
STD-Stepped, Variety N-Tuple Moving Averages
STD-Stepped, Variety N-Tuple Moving Averages is the standard deviation stepped/filtered indicator of the following indicator
Last but not least, a big shoutout to @lejmer for his help in formulating a looping solution for this streamlined version. this indicator is speedy even at 50 orders deep. You can find his scripts here: www.tradingview.com
How this works
Step 1: Run factorial calculation on the depth value,
Step 2: Calculate weights of nested moving averages
factorial(depth) / (factorial(depth - k) * factorial(k); where depth is the depth and k is the weight position
Examples of coefficient outputs:
6 Depth: 6 15 20 15 6
7 Depth: 7 21 35 35 21 7
8 Depth: 8 28 56 70 56 28 8
9 Depth: 9 36 34 84 126 126 84 36 9
10 Depth: 10 45 120 210 252 210 120 45 10
11 Depth: 11 55 165 330 462 462 330 165 55 11
12 Depth: 12 66 220 495 792 924 792 495 220 66 12
13 Depth: 13 78 286 715 1287 1716 1716 1287 715 286 78 13
Step 3: Apply coefficient to each moving average
For QEMA, which is 5 depth EMA , the calculation is as follows
ema1 = ta. ema ( src , length)
ema2 = ta. ema (ema1, length)
ema3 = ta. ema (ema2, length)
ema4 = ta. ema (ema3, length)
ema5 = ta. ema (ema4, length)
In this new streamlined version, these MA calculations are packed into an array inside loop so Pine doesn't have to keep all possible series information in memory. This is handled with the following code:
temp = array.get(workarr, k + 1) + alpha * (array.get(workarr, k) - array.get(workarr, k + 1))
array.set(workarr, k + 1, temp)
After we pack the array, we apply the coefficients to derive the NTMA:
qema = 5 * ema1 - 10 * ema2 + 10 * ema3 - 5 * ema4 + ema5
Stepping calculations
First off, you can filter by both price and/or MA output. Both price and MA output can be filtered/stepped in their own way. You'll see two selectors in the input settings. Default is ATR ATR. Here's how stepping works in simple terms: if the price/MA output doesn't move by X deviations, then revert to the price/MA output one bar back.
ATR
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
Standard Deviation
Standard deviation is a statistic that measures the dispersion of a dataset relative to its mean and is calculated as the square root of the variance. The standard deviation is calculated as the square root of variance by determining each data point's deviation relative to the mean. If the data points are further from the mean, there is a higher deviation within the data set; thus, the more spread out the data, the higher the standard deviation.
Adaptive Deviation
By definition, the Standard Deviation (STD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility .
Standard Deviation is based on Simple Moving Average calculation for mean value. This version of standard deviation uses the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA , we can call it EMA deviation. And added to that, Perry Kaufman's efficiency ratio is used to make it adaptive (since all EMA type calculations are nearly perfect for adapting).
The difference when compared to standard is significant--not just because of EMA usage, but the efficiency ratio makes it a "bit more logical" in very volatile market conditions.
See how this compares to Standard Devaition here:
Adaptive Deviation
Median Absolute Deviation
The median absolute deviation is a measure of statistical dispersion. Moreover, the MAD is a robust statistic, being more resilient to outliers in a data set than the standard deviation. In the standard deviation, the distances from the mean are squared, so large deviations are weighted more heavily, and thus outliers can heavily influence it. In the MAD, the deviations of a small number of outliers are irrelevant.
Because the MAD is a more robust estimator of scale than the sample variance or standard deviation, it works better with distributions without a mean or variance, such as the Cauchy distribution.
For this indicator, I used a manual recreation of the quantile function in Pine Script. This is so users have a full inside view into how this is calculated.
