First-Move-Wrong Toolkit [CHE] First-Move-Wrong Toolkit — Session-bound sweep rejection with structure confirmation
Summary
This indicator marks potential “first move wrong” reversals during a defined trading session. It looks for a quick sweep beyond the prior day high or low, or the opening range high or low, followed by rejection and a basic structure confirmation. Optional rules require a retest and a VWAP reclaim in the direction of the trade idea. The script renders session levels as right-extended lines, signals as labels, optional SL/TP guide lines for visualization, and background tints during sweep events. Pivots are confirmed using swing width, which reduces repaint risk compared to live swings.
Motivation: Why this design?
Intraday reversals often start with a liquidity sweep around obvious highs or lows. Acting on the sweep alone can be noisy, while waiting for structure break and a retest can be slow. This tool balances both by checking a sweep and rejection at session-relevant levels, then requiring a simple structure cue and, optionally, a retest and a VWAP filter. The goal is a clear, rule-based signal layer that is easy to audit on chart without hidden state.
What’s different vs. standard approaches?
Baseline reference: Simple sweep detectors or basic CHOCH markers that ignore session context and liquidity anchors.
Architecture differences:
Session-aware opening range tracking that finalizes after the chosen minutes from session start.
Daily previous high and low pulled without lookahead, then extended forward as visual anchors.
Confirmed pivot highs and lows to avoid repaint from live, unconfirmed swings.
Optional retest rule using crossover or crossunder at the trigger level.
Optional VWAP filter to demand reclaim in the intended direction.
Global label cooldown to prevent clusters of signals.
Practical effect: Fewer one-off flips around noisy levels, clearer alignment with session structure, and compact visual feedback through lines, labels, and tints.
How it works (technical)
Levels: During the defined session, the script builds an opening range high and low until the configured minute mark after session start, then freezes those levels for the day. It also fetches the previous day high and low from the daily timeframe without lookahead and extends them forward.
Sweep and rejection: A sweep is defined as price moving beyond a target level and then rejecting back inside on the same bar. The script checks this condition separately for highs and lows against opening range and previous-day levels.
Structure validation: Confirmed pivot highs and lows are computed using a symmetric swing width. A bearish idea requires a prior sweep of a high plus a break through the last confirmed swing low. A bullish idea requires a prior sweep of a low plus a break through the last confirmed swing high.
Optional retest: If enabled, a bearish signal needs a cross under the bearish trigger level; a bullish signal needs a cross over the bullish trigger level.
VWAP filter (optional): The script requires a reclaim of VWAP in the intended direction when enabled.
State handling: Opening range values, previous-day lines, and the label cooldown timestamp are stored in persistent variables. Lines are created once and updated each bar to extend forward.
Repaint considerations: Pivots confirm only after the specified swing width, reducing repaint. The daily level request is performed without lookahead. Signals use closed-bar checks implied by crossover and crossunder logic.
Parameter Guide
Session (local) — Defines the active trading window. Default nine to seventeen. Narrower windows focus on the main session drive.
Opening Range (min) — Minutes from session start to finalize OR levels. Default fifteen. Shorter values react faster; longer values stabilize levels.
Use PrevDay H/L levels — Toggle previous-day anchors. On by default.
Use OR H/L levels — Toggle opening range anchors. On by default.
Equal H/L tolerance (ticks) — Intended tolerance for equal highs or lows. Default one. (Unknown/Optional) in current signals.
Swing width — Bars on both sides for confirmed pivots. Default two. Larger values reduce noise but confirm later.
Require CHOCH after sweep — Enforces structure break after a sweep. On by default.
Prefer retest entries — Requires crossover or crossunder of the trigger level. On by default.
VWAP filter — Demands a reclaim of VWAP in signal direction. Off by default.
TP in R (guide) — Multiplier for visual TP guides. Default one. Visualization only.
Show levels / Show signals / Show R-guides — Rendering toggles. R-guides are visual aids, not orders.
Label cooldown (bars) — Minimum bars between labels. Default five. Higher values reduce clusters.
Palette inputs — Colors and transparencies for levels, labels, VWAP, and tints.
Reading & Interpretation
Lines: Dotted lines represent opening range high and low after the OR window completes. Dashed lines represent previous-day high and low.
Signals: “Long” labels appear after a low-side sweep with rejection and structure confirmation, subject to optional retest and VWAP rules. “Short” labels mirror this on the high side.
Background tints: Red-tinted bars indicate a high-side sweep and rejection. Green-tinted bars indicate a low-side sweep and rejection.
R-guides: Circles display a visual stop level at the bar extreme and a target guide based on the selected multiple. They are informational only.
Practical Workflows & Combinations
Session reversal scans: During the first hour, watch for sweeps around previous-day or opening range levels, then wait for structure confirmation and optional retest.
Trend following with filters: Combine signals with higher-timeframe structure or a moving average regime check. Ignore signals against the dominant regime.
Exits and stops: Use the visual stop as a reference near the sweep extreme; adapt the target guide to volatility and market conditions.
Multi-asset / Multi-TF: Works on intraday timeframes for liquid futures, indices, forex, and large-cap equities. Start with default settings and adjust swing width and OR minutes to instrument volatility.
Behavior, Constraints & Performance
Repaint/confirmation: Pivots confirm after the swing window completes. Signals occur only when conditions are met on closed bars.
security()/HTF: Daily previous-day levels are requested without lookahead to reduce repaint.
Resources: Uses persistent variables and line updates per bar; no heavy loops or arrays.
Known limits: Signals can arrive later when swing width is large. Gaps around session boundaries may distort OR levels. VWAP behavior may vary with partial sessions or illiquid assets.
Sensible Defaults & Quick Tuning
Starting point: Session nine to seventeen, opening range fifteen minutes, swing width two, CHOCH required, retest on, VWAP off, cooldown five bars.
Too many flips: Increase swing width, enable VWAP filter, or raise label cooldown.
Too sluggish: Reduce swing width or shorten the opening range window.
Too many session-level hits: Disable either previous-day levels or opening range levels to simplify context.
What this indicator is—and isn’t
This is a session-aware visualization and signal layer focused on sweep-plus-structure behavior. It is not a complete trading system and does not manage orders, risk, or portfolio exposure. Use it with market structure, risk limits, and execution rules that fit your process.
Disclaimer
The content provided, including all code and materials, is strictly for educational and informational purposes only. It is not intended as, and should not be interpreted as, financial advice, a recommendation to buy or sell any financial instrument, or an offer of any financial product or service. All strategies, tools, and examples discussed are provided for illustrative purposes to demonstrate coding techniques and the functionality of Pine Script within a trading context.
Any results from strategies or tools provided are hypothetical, and past performance is not indicative of future results. Trading and investing involve high risk, including the potential loss of principal, and may not be suitable for all individuals. Before making any trading decisions, please consult with a qualified financial professional to understand the risks involved.
By using this script, you acknowledge and agree that any trading decisions are made solely at your discretion and risk.
Do not use this indicator on Heikin-Ashi, Renko, Kagi, Point-and-Figure, or Range charts, as these chart types can produce unrealistic results for signal markers and alerts.
Best regards and happy trading
Chervolino
"如何用wind搜索股票的发行价和份数" için komut dosyalarını ara

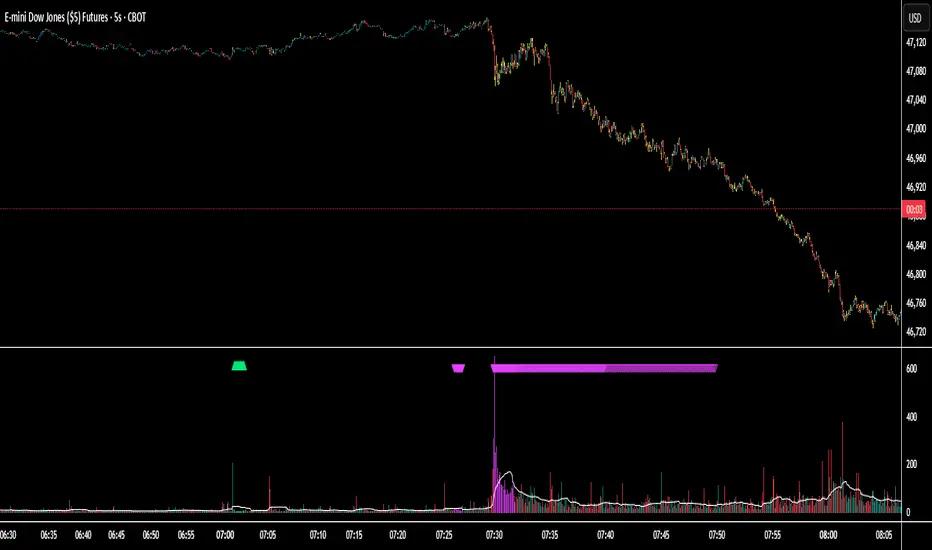
Session Volume Spike Detector (MTF Arrows)Overview
The Session Volume Spike Detector is a precision multi-timeframe (MTF) tool that identifies sudden surges in buy or sell volume during key market windows. It highlights high-impact institutional participation by comparing current volume against its historical baseline and short-term highs, then plots directional markers on your chart.
This version adds MTF awareness, showing spikes from 1-minute, 5-minute, and 10-minute frames on a single chart. It’s ideal for traders monitoring microstructure shifts across multiple time compressions while staying on a fast chart (like 1-second or 1-minute).
Key Features
Dual Session Windows (DST-aware)
Automatically tracks Morning (05:30–08:30 MT) and Midday (11:00–13:30 MT) activity, adjusted for daylight savings.
Directional Spike Detection
Flags Buy spikes (green triangles) and Sell spikes (magenta triangles) using dynamic volume gates, Z-Score normalization, and recent-bar jump filters.
Multi-Timeframe Projection
Displays higher-timeframe (1m / 5m / 10m) spikes directly on your active chart for continuous visual context — even on sub-minute intervals.
Adaptive Volume Logic
Each spike is validated against:
Volume ≥ SMA × multiplier
Volume ≥ recent-high × jump factor
Optional Z-Score threshold for statistical significance
Session-Only Filtering
Ensures spikes are only plotted within specified trading sessions — ideal for futures or intraday equity traders.
Configurable Alerts
Built-in alert conditions for:
Any timeframe (MTF aggregate)
Individual 1m, 5m, or 10m windows
Alerts trigger only when a new qualifying spike appears at the close of its bar.
Use Cases
Detect algorithmic or institutional activity bursts inside your trading window.
Track confluence of volume surges across multiple timeframes.
Combine with FVGs, bank levels, or range breakouts to identify probable continuation or reversal zones.
Build custom automation or alert workflows around statistically unusual participation spikes.
Recommended Settings
Use on 1-minute chart for full MTF display.
Adjust the SMA length (default 20) and Z-Score threshold (default 3.0) to suit market volatility.
For scalping or high-frequency environments, disable the 10m layer to reduce visual clutter.
Credits
Developed by Jason Hyde
© 2025 — All rights reserved.
Designed for clarity, precision, and MTF-synchronized institutional volume detection.
SuperTrend Optimizer Remastered[CHE] SuperTrend Optimizer Remastered — Grid-ranked SuperTrend with additive or multiplicative scoring
Summary
This indicator evaluates a fixed grid of one hundred and two SuperTrend parameter pairs and ranks them by a simple flip-to-flip return model. It auto-selects the currently best-scoring combination and renders its SuperTrend in real time, with optional gradient coloring for faster visual parsing. The original concept is by KioseffTrading Thanks a lot for it.
For years I wanted to shorten the roughly two thousand three hundred seventy-one lines; I have now reduced the core to about three hundred eighty lines without triggering script errors. The simplification is generalizable to other indicators. A multiplicative return mode was added alongside the existing additive aggregation, enabling different rankings and often more realistic compounding behavior.
Motivation: Why this design?
SuperTrend is sensitive to its factor and period. Picking a single pair statically can underperform across regimes. This design sweeps a compact parameter grid around user-defined lower bounds, measures flip-to-flip outcomes, and promotes the combination with the strongest cumulative return. The approach keeps the visual footprint familiar while removing manual trial-and-error. The multiplicative mode captures compounding effects; the additive mode remains available for linear aggregation.
Originally (by KioseffTrading)
Very long script (~2,371 lines), monolithic structure.
SuperTrend optimization with additive (cumulative percentage-sum) scoring only.
Heavier use of repetitive code; limited modularity and fewer UI conveniences.
No explicit multiplicative compounding option; rankings did not reflect sequence-sensitive equity growth.
Now (remastered by CHE)
Compact core (~380 lines) with the same functional intent, no compile errors.
Adds multiplicative (compounding) scoring alongside additive, changing rankings to reflect real equity paths and penalize drawdown sequences.
Fixed 34×3 grid sweep, live ranking, gradient-based bar/wick/line visuals, top-table display, and an optional override plot.
Cleaner arrays/state handling, last-bar table updates, and reusable simplification pattern that can be applied to other indicators.
What’s different vs. standard approaches?
Baseline: A single SuperTrend with hand-picked inputs.
Architecture differences:
Fixed grid of thirty-four factor offsets across three ATR offsets.
Per-combination flip-to-flip backtest with additive or multiplicative aggregation.
Live ranking with optional “Best” or “Worst” table output.
Gradient bar, wick, and line coloring driven by consecutive trend counts.
Optional override plot to force a specific SuperTrend independent of ranking.
Practical effect: Charts show the currently best-scoring SuperTrend, not a static choice, plus an on-chart table of top performers for transparency.
How it works (technical)
For each parameter pair, the script computes SuperTrend value and direction. It monitors direction transitions and treats a change from up to down as a long entry and the reverse as an exit, measuring the move between entry and exit using close prices. Results are aggregated per pair either by summing percentage changes or by compounding return factors and then converting to percent for comparison. On the last bar, open trades are included as unrealized contributions to ranking. The best combination’s line is plotted, with separate styling for up and down regimes. Consecutive regime counts are normalized within a rolling window and mapped to gradients for bars, wicks, and lines. A two-column table reports the best or worst performers, with an optional row describing the parameter sweep.