Efficiency-Ratio Adaptive ATR
Average True Range (ATR) is widely used indicator in many occasions for technical analysis . It is calculated as the RMA of true range. This version adds a "twist": it uses Perry Kaufman's Efficiency Ratio to calculate adaptive true range
See how this compares to ATR here:
ER-Adaptive ATR
Mean Absolute Deviation
The mean absolute deviation (MAD) is a measure of variability that indicates the average distance between observations and their mean. MAD uses the original units of the data, which simplifies interpretation. Larger values signify that the data points spread out further from the average. Conversely, lower values correspond to data points bunching closer to it. The mean absolute deviation is also known as the mean deviation and average absolute deviation.
This definition of the mean absolute deviation sounds similar to the standard deviation (SD). While both measure variability, they have different calculations. In recent years, some proponents of MAD have suggested that it replace the SD as the primary measure because it is a simpler concept that better fits real life.
For Pine Coders, this is equivalent of using ta.dev()
Bands/Channels
See the information above for how bands/channels are calculated. After the one of the above deviations is calculated, the channels are calculated as output +/- deviation * multiplier
Signals
Green is uptrend, red is downtrend, yellow "L" signal is Long, fuchsia "S" signal is short.
Included:
Alerts
Loxx's Expanded Source Types
Bar coloring
Signals
6 bands/channels types
6 stepping types
Related indicators
3-Pole Super Smoother w/ EMA-Deviation-Corrected Stepping
STD-Stepped Fast Cosine Transform Moving Average
ATR-Stepped PDF MA

MAMA by EHLERSMESA Adaptive Moving Average aka: Mother of Adaptive Moving Averages:
The MESA Adaptive Moving Average ( MAMA ) adapts to price movement in an
entirely new and unique way. The adapation is based on the rate change of phase as
measured by the Hilbert Transform Discriminator I have previously described.1
The advantage of this method of adaptation is that it features a fast attack average and a
slow decay average so that composite average rapidly ratchets behind price changes
and holds the average value until the next ratchet occurs. The action of MAMA is
shown in Figure 1. Since the average fallback is slow I can build trading systems that
are virtually free of whipsaw trades.
For detailed information of MAMA: (creators' PDF document)
www.mesasoftware.com
Long condition: when MAMA Crosses over FAMA (Following Adaptive Moving Average )
Short condition: when FAMA Crosses over MAMA
(Personally modified LazyBear's version which was originally calculated in degrees instead of radian by applying explanations in the MESA pdf document.http://www.mesasoftware.com/papers/MAMA.pdf)
Creator: John EHLERS

KK_Traders Dynamic Index_Bar HighlightingHey guys,
this is one of my favorite scripts as it represents a whole trading system that has given me very good results!
I have only used it on Bitcoin so far but I am sure it will also work for other instruments.
The original code to this was created by LazyBear, so all props to him for this great script!
I have linked his original post down below.
You can find the full rules to the system in this PDF (which has also been taken from LBs post):
www.forexmt4.com
Here is a short summary of the rules:
Go long when (all conditions have to be met):
The green line is above 50
The green line is above the red line
The green line is above the orange line
The close is above the upper Band of the Price Action Channel
The candles close is above its open
(The green line is below 68)
Go short when (all conditions have to be met):
The green line is below 50
The green line is below the red line
The green line is below the orange line
The close is below the lower band of the Price Action Channel
The candles close is below its open
(The green line is above 32)
Close when:
Any of these conditions aren't true anymore.
I have marked two of the rules in brackets as they seem to cut out a lot of the profits this system generates. You can choose to still use these rules by checking the box that says "Use Original Ruleset" in the options.
The system also contains rules regarding the Heiken Ashi bars. However these aren't as specific as the other rules. This is where your personal judgement comes in and this part is hard to explain. Take a look at the PDF I have linked to get a better understanding.
So far, this is just the TDI trading system and LBs script, now what have I changed?
I have incorporated the Price Action Channel to the system and changed it so that it highlights the bars whenever the system is giving a signal. As long as the bars are green the system is giving a long signal, as long as they are red the system is giving a short signal. Keep in mind that this doesn't consider the bar size of the HA bars. I recommend coloring all bars grey via the chart settings in order to be able to see the bar highlighting properly.
I have also published the Price Action Channel seperately in case some of you wish to view the Channel.
I am fairly new to creating scripts so use it with caution and let me know what you think!
LBs original post:
The seperate Price Action Channel script:

CM Stochastic POP Method 1 - Jake Bernstein_V1A good friend ucsgears recently published a Stochastic Pop Indicator designed by Jake Bernstein with a modified version he found.
I spoke to Jake this morning and asked if he had any updates to his Stochastic POP Trading Method. Attached is a PDF Jake published a while back (Please read for basic rules, which also Includes a New Method). I will release the Additional Method Tomorrow.
Jake asked me to share that he has Updated this Method Recently. Now across all symbols he has found the Stochastic Values of 60 and 30 to be the most profitable. NOTE - This can be Significantly Optimized for certain Symbols/Markets.
Jake Bernstein will be a contributor on TradingView when Backtesting/Strategies are released. Jake is one of the Top Trading System Developers in the world with 45+ years experience and he is going to teach how to create Trading Systems and how to Optimize the correct way.
Below are a few Strategy Results....Soon You Will Be Able To Find Results Like This Yourself on TradingView.com
BackTesting Results Example: EUR-USD Daily Chart Since 01/01/2005
Strategy 1:
Go Long When Stochastic Crosses Above 60. Go Short When Stochastic Crosses Below 30. Exit Long/Short When Stochastic has a Reverse Cross of Entry Value.
Results:
Total Trades = 164
Profit = 50, 126 Pips
Win% = 38.4%
Profit Factor = 1.35
Avg Trade = 306 Pips Profit
***Most Consecutive Wins = 3 ... Most Consecutive Losses = 6
Strategy 2:
Rules - Proprietary Optimization Jake Will Teach. Only Added 1 Additional Exit Rule.
Results:
Total Trades = 164
Profit = 62, 876 Pips!!!
Win% = 38.4%
Profit Factor = 1.44
Avg Trade = 383 Pips Profit
***Most Consecutive Wins = 3 ... Most Consecutive Losses = 6
Strategy 3:
Rules - Proprietary Optimization Jake Will Teach. Only added 1 Additional Exit Rule.
Results:
Winning Percent Increases to 72.6%!!! , Same Amount of Trades.
***Most Consecutive Wins = 21 ...Most Consecutive Losses = 4
Indicator Includes:
-Ability to Color Candles (CheckBox In Inputs Tab)
Green = Long Trade
Blue = No Trade
Red = Short Trade
-Color Coded Stochastic Line based on being Above/Below or In Between Entry Lines.
Link To Jakes PDF with Rules
dl.dropboxusercontent.com

CM RSI-2 Strategy Lower IndicatorRSI-2 Strategy
***At the bottom of the page is a link where you can download the PDF of the Backtesting Results.
This year I am focusing on learning from two of the best mentors in the Industry with outstanding track records for Creating Systems, and learning the what methods actually work as far as back testing.
I came across the RSI-2 system that Larry Connors developed. Larry has become famous for his technical indicators, but his RSI-2 system is what actually put him “On The Map” per se. At first glance I didn’t think it would work well, but I decided to code it and ran backtests on the S&P 100 In Down Trending Markets, Up Trending Markets, and both combined. I was shocked by the results. So I thought I would provide them for you. I also ran a test on the Major forex Pairs (12) for the last 5 years, and All Forex Pairs (80) from 11/28/2007 - 6/09/2014, impressive results also.
The RSI-2 Strategy is designed to use on Daily Bars, however it is a short term trading strategy. The average length of time in a trade is just over 2 days. But the results CRUSH the general market averages.
Detailed Description of Indicators, Rules Below:
Link For PDF of Detailed Trade Results
d.pr
Original Post
CM RSI-2 Strategy - Upper Indicators.RSI-2 Strategy
***At the bottom of the page is a link where you can download the PDF of the Backtesting Results.
This year I am focusing on learning from two of the best mentors in the Industry with outstanding track records for Creating Systems, and learning the what methods actually work as far as back testing.