Parameter Guide
Factor (Lower Bound) — Starting SuperTrend factor; the grid adds offsets between zero and three point three. Default three point zero. Higher raises distance to price and reduces flips.
ATR Period (Lower Bound) — Starting ATR length; the grid adds zero, one, and two. Default ten. Longer reduces noise at the cost of responsiveness.
Best vs Worst — Ranks by top or bottom cumulative return. Default Best. Use Worst for stress tests.
Calculation Mode — Additive sums percents; Multiplicative compounds returns. Multiplicative is closer to equity growth and can change the leaderboard.
Show in Table — “Top Three” or “All”. Fewer rows keep charts clean.
Show “Parameters Tested” Label — Displays the effective sweep ranges for auditability.
Plot Override SuperTrend — If enabled, the override factor and ATR are plotted instead of the ranked winner.
Override Factor / ATR Period — Values used when override is on.
Light Mode (for Table) — Adjusts table colors for bright charts.
Gradient/Coloring controls — Toggles for gradient bars and wick coloring, window length for normalization, gamma for contrast, and transparency settings. Use these to emphasize or tone down visual intensity.
Table Position and Text Size — Places the table and sets typography.
Reading & Interpretation
The auto SuperTrend plots one line for up regimes and one for down regimes. Color intensity reflects consecutive trend persistence within the chosen window. A small square at the bottom encodes the same gradient as a compact status channel. Optional wick coloring uses the same gradient for maximum contrast. The performance table lists parameter pairs and their cumulative return under the chosen aggregation; positive values are tinted with the up color, negative with the down color. “Long” labels mark flips that open a long in the simplified model.
Practical Workflows & Combinations
Trend following: Use the auto line as your primary bias. Enter on flips aligned with structure such as higher highs and higher lows. Filter with higher-timeframe trend or volatility contraction.
Exits/Stops: Consider conservative exits when color intensity fades or when the opposite line is approached. Aggressive traders can trail near the plotted line.
Override mode: When you want stability across instruments, enable override and standardize factor and ATR; keep the table visible for sanity checks.
Multi-asset/Multi-TF: Defaults travel well on liquid instruments and intraday to daily timeframes. Heavier assets may prefer larger lower bounds or multiplicative mode.
Behavior, Constraints & Performance
Repaint/confirmation: Signals are based on SuperTrend direction; confirmation is best assessed on closed bars to avoid mid-bar oscillation. No higher-timeframe requests are used.
Resources: One hundred and two SuperTrend evaluations per bar, arrays for state, and a last-bar table render. This is efficient for the grid size but avoid stacking many instances.
Known limits: The flip model ignores costs, slippage, and short exposure. Rapid whipsaws can degrade both aggregation modes. Gradients are cosmetic and do not change logic.
Sensible Defaults & Quick Tuning
Start with the provided lower bounds and “Top Three” table.
Too many flips → raise the lower bound factor or period.
Too sluggish → lower the bounds or switch to additive mode.
Rankings feel unstable → prefer multiplicative mode and extend the normalization window.
Visuals too strong → increase gradient transparency or disable wick coloring.
What this indicator is—and isn’t
This is a parameter-sweep and visualization layer for SuperTrend selection. It is not a complete trading system, not predictive, and does not include position sizing, transaction costs, or risk management. Combine with market structure, higher-timeframe context, and explicit risk controls.
Attribution and refactor note: The original work is by KioseffTrading. The script has been refactored from approximately two thousand three hundred seventy-one lines to about three hundred eighty core lines, retaining behavior without compiler errors. The general simplification pattern is reusable for other indicators.
Metadata
Name/Tag: SuperTrend Optimizer Remastered
Pine version: v6
Overlay or separate pane: true (overlay)
Core idea/principle: Grid-based SuperTrend selection by cumulative flip returns with additive or multiplicative aggregation.
Primary outputs/signals: Auto-selected SuperTrend up and down lines, optional override lines, gradient bar and wick colors, “Long” labels, performance table.
Inputs with defaults: See Parameter Guide above.
Metrics/functions used: SuperTrend, ATR, arrays, barstate checks, windowed normalization, gamma-based contrast adjustment, table API, gradient utilities.
Special techniques: Fixed grid sweep, compounding vs linear aggregation, last-bar UI updates, gradient encoding of persistence.
Performance/constraints: One hundred and two SuperTrend calls, arrays of length one hundred and two, label budget, last-bar table updates, no higher-timeframe requests.
Recommended use-cases/workflows: Trend bias selection, quick parameter audits, override standardization across assets.
Compatibility/assets/timeframes: Standard OHLC charts across intraday to daily; liquid instruments recommended.
Limitations/risks: Costs and slippage omitted; mid-bar instability possible; not suitable for synthetic chart types.
Debug/diagnostics: Ranking table, optional tested-range label; internal counters for consecutive trends.
Disclaimer
The content provided, including all code and materials, is strictly for educational and informational purposes only. It is not intended as, and should not be interpreted as, financial advice, a recommendation to buy or sell any financial instrument, or an offer of any financial product or service. All strategies, tools, and examples discussed are provided for illustrative purposes to demonstrate coding techniques and the functionality of Pine Script within a trading context.
Any results from strategies or tools provided are hypothetical, and past performance is not indicative of future results. Trading and investing involve high risk, including the potential loss of principal, and may not be suitable for all individuals. Before making any trading decisions, please consult with a qualified financial professional to understand the risks involved.
By using this script, you acknowledge and agree that any trading decisions are made solely at your discretion and risk.
Do not use this indicator on Heikin-Ashi, Renko, Kagi, Point-and-Figure, or Range charts, as these chart types can produce unrealistic results for signal markers and alerts.
Best regards and happy trading
Chervolino

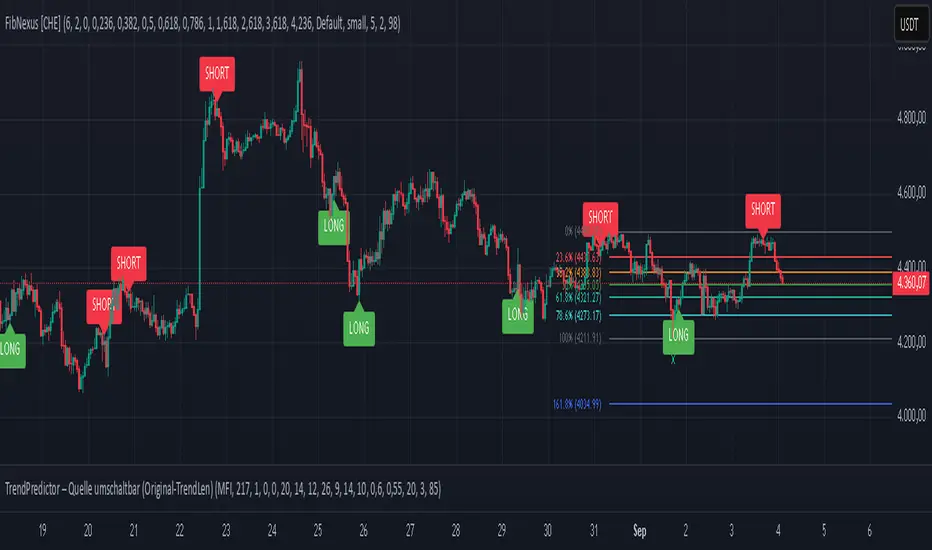
FibNexus [CHE]FibNexus — Auto-Fibonacci with Adaptive TrendLen + TFRSI Triggers
What it is.
FibNexus is a chart overlay that auto-anchors Fibonacci levels to the most relevant swing range without any manual timeframe picking. It does this by computing an adaptive trend length (“TrendLen”) from recent price behavior, then drawing retracements/extensions from the detected swing High/Low. A built-in TFRSI module adds LONG/SHORT triggers and ready-made alerts.
What makes FibNexus different (the TrendLen edge)
Most Fibonacci tools either (a) use fixed lookbacks or (b) force you to choose a higher reference timeframe (or a multiplier of it) and then place Fibs on those higher-TF swings. Your earlier Ultimate Fibonacci Trading Tool \ follows that higher-reference approach (auto TF, multiplier, or manual) and emphasizes custom level/label options. ( )
FibNexus flips that workflow:
* It doesn’t rely on a higher timeframe or a static lookback.
* Instead, it measures multiple window lengths inside the current chart timeframe and selects the one that best fits the data right now.
* From that data-driven window, it automatically finds the most recent swing high & low and draws the entire Fib stack from there.
* When the statistically “best” window changes, anchors update once, labels refresh cleanly, and then lines just extend to the right on each new bar.
Result: No more guesswork about “which timeframe or lookback should I use?”—FibNexus adapts the anchors to market conditions and keeps the drawing noise low.
How TrendLen works (transparent, deterministic)
1. Scan windows: The script evaluates a series of lookbacks (10, 20, …, 500 bars).
2. Score by correlation: For each window, it computes the correlation between price and its lagged version and picks the window with the highest correlation (the strongest, most self-consistent trend segment).
3. Anchor the swing: On a confirmed bar and only when TrendLen changes, it scans the last `TrendLen` bars to capture the highest high and lowest low and marks them with “X”.
4. Draw once, extend later: It deletes the old Fib objects, redraws the active levels from those anchors, and from then on extends the lines to the right as new bars print (no redraw spam).
This makes FibNexus responsive (it adapts when the structure shifts) and quiet (it doesn’t constantly repaint Fibs).
Fibonacci engine (levels, labels, direction)
* Retracements: 0.000 · 0.236 · 0.382 · 0.500 · 0.618 · 0.786 · 1.000
* Extensions: 1.618 · 2.618 · 3.618 · 4.236
* Label styles: *Default* (percent + price), *None*, *Percentage*, *Price*
* Label sizing: *tiny → huge*
* Bull/Bear context: Direction is inferred from mid-range positioning; prices are projected accordingly (retracement vs. extension math is handled for both cases).
* Selective toggles: You can show/hide any level and color it independently.
Momentum & signals (TFRSI module)
FibNexus embeds your TFRSI (“The Forbidden RSI \ ”) as the momentum/trigger layer. TFRSI is your open-source oscillator published on TradingView and designed for fast, normalized momentum readouts with customizable length/smoothing. ( )
* Defaults: `TFRSI length = 6`, `signal smoothing = 2`
* Triggers:
* LONG when TFRSI crosses up through the Long level (default 2.0)
* SHORT when TFRSI crosses down through the Short level (default 98.0)
* On-chart labels: Green LONG under the bar, red SHORT above the bar.
* Spam control: Keep only the N most recent labels to avoid clutter.
* Confirmed bars only: Signals/labels finalize at bar close to reduce flicker.
Alerts (ready for TradingView)
* LONG signal (TFRSI crossover)
* SHORT signal (TFRSI crossunder)
* TrendLen changed (anchors/Fibs recalculated)
* Price crossed a Fib level (any active level)
Use the provided `alertcondition(...)` entries in the TV dialog. Optionally enable instant `alert()` calls with verbose text (avoid duplicates if you also add alertconditions).
Typical use-cases & playbook
* Level reaction trading: In trends, watch 0.382 / 0.5 / 0.618 for reaction. A TFRSI up-cross near a retracement in an uptrend is a straightforward continuation setup; the opposite applies in downtrends.
* Breakout objectives: After clearing the 1.000 line (old swing), 1.618 is a common first extension target; beyond that, 2.618/3.618/4.236 map stretch objectives.
* Chop control: In range conditions, keep signals conservative (e.g., stick with the tight defaults 2.0/98.0 or raise thresholds). Always seek confluence (candlesticks, volume, HTF bias).
* Less micromanagement: You don’t need to babysit timeframe selection or anchors—TrendLen recomputes only when the data say so.
Inputs (by group)
* Core: TFRSI length & smoothing.
* Fibonacci Levels: Per-level toggles, numeric values, colors.
* Fibonacci Labels: Style (percentage/price/both/none) and size.
* Signals: Max number of visible LONG/SHORT labels (or 0 = off).
* TFRSI Trigger: Long/Short thresholds (defaults 2.0 / 98.0).
* Alerts: Master enable, per-event toggles, optional instant `alert()`.
Performance & UX
* Overlay indicator; efficient object handling.
* Clean redraw policy: Full re-draw only when TrendLen changes; otherwise Fibs extend horizontally.
* Clarity: Auto-marked swing anchors (“X”), configurable labels/colors.
Credits & references
* TFRSI – “The Forbidden RSI \ ” (open-source publication and description on TradingView). Used here as the momentum basis.
* “Ultimate Fibonacci Trading Tool \ ” (your earlier open-source tool on TradingView). Focuses on higher-reference timeframe selection (auto/multiplier/manual) and rich labeling controls; FibNexus replaces the fixed/higher-TF anchor logic with adaptive TrendLen in the current timeframe.
Risk disclaimer
This indicator is for educational/information purposes only and is not financial advice. No performance guarantees; past behavior does not predict future results. Trading involves substantial risk (including total loss). Always do your own research, test on demo, use risk management, and consult a licensed advisor where appropriate. Use at your own risk.
Disclaimer:
The content provided, including all code and materials, is strictly for educational and informational purposes only. It is not intended as, and should not be interpreted as, financial advice, a recommendation to buy or sell any financial instrument, or an offer of any financial product or service. All strategies, tools, and examples discussed are provided for illustrative purposes to demonstrate coding techniques and the functionality of Pine Script within a trading context.
Any results from strategies or tools provided are hypothetical, and past performance is not indicative of future results. Trading and investing involve high risk, including the potential loss of principal, and may not be suitable for all individuals. Before making any trading decisions, please consult with a qualified financial professional to understand the risks involved.
By using this script, you acknowledge and agree that any trading decisions are made solely at your discretion and risk.
Enhance your trading precision and confidence with FibNexus ! 🚀
Happy trading
Chervolino
ArraysAssorted🟩 OVERVIEW
This library provides utility methods for working with arrays in Pine Script. The first method finds extreme values (highest/lowest) within a rolling lookback window and returns both the value and its position. I might extend the library for other ad-hoc methods I use to work with arrays.