I came across the RSI-2 system that Larry Connors developed. Larry has become famous for his technical indicators, but his RSI-2 system is what actually put him “On The Map” per se. At first glance I didn’t think it would work well, but I decided to code it and ran backtests on the S&P 100 In Down Trending Markets, Up Trending Markets, and both combined. I was shocked by the results. So I thought I would provide them for you. I also ran a test on the Major forex Pairs (12) for the last 5 years, and All Forex Pairs (80) from 11/28/2007 - 6/09/2014, impressive results also.
The RSI-2 Strategy is designed to use on Daily Bars, however it is a short term trading strategy. The average length of time in a trade is just over 2 days. But the results CRUSH the general market averages.
Detailed Description of Indicators, Rules Below:
Link For PDF of Detailed Trade Results
d.pr
Original Post

TimeSeriesBenchmarkMeasuresLibrary "TimeSeriesBenchmarkMeasures"
Time Series Benchmark Metrics. \
Provides a comprehensive set of functions for benchmarking time series data, allowing you to evaluate the accuracy, stability, and risk characteristics of various models or strategies. The functions cover a wide range of statistical measures, including accuracy metrics (MAE, MSE, RMSE, NRMSE, MAPE, SMAPE), autocorrelation analysis (ACF, ADF), and risk measures (Theils Inequality, Sharpness, Resolution, Coverage, and Pinball).
___
Reference:
- github.com .
- medium.com .
- www.salesforce.com .
- towardsdatascience.com .
- github.com .
mae(actual, forecasts)
In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement.
Parameters:
actual (array) : List of actual values.
forecasts (array) : List of forecasts values.
Returns: - Mean Absolute Error (MAE).
___
Reference:
- en.wikipedia.org .
- The Orange Book of Machine Learning - Carl McBride Ellis .
mse(actual, forecasts)
The Mean Squared Error (MSE) is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
Parameters:
actual (array) : List of actual values.
forecasts (array) : List of forecasts values.
Returns: - Mean Squared Error (MSE).
___
Reference:
- en.wikipedia.org .
rmse(targets, forecasts, order, offset)
Calculates the Root Mean Squared Error (RMSE) between target observations and forecasts. RMSE is a standard measure of the differences between values predicted by a model and the values actually observed.
Parameters:
targets (array) : List of target observations.
forecasts (array) : List of forecasts.
order (int) : Model order parameter that determines the starting position in the targets array, `default=0`.
offset (int) : Forecast offset related to target, `default=0`.
Returns: - RMSE value.
nmrse(targets, forecasts, order, offset)
Normalised Root Mean Squared Error.
Parameters:
targets (array) : List of target observations.
forecasts (array) : List of forecasts.
order (int) : Model order parameter that determines the starting position in the targets array, `default=0`.
offset (int) : Forecast offset related to target, `default=0`.
Returns: - NRMSE value.
rmse_interval(targets, forecasts)
Root Mean Squared Error for a set of interval windows. Computes RMSE by converting interval forecasts (with min/max bounds) into point forecasts using the mean of the interval bounds, then compares against actual target values.
Parameters:
targets (array) : List of target observations.
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - RMSE value for the combined interval list.
mape(targets, forecasts)
Mean Average Percentual Error.
Parameters:
targets (array) : List of target observations.
forecasts (array) : List of forecasts.
Returns: - MAPE value.
smape(targets, forecasts, mode)
Symmetric Mean Average Percentual Error. Calculates the Mean Absolute Percentage Error (MAPE) between actual targets and forecasts. MAPE is a common metric for evaluating forecast accuracy, expressed as a percentage, lower values indicate a better forecast accuracy.
Parameters:
targets (array) : List of target observations.
forecasts (array) : List of forecasts.
mode (int) : Type of method: default=0:`sum(abs(Fi-Ti)) / sum(Fi+Ti)` , 1:`mean(abs(Fi-Ti) / ((Fi + Ti) / 2))` , 2:`mean(abs(Fi-Ti) / (abs(Fi) + abs(Ti))) * 100`
Returns: - SMAPE value.
mape_interval(targets, forecasts)
Mean Average Percentual Error for a set of interval windows.
Parameters:
targets (array) : List of target observations.
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - MAPE value for the combined interval list.
acf(data, k)
Autocorrelation Function (ACF) for a time series at a specified lag.
Parameters:
data (array) : Sample data of the observations.
k (int) : The lag period for which to calculate the autocorrelation. Must be a non-negative integer.
Returns: - The autocorrelation value at the specified lag, ranging from -1 to 1.
___
The autocorrelation function measures the linear dependence between observations in a time series
at different time lags. It quantifies how well the series correlates with itself at different
time intervals, which is useful for identifying patterns, seasonality, and the appropriate
lag structure for time series models.
ACF values close to 1 indicate strong positive correlation, values close to -1 indicate
strong negative correlation, and values near 0 indicate no linear correlation.
___
Reference:
- statisticsbyjim.com
acf_multiple(data, k)
Autocorrelation function (ACF) for a time series at a set of specified lags.
Parameters:
data (array) : Sample data of the observations.
k (array) : List of lag periods for which to calculate the autocorrelation. Must be a non-negative integer.
Returns: - List of ACF values for provided lags.
___
The autocorrelation function measures the linear dependence between observations in a time series
at different time lags. It quantifies how well the series correlates with itself at different
time intervals, which is useful for identifying patterns, seasonality, and the appropriate
lag structure for time series models.
ACF values close to 1 indicate strong positive correlation, values close to -1 indicate
strong negative correlation, and values near 0 indicate no linear correlation.
___
Reference:
- statisticsbyjim.com
adfuller(data, n_lag, conf)
: Augmented Dickey-Fuller test for stationarity.
Parameters:
data (array) : Data series.
n_lag (int) : Maximum lag.
conf (string) : Confidence Probability level used to test for critical value, (`90%`, `95%`, `99%`).
Returns: - `adf` The test statistic.
- `crit` Critical value for the test statistic at the 10 % levels.
- `nobs` Number of observations used for the ADF regression and calculation of the critical values.
___
The Augmented Dickey-Fuller test is used to determine whether a time series is stationary
or contains a unit root (non-stationary). The null hypothesis is that the series has a unit root
(is non-stationary), while the alternative hypothesis is that the series is stationary.
A stationary time series has statistical properties that do not change over time, making it
suitable for many time series forecasting models. If the test statistic is less than the
critical value, we reject the null hypothesis and conclude the series is stationary.
___
Reference:
- www.jstor.org
- en.wikipedia.org
theils_inequality(targets, forecasts)
Calculates Theil's Inequality Coefficient, a measure of forecast accuracy that quantifies the relative difference between actual and predicted values.
Parameters:
targets (array) : List of target observations.
forecasts (array) : Matrix with list of forecasts, ordered column wise.
Returns: - Theil's Inequality Coefficient value, value closer to 0 is better.
___
Theil's Inequality Coefficient is calculated as: `sqrt(Sum((y_i - f_i)^2)) / (sqrt(Sum(y_i^2)) + sqrt(Sum(f_i^2)))`
where `y_i` represents actual values and `f_i` represents forecast values.
This metric ranges from 0 to infinity, with 0 indicating perfect forecast accuracy.
___
Reference:
- en.wikipedia.org
sharpness(forecasts)
The average width of the forecast intervals across all observations, representing the sharpness or precision of the predictive intervals.
Parameters:
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - Sharpness The sharpness level, which is the average width of all prediction intervals across the forecast horizon.
___
Sharpness is an important metric for evaluating forecast quality. It measures how narrow or wide the
prediction intervals are. Higher sharpness (narrower intervals) indicates greater precision in the
forecast intervals, while lower sharpness (wider intervals) suggests less precision.
The sharpness metric is calculated as the mean of the interval widths across all observations, where
each interval width is the difference between the upper and lower bounds of the prediction interval.