🟩 HOW TO USE
Pine Script libraries contain reusable code for importing into indicators. You do not need to copy any code out of here. Just import the library and call the method you want.
For example, for version 1 of this library, import it like this:
import SimpleCryptoLife/ArraysAssorted/1
See the EXAMPLE USAGE sections within the library for examples of calling the methods.
You do not need permission to use Pine libraries in your open-source scripts.
However, you do need explicit permission to reuse code from a Pine Script library’s functions in a public protected or invite-only publication .
In any case, credit the author in your description. It is also good form to credit in open-source comments.
For more information on libraries and incorporating them into your scripts, see the Libraries section of the Pine Script User Manual.
🟩 METHOD 1: m_getHighestLowestFloat()
Finds the highest or lowest float value from an array. Simple enough. It also returns the index of the value as an offset from the end of the array.
• It works with rolling lookback windows, so you can find extremes within the last N elements
• It includes an offset parameter to skip recent elements if needed
• It handles edge cases like empty arrays and invalid ranges gracefully
• It can find either the first or last occurrence of the extreme value
We also export two enums whose sole purpose is to look pretty as method arguments.
method m_getHighestLowestFloat(_self, _highestLowest, _lookbackBars, _offset, _firstLastType)
Namespace types: array
This method finds the highest or lowest value in a float array within a rolling lookback window, and returns the value along with the offset (number of elements back from the end of the array) of its first or last occurrence.
Parameters:
_self (array) : The array of float values to search for extremes.
_highestLowest (HighestLowest) : Whether to search for the highest or lowest value. Use the enum value HighestLowest.highest or HighestLowest.lowest.
_lookbackBars (int) : The number of array elements to include in the rolling lookback window. Must be positive. Note: Array elements only correspond to bars if the consuming script always adds exactly one element on consecutive bars.
_offset (int) : The number of array elements back from the end of the array to start the lookback window. A value of zero means no offset. The _offset parameter offsets both the beginning and end of the range.
_firstLastType (FirstLast) : Whether to return the offset of the first (lowest index) or last (highest index) occurrence of the extreme value. Use FirstLast.first or FirstLast.last.
Returns: (tuple) A tuple containing the highest or lowest value and its offset -- the number of elements back from the end of the array. If not found, returns . NOTE: The _offsetFromEndOfArray value is not affected by the _offset parameter. In other words, it is not the offset from the end of the range but from the end of the array. This number may or may not have any relation to the number of *bars* back, depending on how the array is populated. The calling code needs to figure that out.
EXPORTED ENUMS
HighestLowest
Whether to return the highest value or lowest value in the range.
• highest : Find the highest value in the specified range
• lowest : Find the lowest value in the specified range
FirstLast
Whether to return the first (lowest index) or last (highest index) occurrence of the extreme value.
• first : Return the offset of the first occurrence of the extreme value
• last : Return the offset of the last occurrence of the extreme value
REVELATIONS (VoVix - PoC) REVELATIONS (VoVix - POC): True Regime Detection Before the Move
Let’s not sugarcoat it: Most strategies on TradingView are recycled—RSI, MACD, OBV, CCI, Stochastics. They all lag. No matter how many overlays you stack, every one of these “standard” indicators fires after the move is underway. The retail crowd almost always gets in late. That’s never been enough for my team, for DAFE, or for anyone who’s traded enough to know the real edge vanishes by the time the masses react.
How is this different?
REVELATIONS (VoVix - POC) was engineered from raw principle, structured to detect pre-move regime change—before standard technicals even light up. We built, tested, and refined VoVix to answer one hard question:
What if you could see the spike before the trend?
Here’s what sets this system apart, line-by-line:
o True volatility-of-volatility mathematics: It’s not just "ATR of ATR" or noise smoothing. VoVix uses normalized, multi-timeframe v-vol spikes, instantly detecting orderbook stress and "outlier" market events—before the chart shows them as trends.
o Purist regime clustering: Every trade is enabled only during coordinated, multi-filter regime stress. No more signals in meaningless chop.
o Nonlinear entry logic: No trade is ever sent just for a “good enough” condition. Every entry fires only if every requirement is aligned—local extremes, super-spike threshold, regime index, higher timeframe, all must trigger in sync.
o Adaptive position size: Your contracts scale up with event strength. Tiny size during nominal moves, max leverage during true regime breaks—never guesswork, never static exposure.
o All exits governed by regime decay logic: Trades are closed not just on price targets but at the precise moment the market regime exhausts—the hardest part of systemic trading, now solved.
How this destroys the lag:
Standard indicators (RSI, MACD, OBV, CCI, and even most “momentum” overlays) simply tell you what already happened. VoVix triggers as price structure transitions—anyone running these generic scripts will trade behind the move while VoVix gets in as stress emerges. Real alpha comes from anticipation, not confirmation.
The visuals only show what matters:
Top right, you get a live, live quant dashboard—regime index, current position size, real-time performance (Sharpe, Sortino, win rate, and wins). Bottom right: a VoVix "engine bar" that adapts live with regime stress. Everything you see is a direct function of logic driving this edge—no cosmetics, no fake momentum.
Inputs/Signals—explained carefully for clarity:
o ATR Fast Length & ATR Slow Length:
These are the heart of VoVix’s regime sensing. Fast ATR reacts to sharp volatility; Slow ATR is stability baseline. Lower Fast = reacts to every twitch; higher Slow = requires more persistent, “real” regime shifts.
Tip: If you want more signals or faster markets, lower ATR Fast. To eliminate noise, raise ATR Slow.
o ATR StdDev Window: Smoothing for volatility-of-volatility normalization. Lower = more jumpy, higher = only the cleanest spikes trigger.
Tip: Shorten for “jumpy” assets, raise for indices/futures.
o Base Spike Threshold: Think of this as your “minimum event strength.” If the current move isn’t volatile enough (normalized), no signal.
Tip: Higher = only biggest moves matter. Lower for more signals but more potential noise.
o Super Spike Multiplier: The “are you sure?” test—entry only when the current spike is this multiple above local average.
Tip: Raise for ultra-selective/swing-trading; lower for more active style.
Regime & MultiTF:
o Regime Window (Bars):
How many bars to scan for regime cluster “events.” Short for turbo markets, long for big swings/trends only.
o Regime Event Count: Only trade when this many spikes occur within the Regime Window—filters for real stress, not isolated ticks.
Tip: Raise to only ever trade during true breakouts/crashes.
o Local Window for Extremes:
How many bars to check that a spike is a local max.
Tip: Raise to demand only true, “clearest” local regime events; lower for early triggers.
o HTF Confirm:
Higher timeframe regime confirmation (like 45m on an intraday chart). Ensures any event you act on is visible in the broader context.
Tip: Use higher timeframes for only major moves; lower for scalping or fast regimes.
Adaptive Sizing:
o Max Contracts (Adaptive): The largest size your system will ever scale to, even on extreme event.
Tip: Lower for small accounts/conservative risk; raise on big accounts or when you're willing to go big only on outlier events.
o Min Contracts (Adaptive): The “toe-in-the-water.” Smallest possible trade.
Tip: Set as low as your broker/exchange allows for safety, or higher if you want to always have meaningful skin in the game.
Trade Management:
o Stop %: Tightness of your stop-loss relative to entry. Lower for tighter/safer, higher for more breathing room at cost of greater drawdown.
o Take Profit %: How much you'll hold out for on a win. Lower = more scalps. Higher = only run with the best.
o Decay Exit Sensitivity Buffer: Regime index must dip this far below the trading threshold before you exit for “regime decay.”
Tip: 0 = exit as soon as stress fails, higher = exits only on stronger confirmation regime is over.
o Bars Decay Must Persist to Exit: How long must decay be present before system closes—set higher to avoid quick fades and whipsaws.
Backtest Settings
Initial capital: $10,000
Commission: Conservative, realistic roundtrip cost:
15–20 per contract (including slippage per side) I set this to $25
Slippage: 3 ticks per trade
Symbol: CME_MINI:NQ1!
Timeframe: 1 min (but works on all timeframes)
Order size: Adaptive, 1–3 contracts
No pyramiding, no hidden DCA
Why these settings?
These settings are intentionally strict and realistic, reflecting the true costs and risks of live trading. The 10,000 account size is accessible for most retail traders. 25/contract including 3 ticks of slippage are on the high side for NQ, ensuring the strategy is not curve-fit to perfect fills. If it works here, it will work in real conditions.
Tip: Set to 1 for instant regime exit; raise for extra confirmation (less whipsaw risk, exits held longer).
________________________________________
Bottom line: Tune the sensitivity, selectivity, and risk of REVELATIONS by these inputs. Raise thresholds and windows for only the best, most powerful signals (institutional style); lower for activity (scalpers, fast cryptos, signals in constant motion). Sizing is always adaptive—never static or martingale. Exits are always based on both price and regime health. Every input is there for your control, not to sell “complexity.” Use with discipline, and make it your own.
This strategy is not just a technical achievement: It’s a statement about trading smarter, not just more.
* I went back through the code to make sure no the strategy would not suffer from repainting, forward looking, or any frowned upon loopholes.
Disclaimer:
Trading is risky and carries the risk of substantial loss. Do not use funds you aren’t prepared to lose. This is for research and informational purposes only, not financial advice. Backtest, paper trade, and know your risk before going live. Past performance is not a guarantee of future results.
Expect more: We’ll keep pushing the standard, keep evolving the bar until “quant” actually means something in the public code space.
Use with clarity, use with discipline, and always trade your edge.
— Dskyz , for DAFE Trading Systems

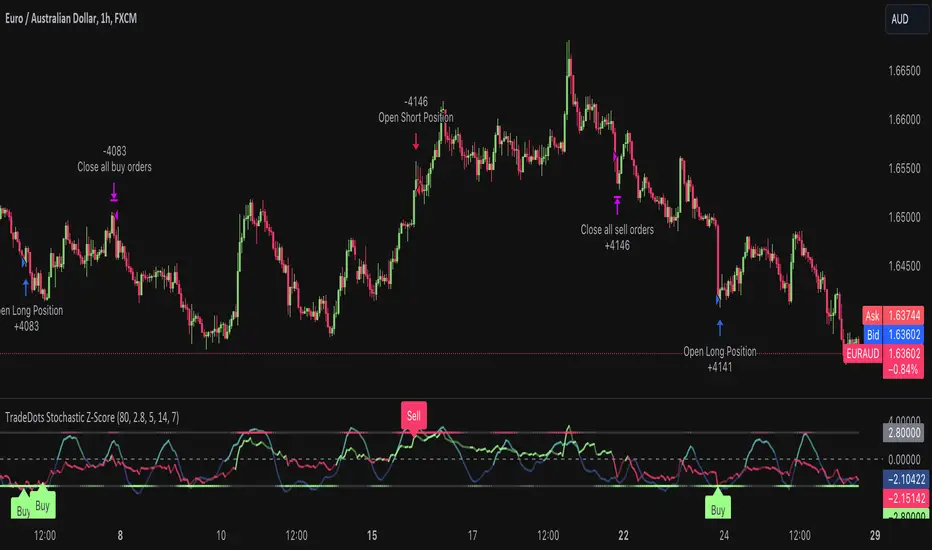
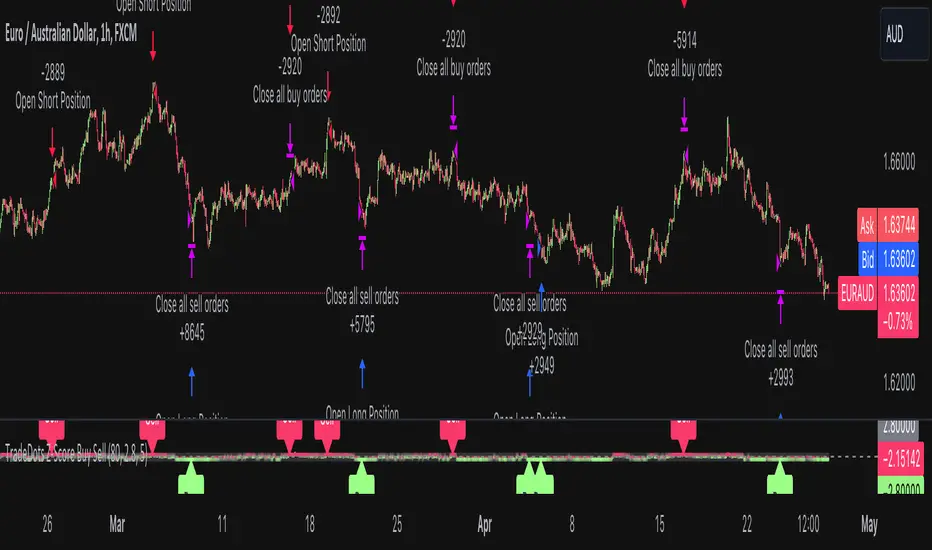
Stochastic Z-Score Oscillator Strategy [TradeDots]The "Stochastic Z-Score Oscillator Strategy" represents an enhanced approach to the original "Buy Sell Strategy With Z-Score" trading strategy. Our upgraded Stochastic model incorporates an additional Stochastic Oscillator layer on top of the Z-Score statistical metrics, which bolsters the affirmation of potential price reversals.
We also revised our exit strategy to when the Z-Score revert to a level of zero. This amendment gives a much smaller drawdown, resulting in a better win-rate compared to the original version.
HOW DOES IT WORK
The strategy operates by calculating the Z-Score of the closing price for each candlestick. This allows us to evaluate how significantly the current price deviates from its typical volatility level.
The strategy first takes the scope of a rolling window, adjusted to the user's preference. This window is used to compute both the standard deviation and mean value. With these values, the strategic model finalizes the Z-Score. This determination is accomplished by subtracting the mean from the closing price and dividing the resulting value by the standard deviation.
Following this, the Stochastic Oscillator is utilized to affirm the Z-Score overbought and oversold indicators. This indicator operates within a 0 to 100 range, so a base adjustment to match the Z-Score scale is required. Post Stochastic Oscillator calculation, we recalibrate the figure to lie within the -4 to 4 range.
Finally, we compute the average of both the Stochastic Oscillator and Z-Score, signaling overpriced or underpriced conditions when the set threshold of positive or negative is breached.
APPLICATION
Firstly, it is better to identify a stable trading pair for this technique, such as two stocks with considerable correlation. This is to ensure conformance with the statistical model's assumption of a normal Gaussian distribution model. The ideal performance is theoretically situated within a sideways market devoid of skewness.
Following pair selection, the user should refine the span of the rolling window. A broader window smoothens the mean, more accurately capturing long-term market trends, while potentially enhancing volatility. This refinement results in fewer, yet precise trading signals.
Finally, the user must settle on an optimal Z-Score threshold, which essentially dictates the timing for buy/sell actions when the Z-Score exceeds with thresholds. A positive threshold signifies the price veering away from its mean, triggering a sell signal. Conversely, a negative threshold denotes the price falling below its mean, illustrating an underpriced condition that prompts a buy signal.
Within a normal distribution, a Z-Score of 1 records about 68% of occurrences centered at the mean, while a Z-Score of 2 captures approximately 95% of occurrences.
The 'cool down period' is essentially the number of bars that await before the next signal generation. This feature is employed to dodge the occurrence of multiple signals in a short period.
DEFAULT SETUP
The following is the default setup on EURAUD 1h timeframe
Rolling Window: 80
Z-Score Threshold: 2.8
Signal Cool Down Period: 5
Stochastic Length: 14
Stochastic Smooth Period: 7
Commission: 0.01%
Initial Capital: $10,000
Equity per Trade: 40%
FURTHER IMPLICATION
The Stochastic Oscillator imparts minimal impact on the current strategy. As such, it may be beneficial to adjust the weightings between the Z-Score and Stochastic Oscillator values or the scale of Stochastic Oscillator to test different performance outcomes.
Alternative momentum indicators such as Keltner Channels or RSI could also serve as robust confirmations of overbought and oversold signals when used for verification.
RISK DISCLAIMER
Trading entails substantial risk, and most day traders incur losses. All content, tools, scripts, articles, and education provided by TradeDots serve purely informational and educational purposes. Past performances are not definitive predictors of future results.
Buy Sell Strategy With Z-Score [TradeDots]The "Buy Sell Strategy With Z-Score" is a trading strategy that harnesses Z-Score statistical metrics to identify potential pricing reversals, for opportunistic buying and selling opportunities.
HOW DOES IT WORK
The strategy operates by calculating the Z-Score of the closing price for each candlestick. This allows us to evaluate how significantly the current price deviates from its typical volatility level.
The strategy first takes the scope of a rolling window, adjusted to the user's preference. This window is used to compute both the standard deviation and mean value. With these values, the strategic model finalizes the Z-Score. This determination is accomplished by subtracting the mean from the closing price and dividing the resulting value by the standard deviation.
This approach provides an estimation of the price's departure from its traditional trajectory, thereby identifying market conditions conducive to an asset being overpriced or underpriced.
APPLICATION
Firstly, it is better to identify a stable trading pair for this technique, such as two stocks with considerable correlation. This is to ensure conformance with the statistical model's assumption of a normal Gaussian distribution model. The ideal performance is theoretically situated within a sideways market devoid of skewness.
Following pair selection, the user should refine the span of the rolling window. A broader window smoothens the mean, more accurately capturing long-term market trends, while potentially enhancing volatility. This refinement results in fewer, yet precise trading signals.
Finally, the user must settle on an optimal Z-Score threshold, which essentially dictates the timing for buy/sell actions when the Z-Score exceeds with thresholds. A positive threshold signifies the price veering away from its mean, triggering a sell signal. Conversely, a negative threshold denotes the price falling below its mean, illustrating an underpriced condition that prompts a buy signal.
Within a normal distribution, a Z-Score of 1 records about 68% of occurrences centered at the mean, while a Z-Score of 2 captures approximately 95% of occurrences.
The 'cool down period' is essentially the number of bars that await before the next signal generation. This feature is employed to dodge the occurrence of multiple signals in a short period.
DEFAULT SETUP
The following is the default setup on EURUSD 1h timeframe
Rolling Window: 80
Z-Score Threshold: 2.8
Signal Cool Down Period: 5
Commission: 0.03%
Initial Capital: $10,000
Equity per Trade: 30%
RISK DISCLAIMER
Trading entails substantial risk, and most day traders incur losses. All content, tools, scripts, articles, and education provided by TradeDots serve purely informational and educational purposes. Past performances are not definitive predictors of future results.
Multi-Distribution Volume Profile (Zeiierman)█ Overview
Multi-Distribution Volume Profile (Zeiierman) is a flexible, structure-first volume profile tool that lets you reshape how volume is distributed across price, from classic uniform profiles to advanced statistical curves like Gaussian, Lognormal, Student-t, and more.
Instead of forcing every market into a single "one-size-fits-all" profile, this tool lets you model how volume is likely concentrated inside each bar (body vs wicks, midpoint, tails, center bias, right-skew, heavy tails, etc.) and then stacks that behavior across a whole lookback window to build a rich, multi-distribution map of traded activity.
On top of that, it overlays a dynamic Center Band (value area) and a fade/gradient model that can color each price row by volume, hits, recency, volatility, reversals, or even liquidity voids, turning a plain profile into a multi-dimensional context map.
Highlights
Choose from multiple Profile Build Modes , including uniform, body-only, wick-only, midpoint/close/open, center-weighted, and a suite of probability-style distributions (Gaussian, Lognormal, Weibull, Student-t, etc.)
Flexible anchor layout: draw the profile on Right/Left (horizontal) or Bottom/Top (vertical) to fit any chart layout
Value Area / Center Band computed from volume quantiles around the POC.
Gradient-based Fade Metrics: volume, price hits, freshness (time decay), volatility impact, dwell time, reversal density, compression, and liquidity voids
Separate bullish vs bearish volume at each price row for directional structure insights
█ How It Works
⚪ Profile Construction
The script scans a user-defined Bars Included window and finds the full high–low span of that zone. It then divides this range into a user-controlled number of Price Levels (rows).
For each historical bar within the window:
It measures the candle’s price range, body, and wicks.
It assigns volume to rows according to the selected Profile Build Mode, for example:
* Range Uniform – volume spread evenly across the full high–low range.
* Range Body Only / Range Wick Only – concentrate volume inside the body or wicks only.
* Midpoint / Close / Open Only – allocate volume entirely into one price row (pinpoint modeling).
HL2 / Body Center Weighted – center weights around the middle of the range/body.
Recent-Weighted Volume – amplify newer bars using exponential time decay.
Volume Squared (Hard) – aggressively boost bars with large volume.
Up Bars Only / Down Bars Only – filter volume to only bullish or bearish bars.
For more advanced shapes, the script uses continuous distributions across the bar’s span:
Linear, Triangular, Exponential to High
Cosine Centered, PERT
Gaussian, Lognormal, Cauchy, Laplace
Pareto, Weibull, Logistic, Gumbel
Gamma, Beta, Chi-Square, Student-t, F-Shape
Each distribution produces a weight for each row within the bar’s range, normalized so the total volume remains consistent, but the shape of where that volume lands changes.
⚪ POC & Center Band (Value Area)
Once all rows are accumulated:
The row with the highest total volume becomes the Point of Control (POC)
The script computes cumulative volume and finds the band that wraps a user-defined Center of Profile % (e.g., 68%) around the center of distribution.
This range is displayed as a central band, often treated like a value area where price has spent the most “effort” trading.
⚪ Gradient Fade Engine
Each row also gets a fade metric, chosen in Fade Metric:
Volume – opacity based on relative volume.
Price Hits – how frequently that row was touched.
Blended (Vol+Hits) – average of volume & hits.
Freshness – emphasizes recent activity, controlled by Decay.
Volatility Impact – rows that saw larger ranges contribute more.
Dwell Time – where price “camped” the longest.
Reversal Density – where direction changes cluster.
Compression – tight-range compression zones.
Liquidity Void – inverse of volume (thin liquidity zones).
When Apply Gradient is enabled, the row’s bullish/bearish colors are tinted from faint to strong based on this chosen metric, effectively turning the profile into a heatmap of your chosen structural property.
█ How to Use
⚪ Explore Different Distribution Assumptions
Switch between multiple Profile Build Modes to see how your assumptions about intrabar volume affect structure:
Use Range Uniform for classical profile reading.
Deploy Gaussian, Logistic, or Cosine shapes to emphasize central clustering.
Try Pareto, Lognormal, or F-Shape to focus on tail / extremal activity.
Use Recent-Weighted Volume to prioritize the most recent structural behavior.
This is especially useful for traders who want to test how different modeling assumptions change perceived value areas and levels of interest.
⚪ Identify Value, Acceptance & Rejection Zones
Use the POC and Center of Profile (%) band to distinguish:
High-acceptance zones – wide central band, thick rows, strong gradient → fair value areas
Rejection zones & tails – thin extremes, low dwell time, high volatility or reversal density
These regions can be used as:
Targets and origin zones for mean reversion
Context for breakout validation (leaving value)
Bias reference for intraday rotations or swing rotations
⚪ Read Directional Structure Within the Profile
Because each row is split into bullish vs bearish contributions, you can visually read:
Where buyers dominated a price region (large bullish slice)
Where sellers absorbed or defended (large bearish slice)
Combining this with Fade Metrics like Reversal Density, Dwell Time, or Freshness turns the profile into a structural order-flow map, without needing raw tick-by-tick volume data.
⚪ Use Fade Metrics for Contextual Heatmaps
Each Fade Metric can be used for a different analytical lens:
Volume / Blended – emphasize where volume and activity are concentrated.
Freshness – highlight the most recently active zones that still matter.
Volatility Impact & Compression – spot areas of explosive moves vs coiled ranges.
Reversal Density – locate micro turning points and battle zones.
Liquidity Void – visually pop out thin regions that may act as speedways or magnets.
█ Settings
Profile Build Mode – Selects how each bar’s volume is distributed across its price range (uniform, body/wick, midpoint/close/open, center-weighted, or statistical distribution families).
Bars Included – Number of bars used to build the profile from the current bar backward.
Price Levels – Vertical resolution of the profile: more levels = smoother but heavier.
Anchor Side – Where the profile is drawn on the chart: Right, Left, Bottom, or Top.
Offset (bars) – Horizontal offset from the last bar to the profile when using Right/Left modes.
Apply Gradient – Toggles the fade/heatmap coloring based on the selected metric.
Fade Metric – Chooses the property driving row opacity (Volume, Hits, Freshness, Volatility Impact, Dwell Time, Reversal Density, Compression, Liquidity Void).
Decay – Time-decay factor for Freshness (values close to 1 keep older activity relevant for longer).
Profile Thickness – Relative thickness of the profile along the time axis, as a % of the lookback window.
Center of Profile (%) – Volume percentage used to define the central band (value area) around the POC.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

Macro Range HighlighterThis Pine Script indicator creates visual boxes that highlight specific time-based price ranges throughout the trading day, operating in New York Eastern Time. It offers two distinct modes: a standard hourly range mode and a classic ICT (Inner Circle Trader) Macro mode.
Two Operating Modes
Mode 1: Standard Hourly 50-09 Ranges (Default)
This mode identifies and highlights the price range during the final 10 minutes of each hour (xx:50) through the first 9 minutes of the next hour (xx:09).
Examples of captured ranges:
08:50 - 09:09
09:50 - 10:09
10:50 - 11:09
11:50 - 12:09
12:50 - 13:09
13:50 - 14:09
14:50 - 15:09
And continues for each hour...
Excluded Time Periods:
The indicator excludes certain periods that cross into or occur during market close and the daily reset:
02:50 - 03:09 (excluded to avoid interference with overnight session)
15:50 - 18:09 (excluded to avoid end-of-regular-hours and the 18:00 ET trading day reset)
This means you will NOT see boxes during the 16:00 or 17:00 hours, as these fall within the excluded window.
Mode 2: Classic ICT Macro Times
When enabled, this mode shows ONLY four specific time windows that are significant in ICT methodology:
02:33 - 02:59 (London Midnight Macro)
04:03 - 04:29 (London Open Macro)
13:10 - 13:39 (New York Lunch Macro)
15:15 - 15:44 (New York Close Macro)
When this mode is active, all standard hourly ranges are disabled, including the 02:50-03:09 range.
Green Line - Open Price
Represents the open price of the first candle when the range begins
This line is static once set - it shows where price opened when entering the time window
Extends horizontally across the entire duration of the box
Example: If the range starts at 08:50 and that candle opens at 18,500, the green line will be drawn at 18,500
Blue Line - Evolving Midpoint
Represents the dynamic midpoint between the range high and range low
This line continuously recalculates as new highs or lows are made within the time window
Calculation: Midpoint = (Range High + Range Low) / 2
Evolution example:
At 08:50, range is 18,480 (low) to 18,520 (high), midpoint = 18,500
At 08:55, price makes new high of 18,540, midpoint updates to 18,510
At 09:02, price makes new low of 18,470, midpoint updates to 18,505
The line visually adjusts up and down as the range expands
Extension: The line extends horizontally from the start of the range to the current bar (or end of range)
This gives traders a visual reference for the "fair value" or equilibrium point of the range
Red Line - Close Price
Represents the close price of the most recent candle within the time window
This line updates continuously with each new bar's close price
Extends horizontally across the range
When the range completes (exits the time window), it shows the final close price of the last bar in the range
Example: As price moves from 08:50 to 09:09, the red line will track the close of each candle: 18,505 → 18,510 → 18,508 → 18,515, etc.
This indicator provides a sophisticated visual framework for analyzing specific time-based price behavior. The evolving midpoint (blue line and optional yellow plot) is particularly powerful because it gives you real-time feedback on where the "fair value" of the range is as it develops, allowing you to make informed decisions about whether price is extended or returning to equilibrium. The three-line system (open/mid/close) creates a complete picture of price action within each critical time window, whether you're using standard hourly analysis or focusing on ICT's specific macro times.