Note: This function assumes that the forecasts matrix has at least 2 columns, with the first column
representing the lower bounds and the second column representing the upper bounds of prediction intervals.
___
Reference:
- Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: principles and practice. OTexts. otexts.com
resolution(forecasts)
Calculates the resolution of forecast intervals, measuring the average absolute difference between individual forecast interval widths and the overall sharpness measure.
Parameters:
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - The average absolute difference between individual forecast interval widths and the overall sharpness measure, representing the resolution of the forecasts.
___
Resolution is a key metric for evaluating forecast quality that measures the consistency of prediction
interval widths. It quantifies how much the individual forecast intervals vary from the average interval
width (sharpness). High resolution indicates that the forecast intervals are relatively consistent
across observations, while low resolution suggests significant variation in interval widths.
The resolution is calculated as the mean absolute deviation of individual interval widths from the
overall sharpness value. This provides insight into the uniformity of the forecast uncertainty
estimates across the forecast horizon.
Note: This function requires the forecasts matrix to have at least 2 columns (min, max) representing
the lower and upper bounds of prediction intervals.
___
Reference:
- (sites.stat.washington.edu)
- (www.jstor.org)
coverage(targets, forecasts)
Calculates the coverage probability, which is the percentage of target values that fall within the corresponding forecasted prediction intervals.
Parameters:
targets (array) : List of target values.
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - Percent of target values that fall within their corresponding forecast intervals, expressed as a decimal value between 0 and 1 (or 0% and 100%).
___
Coverage probability is a crucial metric for evaluating the reliability of prediction intervals.
It measures how well the forecast intervals capture the actual observed values. An ideal forecast
should have a coverage probability close to the nominal confidence level (e.g., 90%, 95%, or 99%).
For example, if a 95% prediction interval is used, we expect approximately 95% of the actual
target values to fall within those intervals. If the coverage is significantly lower than the
nominal level, the intervals may be too narrow; if it's significantly higher, the intervals may
be too wide.
Note: This function requires the targets array and forecasts matrix to have the same number of
observations, and the forecasts matrix must have at least 2 columns (min, max) representing
the lower and upper bounds of prediction intervals.
___
Reference:
- (www.jstor.org)
pinball(tau, target, forecast)
Pinball loss function, measures the asymmetric loss for quantile forecasts.
Parameters:
tau (float) : The quantile level (between 0 and 1), where 0.5 represents the median.
target (float) : The actual observed value to compare against.
forecast (float) : The forecasted value.
Returns: - The Pinball loss value, which quantifies the distance between the forecast and target relative to the specified quantile level.
___
The Pinball loss function is specifically designed for evaluating quantile forecasts. It is
asymmetric, meaning it penalizes underestimates and overestimates differently depending on the
quantile level being evaluated.
For a given quantile τ, the loss function is defined as:
- If target >= forecast: (target - forecast) * τ
- If target < forecast: (forecast - target) * (1 - τ)
This loss function is commonly used in quantile regression and probabilistic forecasting
to evaluate how well forecasts capture specific quantiles of the target distribution.
___
Reference:
- (www.otexts.com)
pinball_mean(tau, targets, forecasts)
Calculates the mean pinball loss for quantile regression.
Parameters:
tau (float) : The quantile level (between 0 and 1), where 0.5 represents the median.
targets (array) : The actual observed values to compare against.
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - The mean pinball loss value across all observations.
___
The pinball_mean() function computes the average Pinball loss across multiple observations,
making it suitable for evaluating overall forecast performance in quantile regression tasks.
This function leverages the asymmetric Pinball loss function to evaluate how well forecasts
capture specific quantiles of the target distribution. The choice of which column from the
forecasts matrix to use depends on the quantile level:
- For τ ≤ 0.5: Uses the first column (min) of forecasts
- For τ > 0.5: Uses the second column (max) of forecasts
This loss function is commonly used in quantile regression and probabilistic forecasting
to evaluate how well forecasts capture specific quantiles of the target distribution.
___
Reference:
- (www.otexts.com)