Simple Moving Average (SMA)## Overview and Purpose
The Simple Moving Average (SMA) is one of the most fundamental and widely used technical indicators in financial analysis. It calculates the arithmetic mean of a selected range of prices over a specified number of periods. Developed in the early days of technical analysis, the SMA provides traders with a straightforward method to identify trends by smoothing price data and filtering out short-term fluctuations. Due to its simplicity and effectiveness, it remains a cornerstone indicator that forms the basis for numerous other technical analysis tools.
## What’s Different in this Implementation
- **Constant streaming update:**
On each bar we:
1) subtract the value leaving the window,
2) add the new value,
3) divide by the number of valid samples (early) or by `period` (once full).
- **Deterministic lag, same as textbook SMA:**
Once full, lag is `(period - 1)/2` bars—identical to the classic SMA. You just **don’t lose the first `period-1` bars** to `na`.
- **Large windows without penalty:**
Complexity is constant per tick; memory is bounded by `period`. Very long SMAs stay cheap.
## Behavior on Early Bars
- **Bars < period:** returns the arithmetic mean of **available** samples.
Example (period = 10): bar #3 is the average of the first 3 inputs—not `na`.
- **Bars ≥ period:** behaves exactly like standard SMA over a fixed-length window.
> Implication: Crosses and signals can appear earlier than with `ta.sma()` because you’re not suppressing the first `period-1` bars.
## When to Prefer This
- Backtests needing early bars: You want signals and state from the very first bars.
- High-frequency or very long SMAs: O(1) updates avoid per-bar CPU spikes.
- Memory-tight scripts: Single circular buffer; no large temp arrays per tick.
## Caveats & Tips
Backtest comparability: If you previously relied on na gating from ta.sma(), add your own warm-up guard (e.g., only trade after bar_index >= period-1) for apples-to-apples.
Missing data: The function treats the current bar via nz(source); adjust if you need strict NA propagation.
Window semantics: After warm-up, results match the textbook SMA window; early bars are a partial-window mean by design.
## Math Notes
Running-sum update:
sum_t = sum_{t-1} - oldest + newest
SMA_t = sum_t / k where k = min(#valid_samples, period)
Lag (full window): (period - 1) / 2 bars.
## References
- Edwards & Magee, Technical Analysis of Stock Trends
- Murphy, Technical Analysis of the Financial Markets
DayFlow VWAP Relay Forex Majors StrategySummary in one paragraph
DayFlow VWAP Relay is a day-trading strategy for major FX pairs on intraday timeframes, demonstrated on EURUSD 15 minutes. It waits for alignment between a daily anchored VWAP regime check, residual percentiles, and lower-timeframe micro flow before suggesting trades. The originality is the fusion of daily VWAP residual percentiles with a live micro-flow score from 1 minute data to switch between fade and breakout behavior inside the same session. Add it to a clean chart and use the markers and alerts.
Scope and intent
• Markets: Major FX pairs such as EURUSD, GBPUSD, USDJPY, AUDUSD, USDCHF, USDCAD
• Timeframes: One minute to one hour
• Default demo in this publication: EURUSD on 15 minutes
• Purpose: Reduce false starts by acting only when context, location and micro flow agree
• Limits: This is a strategy. Orders are simulated on standard candles only
Originality and usefulness
• Core novelty: Residual percentiles to daily anchored VWAP decide “balanced versus expanding day”. A separate 1 minute micro-flow score confirms direction, so the same model fades extremes in balance and rides range breaks in expansion
• Failure modes addressed: Chop fakeouts and unconfirmed breakouts are filtered by the expansion gate and micro-flow threshold
• Testability: Every input is exposed. Bands, background regime color, and markers show why a suggestion appears
• Portable yardstick: Stops and targets are ATR multiples converted to ticks, which transfer across symbols
• Open source status: No reused third-party code that requires attribution
Method overview in plain language
The day is anchored with a VWAP that updates from the daily session start. Price minus VWAP is the residual. Percentiles of that residual measured over a rolling window define location extremes for the current day. A regime score compares residual volatility to price volatility. When expansion is low, the day is treated as balanced and the model fades residual extremes if 1 minute micro flow points back to VWAP. When expansion is high, the model trades breakouts outside the VWAP bands if slope and micro flow agree with the move.
Base measures
• Range basis: True Range smoothed by ATR for stops and targets, length 14
• Return basis: Not required for signals; residuals are absolute price distance to VWAP
Components
• Daily Anchor VWAP Bands. VWAP with standard-deviation bands. Slope sign is used for trend confirmation on breakouts
• Residual Percentiles. Rolling percentiles of close minus VWAP over Signal length. Identify location extremes inside the day
• Expansion Ratio. Standard deviation of residuals divided by standard deviation of price over Signal length. Classifies balanced versus expanding day
• Micro Flow. Net up minus down closes from 1 minute data across a short span, normalized to −1..+1. Confirms direction and avoids fades against pressure
• Session Window optional. Restricts trading to your configured hours to avoid thin periods
• Cooldown optional. Bars to wait after a position closes to prevent immediate re-entry
Fusion rule
Gating rather than weighting. First choose regime by Expansion Ratio versus the Expansion gate. Inside each regime all listed conditions must be true: location test plus micro-flow threshold plus session window plus cooldown. Breakouts also require VWAP slope alignment.
Signal rule
• Long suggestion on balanced day: residual at or below the lower percentile and micro flow positive above the gate while inside session and cooldown is satisfied
• Short suggestion on balanced day: residual at or above the upper percentile and micro flow negative below the gate while inside session and cooldown is satisfied
• Long suggestion on expanding day: close above the upper VWAP band, VWAP slope positive, micro flow positive, session and cooldown satisfied
• Short suggestion on expanding day: close below the lower VWAP band, VWAP slope negative, micro flow negative, session and cooldown satisfied
• Positions flip on opposite suggestions or exit by brackets
What you will see on the chart
• Markers on suggestion bars: L for long, S for short
• Exit occurs on reverse signal or when a bracket order is filled
• Reference lines: daily anchored VWAP with upper and lower bands
• Optional background: teal for balanced day, orange for expanding day
Inputs with guidance
Setup
• Signal length. Residual and regime window. Typical 40 to 100. Higher smooths, lower reacts faster
Micro Flow
• Micro TF. Lower timeframe used for micro flow, default 1 minute
• Micro span bars. Count of lower-TF bars. Typical 5 to 20
• Micro flow gate 0..1. Minimum absolute flow. Raising it demands stronger confirmation and reduces trade count
VWAP Bands
• VWAP stdev multiplier. Band width. Typical 0.8 to 1.6. Wider bands reduce breakout frequency and increase fade distance
• Expansion gate 0..3. Threshold to switch from fades to breakouts. Raising it favors fades, lowering it favors breakouts
Sessions
• Use session filter. Enable to trade only inside your window
• Trade window UTC. Default 07:00 to 17:00
Risk
• ATR length. Stop and target basis. Typical 10 to 21
• Stop ATR x. Initial stop distance in ATR multiples
• Target ATR x. Profit target distance in ATR multiples
• Cooldown bars after close. Wait bars before a new entry
• Side. Both, long only, or short only
View
• Show VWAP and bands
• Color bars by residual regime
Properties visible in this publication
• Initial capital 10000
• Base currency Default
• request.security uses lookahead off everywhere
• Strategy: Percent of equity with value 3. Pyramiding 0. Commission cash per order 0.0001 USD. Slippage 3 ticks. Process orders on close ON. Bar magnifier ON. Recalculate after order is filled OFF. Calc on every tick OFF. Using standard OHLC fills ON.
Realism and responsible publication
No performance claims. Past results never guarantee future outcomes. Fills and slippage vary by venue. Shapes can move while a bar forms and settle on close. Strategies must run on standard candles for signals and orders.
Honest limitations and failure modes
High impact news, session opens, and thin liquidity can invalidate assumptions. Very quiet days can reduce contrast between residuals and price volatility. Session windows use the chart exchange time. If both stop and target are touched within a single bar, TradingView’s standard OHLC price-movement model decides the outcome.
Expect different behavior on illiquid pairs or during holidays. The model is sensitive to session definitions and feed time. Past results never guarantee future outcomes.
Legal
Education and research only. Not investment advice. You are responsible for your decisions. Test on historical data and in simulation before any live use. Use realistic costs.

FUMO 200 MagnetWhat it does
FUMO Magnet measures how far price has stretched away from its long-term “magnet” — a blended EMA/SMA moving average (200 by default).
It plots a logarithmic deviation (optionally normalized) as an oscillator around zero.
Above 0** → price is above the magnet (stretched up)
Below 0** → price is below the magnet (stretched down)
Guide levels** highlight potential overbought/oversold zones
---
Why log deviation?
Log returns make extremes comparable across cycles and compress exponential trends — especially useful for BTC and other crypto assets.
Normalization modes further adjust the scale, keeping the oscillator readable on any chart.
---
Inputs
**Base**
* Source (default: Close)
* Base Length (default: 200 EMA/SMA)
* EMA vs SMA weight (%) — 0% = pure SMA, 100% = pure EMA, 50% = blended
* EMA smoothing of deviation — acts as a noise filter
**Normalization**
* None (Log Deviation) — raw log stretch in % terms
* Z-score — deviation in standard deviations (σ)
* Robust Z (MAD) — deviation vs median absolute deviation, resistant to outliers
* Tanh squash — smooth nonlinear squash of extremes for compact scale
* Normalization window (for Z / MAD)
* Tanh scale (lower = stronger squash)
* Clamp after normalization — hard cap at ±X
**Levels**
* Guide levels (Upper / Lower) — visual thresholds (default ±12)
* Zero line toggle
---
### How to read it
* **Trend bias**: sustained time above 0 = uptrend, below 0 = downtrend
* **Stretch / mean reversion**: the farther from 0, the higher the reversion risk
* **Cross-checks**: combine with structure (HH/HL, LH/LL), volume, or momentum (RSI, MACD)
---
### Recommended settings by timeframe
**Long-term (1D / 1W)**
* Normalization: None (Log Deviation)
* Base Length: 200
* EMA vs SMA weight: 50% (adjust 35–65% for faster/slower magnet)
* Deviation smoothing: 20 (10–30 range)
* Guide levels: ±12 to ±20
* Use case: cycle extremes, portfolio rebalancing, trim/add logic
**Swing (4H – 1D)**
* Normalization: Z-score
* Window: 200 (100–250)
* Smoothing: 14–20
* Guide levels: ±2σ to ±3σ
* Use case: stretched conditions across regimes; ±3σ is rare, often mean-reverts
**Intraday / Active swing (1H – 4H)**
* Normalization: Robust Z (MAD)
* Window: 200 (150 for faster response)
* Smoothing: 10–16
* Guide levels: ±3 to ±4 (robust units)
* Use case: handles spikes better than σ, fewer false overbought/oversold signals
**Scalping / Universal readability (15m – 1H)**
* Normalization: Tanh squash
* Tanh scale: 6–10 (start with 8)
* Smoothing: 8–12
* Guide levels: ±8 to ±12
* Use case: compact panel across assets and timeframes; not % or σ, but visually consistent
---
### Optional
* Clamp: enable ±20 (or ±25) for strict bounded range (useful for public charts)
---
### Quick setups
**BTC Daily (“cycle view”)**
* Normalization: None
* Blend: 50%
* Smooth: 20
* Levels: ±12–15
**BTC 4H (“swing”)**
* Normalization: Z-score
* Window: 200
* Smooth: 16
* Levels: ±2.5σ to ±3σ
**Alts 1H (“volatile”)**
* Normalization: Robust Z (MAD)
* Window: 200
* Smooth: 12
* Levels: ±3.5 to ±4.5
**Mixed assets 15m (“compact panel”)**
* Normalization: Tanh squash
* Scale: 8
* Smooth: 10
* Levels: ±8–12
* Clamp: ±20
C&B Auto MK5C&B Auto MK5.2ema BullBear
Overview
The C&B Auto MK5.2ema BullBear is a versatile Pine Script indicator designed to help traders identify bullish and bearish market conditions across various timeframes. It combines Exponential Moving Averages (EMAs), Relative Strength Index (RSI), Average True Range (ATR), and customizable time filters to generate actionable signals. The indicator overlays on the price chart, displaying EMAs, a dynamic cloud, scaled RSI levels, bull/bear signals, and market condition labels, making it suitable for swing trading, day trading, or scalping in trending or volatile markets.
What It Does
This indicator generates bull and bear signals based on the interaction of two EMAs, filtered by RSI thresholds, ATR-based volatility, a 50/200 EMA trend filter, and user-defined time windows. It adapts to market volatility by adjusting EMA lengths and RSI thresholds. A dynamic cloud highlights trend direction or neutral zones, with candlestick coloring in neutral conditions. Market condition labels (current and historical) provide real-time trend and volatility context, displayed above the chart.
How It Works
The indicator uses the following components:
EMAs: Two EMAs (short and long) are calculated on a user-selected timeframe (1, 5, 15, 30, or 60 minutes). Their crossover or crossunder triggers potential bull/bear signals. EMA lengths adjust based on volatility (e.g., 10/20 for volatile markets, 5/10 for non-volatile).
Dynamic Cloud: The area between the EMAs forms a cloud, colored green for bullish trends, red for bearish trends, or a user-defined color (default yellow) for neutral zones (when EMAs are close, determined by an ATR-based threshold). Users can widen the cloud for visibility.
RSI Filter: RSI is scaled to price levels and plotted on the chart (optional). Signals are filtered to ensure RSI is within volatility-adjusted bull/bear thresholds and not in overbought/oversold zones.
ATR Volatility Filter: An optional filter ensures signals occur during sufficient volatility (ATR(14) > SMA(ATR, 20)).
50/200 EMA Trend Filter: An optional filter restricts bull signals to bullish trends (50 EMA > 200 EMA) and bear signals to bearish trends (50 EMA < 200 EMA).
Time Filter: Signals are restricted to a user-defined UTC time window (default 9:00–15:00), aligning with active trading sessions.
Market Condition Labels: Labels above the chart display the current trend (Bullish, Bearish, Neutral) and optionally volatility (e.g., “Bullish Volatile”). Up to two historical labels persist for a user-defined number of bars (default 5) to show recent trend changes.
Visual Aids: Bull signals appear as green triangles/labels below the bar, bear signals as red triangles/labels above. Candlesticks in neutral zones are colored (default yellow).
The indicator ensures compatibility with standard chart types (e.g., candlestick or bar charts) to produce realistic signals, avoiding non-standard types like Heikin Ashi or Renko.
How to Use It
Add to Chart: Apply the indicator to a candlestick or bar chart on TradingView.
Configure Settings:
Timeframe: Choose a timeframe (1, 5, 15, 30, or 60 minutes) to match your trading style.
Filters:
Enable/disable the ATR volatility filter to focus on high-volatility periods.
Enable/disable the 50/200 EMA trend filter to align signals with the broader trend.
Enable the time filter and set custom UTC hours/minutes (default 9:00–15:00).
Cloud Settings: Adjust the cloud width, neutral zone threshold, color, and transparency.
EMA Colors: Use default trend-based colors or set custom colors for short/long EMAs.
RSI Display: Toggle the scaled RSI and its thresholds, with customizable colors.
Signal Settings: Toggle bull/bear labels and set signal colors.
Market Condition Labels: Toggle current/historical labels, include/exclude volatility, and adjust decay period.
Interpret Signals:
Bull Signal: A green triangle or “Bull” label below the bar indicates potential bullish momentum (EMA crossover, RSI above bull threshold, within time window, passing filters).
Bear Signal: A red triangle or “Bear” label above the bar indicates potential bearish momentum (EMA crossunder, RSI below bear threshold, within time window, passing filters).
Neutral Zone: Yellow candlesticks and cloud (if enabled) suggest a lack of clear trend; consider range-bound strategies or avoid trading.
Market Condition Labels: Check labels above the chart for real-time trend (Bullish, Bearish, Neutral) and volatility status to confirm market context.
Monitor Context: Use the cloud, RSI, and labels to assess trend strength and volatility before acting on signals.
Unique Features
Volatility-Adaptive EMAs: Automatically adjusts EMA lengths based on ATR to suit volatile or non-volatile markets, reducing manual configuration.
Neutral Zone Detection: Uses an ATR-based threshold to identify low-trend periods, helping traders avoid choppy markets.
Scaled RSI Visualization: Plots RSI and thresholds directly on the price chart, simplifying momentum analysis relative to price.
Flexible Time Filtering: Supports precise UTC-based trading windows, ideal for day traders targeting specific sessions.
Historical Market Labels: Displays recent trend changes (up to two) with a decay period, providing context for market shifts.
50/200 EMA Trend Filter: Aligns signals with the broader market trend, enhancing signal reliability.
Notes
Use on standard candlestick or bar charts to ensure accurate signals.
Test the indicator on a demo account to optimize settings for your market and timeframe.
Combine with other analysis (e.g., support/resistance, volume) for better decision-making.
The indicator is not a standalone system; use it as part of a broader trading strategy.
Limitations
Signals may lag in fast-moving markets due to EMA-based calculations.
Neutral zone detection may vary in extremely volatile or illiquid markets.
Time filters are UTC-based; ensure your platform’s timezone settings align.
This indicator is designed for traders seeking a customizable, trend-following tool that adapts to volatility and provides clear visual cues with robust filtering for bullish and bearish market conditions.
Adaptive Freedom Machine w/labelsAdaptive Freedom Machine w/ Labels
Overview
The Adaptive Freedom Machine w/ Labels is a versatile Pine Script indicator designed to assist traders in identifying buy and sell opportunities across various market conditions (trending, ranging, or volatile). It combines Exponential Moving Averages (EMAs), Relative Strength Index (RSI), Average True Range (ATR), and customizable time filters to generate actionable signals. The indicator overlays on the price chart, displaying EMAs, a dynamic cloud, scaled RSI levels, buy/sell signals, and market condition labels, making it suitable for swing trading, day trading, or scalping.
What It Does
This indicator generates buy and sell signals based on the interaction of two EMAs, filtered by RSI thresholds, ATR-based volatility, and user-defined time windows. It adapts to the selected market condition by adjusting EMA lengths, RSI thresholds, and trading hours. A dynamic cloud highlights trend direction or neutral zones, and candlestick bodies are colored in neutral conditions for clarity. A table displays real-time trend and volatility status.
How It Works
The indicator uses the following components:
EMAs: Two EMAs (short and long) are calculated on a user-selected timeframe (1, 5, 15, 30, or 60 minutes). Their crossover or crossunder generates potential buy/sell signals, with lengths adjusted based on the market condition (e.g., longer EMAs for trending markets, shorter for ranging).
Dynamic Cloud: The area between the EMAs forms a cloud, colored green for uptrends, red for downtrends, or a user-defined color (default yellow) for neutral zones (when EMAs are close, determined by an ATR-based threshold). Users can widen the cloud for visibility.
RSI Filter: RSI is scaled to price levels and plotted on the chart (optional). Signals are filtered to ensure RSI is within user-defined buy/sell thresholds and not in overbought/oversold zones, with thresholds tailored to the market condition.
ATR Volatility Filter: An optional filter ensures signals occur during sufficient volatility (ATR(14) > SMA(ATR, 20)).
Time Filter: Signals are restricted to a user-defined or market-specific time window (e.g., 10:00–15:00 UTC for volatile markets), with an option for custom hours.
Visual Aids: Buy/sell signals appear as green triangles (buy) or red triangles (sell). Candlesticks in neutral zones are colored (default yellow). A table in the top-right corner shows the current trend (Uptrend, Downtrend, Neutral) and volatility (High or Low).
The indicator ensures compatibility with standard chart types (e.g., candlestick charts) to produce realistic signals, avoiding non-standard types like Heikin Ashi or Renko.
How to Use It
Add to Chart: Apply the indicator to a candlestick or bar chart on TradingView.
Configure Settings:
Timeframe: Choose a timeframe (1, 5, 15, 30, or 60 minutes) to align with your trading style.
Market Condition: Select one market condition (Trending, Ranging, or Volatile). Volatile is the default if none is selected. Only one condition can be active.
Filters:
Enable/disable the ATR volatility filter to trade only in high-volatility periods.
Enable the time filter and choose default hours (specific to the market condition) or set custom UTC hours.
Cloud Settings: Adjust the cloud width, neutral zone threshold, and color. Enable/disable the neutral cloud.
RSI Display: Toggle the scaled RSI and its thresholds on the chart.
Interpret Signals:
Buy Signal: A green triangle below the bar indicates a potential long entry (EMA crossover, RSI above buy threshold, within time window, and passing volatility filter).
Sell Signal: A red triangle above the bar indicates a potential short entry (EMA crossunder, RSI below sell threshold, within time window, and passing volatility filter).
Neutral Zone: Yellow candlesticks and cloud (if enabled) suggest a lack of clear trend; avoid trading or use for range-bound strategies.
Monitor the Table: Check the top-right table for real-time trend (Uptrend, Downtrend, Neutral) and volatility (High or Low) to confirm market context.
Unique Features
Adaptive Parameters: Automatically adjusts EMA lengths, RSI thresholds, and trading hours based on the selected market condition, reducing manual tweaking.
Neutral Zone Detection: Uses an ATR-based threshold to identify low-trend periods, helping traders avoid choppy markets.
Scaled RSI Visualization: Plots RSI and thresholds directly on the price chart, making it easier to assess momentum relative to price action.
Flexible Time Filtering: Supports both default and custom UTC-based trading windows, ideal for day traders targeting specific sessions.
Dynamic Cloud: Enhances trend visualization with customizable width and neutral zone coloring, improving readability.
Notes
Use on standard candlestick or bar charts to ensure realistic signals.
Test the indicator on a demo account to understand its behavior in your chosen market and timeframe.
Adjust settings to match your trading strategy, but avoid over-optimizing for past data.
The indicator is not a standalone system; combine it with other analysis (e.g., support/resistance, news events) for better results.
Limitations
Signals may lag in fast-moving markets due to EMA-based calculations.
Neutral zone detection may vary in extremely volatile or illiquid markets.
Time filters are UTC-based; ensure your platform’s timezone settings align.
This indicator is designed for traders seeking a customizable, trend-following tool that adapts to different market environments while providing clear visual cues and robust filtering.
Silver Bullet ICT Strategy [TradingFinder] 10-11 AM NY Time +FVG🔵 Introduction
The ICT Silver Bullet trading strategy is a precise, time-based algorithmic approach that relies on Fair Value Gaps and Liquidity to identify high-probability trade setups. The strategy primarily focuses on the New York AM Session from 10:00 AM to 11:00 AM, leveraging heightened market activity within this critical window to capture short-term trading opportunities.
As an intraday strategy, it is most effective on lower timeframes, with ICT recommending a 15-minute chart or lower. While experienced traders often utilize 1-minute to 5-minute charts, beginners may find the 1-minute timeframe more manageable for applying this strategy.
This approach specifically targets quick trades, designed to take advantage of market movements within tight one-hour windows. By narrowing its focus, the Silver Bullet offers a streamlined and efficient method for traders to capitalize on liquidity shifts and price imbalances with precision.
In the fast-paced world of forex trading, the ability to identify market manipulation and false price movements is crucial for traders aiming to stay ahead of the curve. The Silver Bullet Indicator simplifies this process by integrating ICT principles such as liquidity traps, Order Blocks, and Fair Value Gaps (FVG).
These concepts form the foundation of a tool designed to mimic the strategies of institutional players, empowering traders to align their trades with the "smart money." By transforming complex market dynamics into actionable insights, the Silver Bullet Indicator provides a powerful framework for short-term trading success
Silver Bullet Bullish Setup :
Silver Bullet Bearish Setup :
🔵 How to Use
The Silver Bullet Indicator is a specialized tool that operates within the critical time windows of 9:00-10:00 and 10:00-11:00 in the forex market. Its design incorporates key principles from ICT (Inner Circle Trader) methodology, focusing on concepts such as liquidity traps, CISD Levels, Order Blocks, and Fair Value Gaps (FVG) to provide precise and actionable trade setups.
🟣 Bullish Setup
In a bullish setup, the indicator starts by marking the high and low of the session, serving as critical reference points for liquidity. A typical sequence involves a liquidity grab below the low, where the price manipulates retail traders into selling positions by breaching a key support level.
This movement is often orchestrated by smart money to accumulate buy orders. Following this liquidity grab, a market structure shift (MSS) occurs, signaled by the price breaking the CISD Level—a confirmation of bullish intent. The indicator then highlights an Order Block near the CISD Level, representing the zone where institutional buying is concentrated.
Additionally, it identifies a Fair Value Gap, which acts as a high-probability area for price retracement and trade entry. Traders can confidently take long positions when the price revisits these zones, targeting the next significant liquidity pool or resistance level.
Bullish Setup in CAPITALCOM:US100 :
🟣 Bearish Setup
Conversely, in a bearish setup, the price manipulates liquidity by creating a false breakout above the high of the session. This move entices retail traders into long positions, allowing institutional players to enter sell orders.
Once the price reverses direction and breaches the CISD Level to the downside, a change of character (CHOCH) becomes evident, confirming a bearish market structure. The indicator highlights an Order Block near this level, indicating the origin of the institutional sell orders, along with an associated FVG, which represents an imbalance zone likely to be revisited before the price continues downward.
By entering short positions when the price retraces to these levels, traders align their strategies with the anticipated continuation of bearish momentum, targeting nearby liquidity voids or support zones.
Bearish Setup in OANDA:XAUUSD :
🔵 Settings
Refine Order Block : Enables finer adjustments to Order Block levels for more accurate price responses.
Mitigation Level OB : Allows users to set specific reaction points within an Order Block, including: Proximal: Closest level to the current price. 50% OB: Midpoint of the Order Block. Distal: Farthest level from the current price.
FVG Filter : The Judas Swing indicator includes a filter for Fair Value Gap (FVG), allowing different filtering based on FVG width: FVG Filter Type: Can be set to "Very Aggressive," "Aggressive," "Defensive," or "Very Defensive." Higher defensiveness narrows the FVG width, focusing on narrower gaps.
Mitigation Level FVG : Like the Order Block, you can set price reaction levels for FVG with options such as Proximal, 50% OB, and Distal.
CISD : The Bar Back Check option enables traders to specify the number of past candles checked for identifying the CISD Level, enhancing CISD Level accuracy on the chart.
🔵 Conclusion
The Silver Bullet Indicator is a cutting-edge tool designed specifically for forex traders who aim to leverage market dynamics during critical liquidity windows. By focusing on the highly active 9:00-10:00 and 10:00-11:00 timeframes, the indicator simplifies complex market concepts such as liquidity traps, Order Blocks, Fair Value Gaps (FVG), and CISD Levels, transforming them into actionable insights.
What sets the Silver Bullet Indicator apart is its precision in detecting false breakouts and market structure shifts (MSS), enabling traders to align their strategies with institutional activity. The visual clarity of its signals, including color-coded zones and directional arrows, ensures that both novice and experienced traders can easily interpret and apply its findings in real-time.
By integrating ICT principles, the indicator empowers traders to identify high-probability entry and exit points, minimize risk, and optimize trade execution. Whether you are capturing short-term price movements or navigating complex market conditions, the Silver Bullet Indicator offers a robust framework to enhance your trading performance.
Ultimately, this tool is more than just an indicator; it is a strategic ally for traders who seek to decode the movements of smart money and capitalize on institutional strategies. With the Silver Bullet Indicator, traders can approach the market with greater confidence, precision, and profitability.

LTI_FiltersLinear Time-Invariant (LTI) filters are fundamental tools in signal processing that operate with consistent behavior over time and linearly respond to input signals. They are crucial for analyzing and manipulating signals in various applications, ensuring the output signal's integrity is maintained regardless of when an input is applied or its magnitude. The Windowed Sinc filter is a specific type of LTI filter designed for digital signal processing. It employs a Sinc function, ideal for low-pass filtering, truncated and shaped within a finite window to make it practically implementable. This process involves multiplying the Sinc function by a window function, which tapers off towards the ends, making the filter finite and suitable for digital applications. Windowed Sinc filters are particularly effective for tasks like data smoothing and removing unwanted frequency components, balancing between sharp cutoff characteristics and minimal distortion. The efficiency of Windowed Sinc filters in digital signal processing lies in their adept use of linear algebra, particularly in the convolution process, which combines input data with filter coefficients to produce the desired output. This mathematical foundation allows for precise control over the filtering process, optimizing the balance between filtering performance and computational efficiency. By leveraging linear algebra techniques such as matrix multiplication and Toeplitz matrices, these filters can efficiently handle large datasets and complex filtering tasks, making them invaluable in applications requiring high precision and speed, such as audio processing, financial signal analysis, and image restoration.
Library "LTI_Filters"
offset(length, enable)
Calculates the time offset required for aligning the output of a filter with its input, based on the filter's length. This is useful for centered filters where the output is naturally shifted due to the filter's operation.
Parameters:
length (simple int) : The length of the filter.
enable (simple bool) : A boolean flag to enable or dissable the offset calculation.
Returns: The calculated offset if enabled; otherwise, returns 0.
lti_filter(filter_type, source, length, prefilter, centered, fc, window_type)
General-purpose Linear Time-Invariant (LTI) filter function that can apply various filter types to a data series. Can be used to apply a variety of LTI filters with different characteristics to financial data series or other time series data.
Parameters:
filter_type (simple string) : Specifies the type of filter. ("Sinc", "SMA", "WMA")
source (float) : The input data series to filter.
length (simple int) : The length of the filter.
prefilter (simple bool) : Boolean indicating whether to prefilter the input data.
centered (simple bool) : Determines whether the filter coefficients are centered.
fc (simple float) : Filter cutoff. Expressed like a length.
window_type (simple string) : Type of window function to apply. ("Hann", "Hamming", "Blackman", "Triangular", "Lanczos", "None")
Returns: The filtered data series.
lti_sma(source, length, prefilter)
Applies a Simple Moving Average (SMA) filter to the data series. Useful for smoothing data series to identify trends or for use as a component in more complex indicators.
Parameters:
source (float) : The input data series to filter.
length (simple int) : The length of the SMA filter.
prefilter (simple bool) : Boolean indicating whether to prefilter the input data.
Returns: The SMA-filtered data series.
lti_wma(source, length, prefilter, centered)
Applies a Weighted Moving Average (WMA) filter to a data series. Ideal for smoothing data with emphasis on more recent values, allowing for dynamic adjustments to the weighting scheme.
Parameters:
source (float) : The input data series to filter.
length (simple int) : The length of the WMA filter.
prefilter (simple bool) : Boolean indicating whether to prefilter the input data.
centered (simple bool) : Determines whether the filter coefficients are centered.
Returns: The WMA-filtered data series.
lti_sinc(source, length, prefilter, centered, fc, window_type)
Applies a Sinc filter to a data series, optionally using a window function. Particularly useful for signal processing tasks within financial analysis, such as smoothing or trend identification, with the ability to fine-tune filter characteristics.
Parameters:
source (float) : The input data series to filter.
length (simple int) : The length of the Sinc filter.
prefilter (simple bool) : Boolean indicating whether to prefilter the input data.
centered (simple bool) : Determines whether the filter coefficients are centered.
fc (simple float) : Filter cutoff. Expressed like a length.
window_type (simple string) : Type of window function to apply. ("Hann", "Hamming", "Blackman", "Triangular", "Lanczos", "None")
Returns: The Sinc-filtered data series.
Machine Learning: Gaussian Process Regression [LuxAlgo]We provide an implementation of the Gaussian Process Regression (GPR), a popular machine-learning method capable of estimating underlying trends in prices as well as forecasting them.
While this implementation is adapted to real-time usage, do remember that forecasting trends in the market is challenging, do not use this tool as a standalone for your trading decisions.
🔶 USAGE
The main goal of our implementation of GPR is to forecast trends. The method is applied to a subset of the most recent prices, with the Training Window determining the size of this subset.
Two user settings controlling the trend estimate are available, Smooth and Sigma . Smooth determines the smoothness of our estimate, with higher values returning smoother results suitable for longer-term trend estimates.
Sigma controls the amplitude of the forecast, with values closer to 0 returning results with a higher amplitude. Do note that due to the calculation of the method, lower values of sigma can return errors with higher values of the training window.
🔹 Updating Mechanisms
The script includes three methods to update a forecast. By default a forecast will not update for new bars (Lock Forecast).
The forecast can be re-estimated once the price reaches the end of the forecasting window when using the "Update Once Reached" method.
Finally "Continuously Update" will update the whole forecast on any new bar.
🔹 Estimating Trends
Gaussian Process Regression can be used to estimate past underlying local trends in the price, allowing for a noise-free interpretation of trends.
This can be useful for performing descriptive analysis, such as highlighting patterns more easily.
🔶 SETTINGS
Training Window: Number of most recent price observations used to fit the model
Forecasting Length: Forecasting horizon, determines how many bars in the future are forecasted.
Smooth: Controls the degree of smoothness of the model fit.
Sigma: Noise variance. Controls the amplitude of the forecast, lower values will make it more sensitive to outliers.
Update: Determines when the forecast is updated, by default the forecast is not updated for new bars.

theme_presetsStyle Made Easy with 175 Reversable light/dark themes
Built on to of my theme engine, so any tools built with one
will work with the other.
getTheme(_input)
Get a theme by name. (see lib for copy/paste list)
Parameters:
_input : string Name of Theme to use.
apathy()
Theme preset -> "Apathy"
Returns: Theme object
apprentice()
Theme preset -> "Apprentice"
Returns: Theme object
ashes()
Theme preset -> "Ashes"
Returns: Theme object
atelier_cave()
Theme preset -> "Atelier Cave"
Returns: Theme object
atelier_dune()
Theme preset -> "Atelier Dune"
Returns: Theme object
atelier_estuary()
Theme preset -> "Atelier Estuary"
Returns: Theme object
atelier_forest()
Theme preset -> "Atelier Forest"
Returns: Theme object
atelier_heath()
Theme preset -> "Atelier Heath"
Returns: Theme object
atelier_lakeside()
Theme preset -> "Atelier Lakeside"
Returns: Theme object
atelier_plateau()
Theme preset -> "Atelier Plateau"
Returns: Theme object
atelier_savanna()
Theme preset -> "Atelier Savanna"
Returns: Theme object
atelier_seaside()
Theme preset -> "Atelier Seaside"
Returns: Theme object
atelier_sulphurpool()
Theme preset -> "Atelier Sulphurpool"
Returns: Theme object
atlas()
Theme preset -> "Atlas"
Returns: Theme object
ayu()
Theme preset -> "Ayu"
Returns: Theme object
ayu_mirage()
Theme preset -> "Ayu Mirage"
Returns: Theme object
bespin()
Theme preset -> "Bespin"
Returns: Theme object
black_metal()
Theme preset -> "Black Metal"
Returns: Theme object
black_metal_bathory()
Theme preset -> "Black Metal (bathory)"
Returns: Theme object
black_metal_burzum()
Theme preset -> "Black Metal (burzum)"
Returns: Theme object
black_metal_funeral()
Theme preset -> "Black Metal (dark Funeral)"
Returns: Theme object
black_metal_gorgoroth()
Theme preset -> "Black Metal (gorgoroth)"
Returns: Theme object
black_metal_immortal()
Theme preset -> "Black Metal (immortal)"
Returns: Theme object
black_metal_khold()
Theme preset -> "Black Metal (khold)"
Returns: Theme object
black_metal_marduk()
Theme preset -> "Black Metal (marduk)"
Returns: Theme object
black_metal_mayhem()
Theme preset -> "Black Metal (mayhem)"
Returns: Theme object
black_metal_nile()
Theme preset -> "Black Metal (nile)"
Returns: Theme object
black_metal_venom()
Theme preset -> "Black Metal (venom)"
Returns: Theme object
blue_forest()
Theme preset -> "Blue Forest"
Returns: Theme object
blueish()
Theme preset -> "Blueish"
Returns: Theme object
brewer()
Theme preset -> "Brewer"
Returns: Theme object
bright()
Theme preset -> "Bright"
Returns: Theme object
brogrammer()
Theme preset -> "Brogrammer"
Returns: Theme object
brush_trees()
Theme preset -> "Brush Trees"
Returns: Theme object
catppuccin()
Theme preset -> "Catppuccin"
Returns: Theme object
chalk()
Theme preset -> "Chalk"
Returns: Theme object
circus()
Theme preset -> "Circus"
Returns: Theme object
classic()
Theme preset -> "Classic"
Returns: Theme object
clrs()
Theme preset -> "Colors"
Returns: Theme object
codeschool()
Theme preset -> "Codeschool"
Returns: Theme object
cupcake()
Theme preset -> "Cupcake"
Returns: Theme object
cupertino()
Theme preset -> "Cupertino"
Returns: Theme object
da_one_black()
Theme preset -> "Da One Black"
Returns: Theme object
da_one_gray()
Theme preset -> "Da One Gray"
Returns: Theme object
da_one_ocean()
Theme preset -> "Da One Ocean"
Returns: Theme object
da_one_paper()
Theme preset -> "Da One Paper"
Returns: Theme object
da_one_sea()
Theme preset -> "Da One Sea"
Returns: Theme object
da_one_white()
Theme preset -> "Da One White"
Returns: Theme object
danqing()
Theme preset -> "Danqing"
Returns: Theme object
darcula()
Theme preset -> "Darcula"
Returns: Theme object
dark_violet()
Theme preset -> "Dark Violet"
Returns: Theme object
darkmoss()
Theme preset -> "Darkmoss"
Returns: Theme object
darktooth()
Theme preset -> "Darktooth"
Returns: Theme object
decaf()
Theme preset -> "Decaf"
Returns: Theme object
dirtysea()
Theme preset -> "Dirtysea"
Returns: Theme object
dracula()
Theme preset -> "Dracula"
Returns: Theme object
edge()
Theme preset -> "Edge"
Returns: Theme object
eighties()
Theme preset -> "Eighties"
Returns: Theme object
embers()
Theme preset -> "Embers"
Returns: Theme object
emil()
Theme preset -> "Emil"
Returns: Theme object
equilibrium()
Theme preset -> "Equilibrium"
Returns: Theme object
equilibrium_gray()
Theme preset -> "Equilibrium Gray"
Returns: Theme object
espresso()
Theme preset -> "Espresso"
Returns: Theme object
eva()
Theme preset -> "Eva"
Returns: Theme object
everforest()
Theme preset -> "Everforest"
Returns: Theme object
flat()
Theme preset -> "Flat"
Returns: Theme object
framer()
Theme preset -> "Framer"
Returns: Theme object
fruit_soda()
Theme preset -> "Fruit Soda"
Returns: Theme object
gigavolt()
Theme preset -> "Gigavolt"
Returns: Theme object
github()
Theme preset -> "Github"
Returns: Theme object
google()
Theme preset -> "Google"
Returns: Theme object
gotham()
Theme preset -> "Gotham"
Returns: Theme object
grayscale()
Theme preset -> "Grayscale"
Returns: Theme object
green_screen()
Theme preset -> "Green Screen"
Returns: Theme object
gruber()
Theme preset -> "Gruber"
Returns: Theme object
gruvbox_hard()
Theme preset -> "Gruvbox Dark, Hard"
Returns: Theme object
gruvbox_medium()
Theme preset -> "Gruvbox Dark, Medium"
Returns: Theme object
gruvbox_pale()
Theme preset -> "Gruvbox Dark, Pale"
Returns: Theme object
gruvbox_soft()
Theme preset -> "Gruvbox Dark, Soft"
Returns: Theme object
gruvbox_material_hard()
Theme preset -> "Gruvbox Material Dark, Hard"
Returns: Theme object
gruvbox_material_medium()
Theme preset -> "Gruvbox Material Dark, Medium"
Returns: Theme object
gruvbox_material_soft()
Theme preset -> "Gruvbox Material Dark, Soft"
Returns: Theme object
hardcore()
Theme preset -> "Hardcore"
Returns: Theme object
harmonic16()
Theme preset -> "Harmonic16"
Returns: Theme object
heetch()
Theme preset -> "Heetch"
Returns: Theme object
helios()
Theme preset -> "Helios"
Returns: Theme object
hopscotch()
Theme preset -> "Hopscotch"
Returns: Theme object
horizon()
Theme preset -> "Horizon"
Returns: Theme object
horizon_terminal()
Theme preset -> "Horizon Terminal"
Returns: Theme object
humanoid()
Theme preset -> "Humanoid"
Returns: Theme object
ia()
Theme preset -> "Ia"
Returns: Theme object
icy()
Theme preset -> "Icy"
Returns: Theme object
ir_black()
Theme preset -> "Ir Black"
Returns: Theme object
isotope()
Theme preset -> "Isotope"
Returns: Theme object
kanagawa()
Theme preset -> "Kanagawa"
Returns: Theme object
katy()
Theme preset -> "Katy"
Returns: Theme object
kimber()
Theme preset -> "Kimber"
Returns: Theme object
lime()
Theme preset -> "Lime"
Returns: Theme object
london_tube()
Theme preset -> "London Tube"
Returns: Theme object
macintosh()
Theme preset -> "Macintosh"
Returns: Theme object
marrakesh()
Theme preset -> "Marrakesh"
Returns: Theme object
materia()
Theme preset -> "Materia"
Returns: Theme object
material()
Theme preset -> "Material"
Returns: Theme object
materialdarker()
Theme preset -> "Material Darker"
Returns: Theme object
material_palenight()
Theme preset -> "Material Palenight"
Returns: Theme object
material_vivid()
Theme preset -> "Material Vivid"
Returns: Theme object
mellow_purple()
Theme preset -> "Mellow Purple"
Returns: Theme object
mocha()
Theme preset -> "Mocha"
Returns: Theme object
monokai()
Theme preset -> "Monokai"
Returns: Theme object
Nebula()
Theme preset -> "Nebula"
Returns: Theme object
nord()
Theme preset -> "Nord"
Returns: Theme object
nova()
Theme preset -> "Nova"
Returns: Theme object
ocean()
Theme preset -> "Ocean"
Returns: Theme object
oceanicnext()
Theme preset -> "Oceanicnext"
Returns: Theme object
onedark()
Theme preset -> "Onedark"
Returns: Theme object
outrun()
Theme preset -> "Outrun"
Returns: Theme object
pandora()
Theme preset -> "Pandora"
Returns: Theme object
papercolor()
Theme preset -> "Papercolor"
Returns: Theme object
paraiso()
Theme preset -> "Paraiso"
Returns: Theme object
pasque()
Theme preset -> "Pasque"
Returns: Theme object
phd()
Theme preset -> "Phd"
Returns: Theme object
pico()
Theme preset -> "Pico"
Returns: Theme object
pinky()
Theme preset -> "Pinky"
Returns: Theme object
pop()
Theme preset -> "Pop"
Returns: Theme object
porple()
Theme preset -> "Porple"
Returns: Theme object
primer()
Theme preset -> "Primer"
Returns: Theme object
purpledream()
Theme preset -> "Purpledream"
Returns: Theme object
qualia()
Theme preset -> "Qualia"
Returns: Theme object
railscasts()
Theme preset -> "Railscasts"
Returns: Theme object
rebecca()
Theme preset -> "Rebecca"
Returns: Theme object
rose_pine()
Theme preset -> "Rosé Pine"
Returns: Theme object
rose_pine_dawn()
Theme preset -> "Rosé Pine Dawn"
Returns: Theme object
rose_pine_moon()
Theme preset -> "Rosé Pine Moon"
Returns: Theme object
sagelight()
Theme preset -> "Sagelight"
Returns: Theme object
sakura()
Theme preset -> "Sakura"
Returns: Theme object
sandcastle()
Theme preset -> "Sandcastle"
Returns: Theme object
seti_ui()
Theme preset -> "Seti Ui"
Returns: Theme object
shades_of_purple()
Theme preset -> "Shades Of Purple"
Returns: Theme object
shadesmear()
Theme preset -> "Shadesmear"
Returns: Theme object
shapeshifter()
Theme preset -> "Shapeshifter"
Returns: Theme object
silk()
Theme preset -> "Silk"
Returns: Theme object
snazzy()
Theme preset -> "Snazzy"
Returns: Theme object
solar_flare()
Theme preset -> "Solar Flare"
Returns: Theme object
solarized()
Theme preset -> "Solarized"
Returns: Theme object
spaceduck()
Theme preset -> "Spaceduck"
Returns: Theme object
spacemacs()
Theme preset -> "Spacemacs"
Returns: Theme object
stella()
Theme preset -> "Stella"
Returns: Theme object
still_alive()
Theme preset -> "Still Alive"
Returns: Theme object
summercamp()
Theme preset -> "Summercamp"
Returns: Theme object
summerfruit()
Theme preset -> "Summerfruit"
Returns: Theme object
synth_midnight_terminal()
Theme preset -> "Synth Midnight Terminal"
Returns: Theme object
tango()
Theme preset -> "Tango"
Returns: Theme object
tender()
Theme preset -> "Tender"
Returns: Theme object
tokyo_city()
Theme preset -> "Tokyo City"
Returns: Theme object
tokyo_city_terminal()
Theme preset -> "Tokyo City Terminal"
Returns: Theme object
tokyo_night()
Theme preset -> "Tokyo Night"
Returns: Theme object
tokyo_night_storm()
Theme preset -> "Tokyo Night Storm"
Returns: Theme object
tokyo_night_terminal()
Theme preset -> "Tokyo Night Terminal"
Returns: Theme object
tokyo_night_terminal_storm()
Theme preset -> "Tokyo Night Terminal Storm"
Returns: Theme object
tokyodark()
Theme preset -> "Tokyodark"
Returns: Theme object
tokyodark_terminal()
Theme preset -> "Tokyodark Terminal"
Returns: Theme object
tomorrow()
Theme preset -> "Tomorrow"
Returns: Theme object
tomorrow_night()
Theme preset -> "Tomorrow Night"
Returns: Theme object
tomorrow_night_eighties()
Theme preset -> "Tomorrow Night Eighties"
Returns: Theme object
twilight()
Theme preset -> "Twilight"
Returns: Theme object
unikitty()
Theme preset -> "Unikitty"
Returns: Theme object
unikitty_reversible()
Theme preset -> "Unikitty Reversible"
Returns: Theme object
uwunicorn()
Theme preset -> "Uwunicorn"
Returns: Theme object
vice()
Theme preset -> "Vice"
Returns: Theme object
vulcan()
Theme preset -> "Vulcan"
Returns: Theme object
windows_10()
Theme preset -> "Windows 10"
Returns: Theme object
windows_95()
Theme preset -> "Windows 95"
Returns: Theme object
windows_high_contrast()
Theme preset -> "Windows High Contrast"
Returns: Theme object
windows_nt()
Theme preset -> "Windows Nt"
Returns: Theme object
woodland()
Theme preset -> "Woodland"
Returns: Theme object
xcode_dusk()
Theme preset -> "Xcode Dusk"
Returns: Theme object

STD/C-Filtered, Truncated Taylor Family FIR Filter [Loxx]STD/C-Filtered, Truncated Taylor Family FIR Filter is a FIR Digital Filter that uses Truncated Taylor Family of Windows. Taylor functions are obtained by adding a weighted-cosine series to a constant (called a pedestal). A simpler form of these functions can be obtained by dropping some of the higher-order terms in the Taylor series expansion. If all other terms, except for the first two significant ones, are dropped, a truncated Taylor function is obtained. This is a generalized window that is expressed as:
(1 + K) / 2 + (1 - K) / 2 * math.cos(2.0 * math.pi *n / N) where 0 ≤ |n| ≤ N/2
Here k can take the values in the range 0≤k≤1. We note that the Hann 0 ≤ |n| ≤ window is a special case of the truncated Taylor family with k = 0 and Rectangular 0 ≤ |n| ≤ window (SMA) is a special case of the truncated Taylor family with k = 1.
Truncated Taylor Family of Windows amplitudes for this indicator with K = 0.5
This indicator also includes Standard Deviation and Clutter filtering.
What is a Standard Devaition Filter?
If price or output or both don't move more than the (standard deviation) * multiplier then the trend stays the previous bar trend. This will appear on the chart as "stepping" of the moving average line. This works similar to Super Trend or Parabolic SAR but is a more naive technique of filtering.
What is a Clutter Filter?
For our purposes here, this is a filter that compares the slope of the trading filter output to a threshold to determine whether to shift trends. If the slope is up but the slope doesn't exceed the threshold, then the color is gray and this indicates a chop zone. If the slope is down but the slope doesn't exceed the threshold, then the color is gray and this indicates a chop zone. Alternatively if either up or down slope exceeds the threshold then the trend turns green for up and red for down. Fro demonstration purposes, an EMA is used as the moving average. This acts to reduce the noise in the signal.
Included
Bar coloring
Loxx's Expanded Source Types
Signals
Alerts

energies_correlation_zscoreA table to help track correlations between the four major energies contracts of the CME. The table shows the z-score of the current correlation value between HO, RB, CL, and NG. The inputs are:
- timeframe: the timeframe of the calcluation. the default is 5 minutes.
- window: the rolling window over which to calculate the correlations. the default is 48, or four hours given the default timeframe.
A score of zer means that the correlation over the latest window is in line with the average for all windows sampled from the chart history. More positive scores imply higher positive correlation than normal, and vice versa for negative scores.

ConditionalAverages█ OVERVIEW
This library is a Pine Script™ programmer’s tool containing functions that average values selectively.
█ CONCEPTS
Averaging can be useful to smooth out unstable readings in the data set, provide a benchmark to see the underlying trend of the data, or to provide a general expectancy of values in establishing a central tendency. Conventional averaging techniques tend to apply indiscriminately to all values in a fixed window, but it can sometimes be useful to average values only when a specific condition is met. As conditional averaging works on specific elements of a dataset, it can help us derive more context-specific conclusions. This library offers a collection of averaging methods that not only accomplish these tasks, but also exploit the efficiencies of the Pine Script™ runtime by foregoing unnecessary and resource-intensive for loops.
█ NOTES
To Loop or Not to Loop
Though for and while loops are essential programming tools, they are often unnecessary in Pine Script™. This is because the Pine Script™ runtime already runs your scripts in a loop where it executes your code on each bar of the dataset. Pine Script™ programmers who understand how their code executes on charts can use this to their advantage by designing loop-less code that will run orders of magnitude faster than functionally identical code using loops. Most of this library's function illustrate how you can achieve loop-less code to process past values. See the User Manual page on loops for more information. If you are looking for ways to measure execution time for you scripts, have a look at our LibraryStopwatch library .
Our `avgForTimeWhen()` and `totalForTimeWhen()` are exceptions in the library, as they use a while structure. Only a few iterations of the loop are executed on each bar, however, as its only job is to remove the few elements in the array that are outside the moving window defined by a time boundary.
Cumulating and Summing Conditionally
The ta.cum() or math.sum() built-in functions can be used with ternaries that select only certain values. In our `avgWhen(src, cond)` function, for example, we use this technique to cumulate only the occurrences of `src` when `cond` is true:
float cumTotal = ta.cum(cond ? src : 0) We then use:
float cumCount = ta.cum(cond ? 1 : 0) to calculate the number of occurrences where `cond` is true, which corresponds to the quantity of values cumulated in `cumTotal`.
Building Custom Series With Arrays
The advent of arrays in Pine has enabled us to build our custom data series. Many of this library's functions use arrays for this purpose, saving newer values that come in when a condition is met, and discarding the older ones, implementing a queue .
`avgForTimeWhen()` and `totalForTimeWhen()`
These two functions warrant a few explanations. They operate on a number of values included in a moving window defined by a timeframe expressed in milliseconds. We use a 1D timeframe in our example code. The number of bars included in the moving window is unknown to the programmer, who only specifies the period of time defining the moving window. You can thus use `avgForTimeWhen()` to calculate a rolling moving average for the last 24 hours, for example, that will work whether the chart is using a 1min or 1H timeframe. A 24-hour moving window will typically contain many more values on a 1min chart that on a 1H chart, but their calculated average will be very close.
Problems will arise on non-24x7 markets when large time gaps occur between chart bars, as will be the case across holidays or trading sessions. For example, if you were using a 24H timeframe and there is a two-day gap between two bars, then no chart bars would fit in the moving window after the gap. The `minBars` parameter mitigates this by guaranteeing that a minimum number of bars are always included in the calculation, even if including those bars requires reaching outside the prescribed timeframe. We use a minimum value of 10 bars in the example code.
Using var in Constant Declarations
In the past, we have been using var when initializing so-called constants in our scripts, which as per the Style Guide 's recommendations, we identify using UPPER_SNAKE_CASE. It turns out that var variables incur slightly superior maintenance overhead in the Pine Script™ runtime, when compared to variables initialized on each bar. We thus no longer use var to declare our "int/float/bool" constants, but still use it when an initialization on each bar would require too much time, such as when initializing a string or with a heavy function call.
Look first. Then leap.
█ FUNCTIONS
avgWhen(src, cond)
Gathers values of the source when a condition is true and averages them over the total number of occurrences of the condition.
Parameters:
src : (series int/float) The source of the values to be averaged.
cond : (series bool) The condition determining when a value will be included in the set of values to be averaged.
Returns: (float) A cumulative average of values when a condition is met.
avgWhenLast(src, cond, cnt)
Gathers values of the source when a condition is true and averages them over a defined number of occurrences of the condition.
Parameters:
src : (series int/float) The source of the values to be averaged.
cond : (series bool) The condition determining when a value will be included in the set of values to be averaged.
cnt : (simple int) The quantity of last occurrences of the condition for which to average values.
Returns: (float) The average of `src` for the last `x` occurrences where `cond` is true.
avgWhenInLast(src, cond, cnt)
Gathers values of the source when a condition is true and averages them over the total number of occurrences during a defined number of bars back.
Parameters:
src : (series int/float) The source of the values to be averaged.
cond : (series bool) The condition determining when a value will be included in the set of values to be averaged.
cnt : (simple int) The quantity of bars back to evaluate.
Returns: (float) The average of `src` in last `cnt` bars, but only when `cond` is true.
avgSince(src, cond)
Averages values of the source since a condition was true.
Parameters:
src : (series int/float) The source of the values to be averaged.
cond : (series bool) The condition determining when the average is reset.
Returns: (float) The average of `src` since `cond` was true.
avgForTimeWhen(src, ms, cond, minBars)
Averages values of `src` when `cond` is true, over a moving window of length `ms` milliseconds.
Parameters:
src : (series int/float) The source of the values to be averaged.
ms : (simple int) The time duration in milliseconds defining the size of the moving window.
cond : (series bool) The condition determining which values are included. Optional.
minBars : (simple int) The minimum number of values to keep in the moving window. Optional.
Returns: (float) The average of `src` when `cond` is true in the moving window.
totalForTimeWhen(src, ms, cond, minBars)
Sums values of `src` when `cond` is true, over a moving window of length `ms` milliseconds.
Parameters:
src : (series int/float) The source of the values to be summed.
ms : (simple int) The time duration in milliseconds defining the size of the moving window.
cond : (series bool) The condition determining which values are included. Optional.
minBars : (simple int) The minimum number of values to keep in the moving window. Optional.
Returns: (float) The sum of `src` when `cond` is true in the moving window.

Lightning Session LevelsLightning Session Levels (LSL) draws clean, non-repainting levels for the major market sessions and a compact HUD in the top-right corner. It’s built to be lightweight, readable, and “set-and-forget” for intraday traders.
What it shows
Session High/Low and Open/Close levels for:
ASIA (00:00–08:00 UTC)
EUROPE (07:00–16:00 UTC)
US (13:30–20:00 UTC)
OVERNIGHT (20:00–24:00 UTC)
HUD panel:
Current active session
Countdown to the next US session (auto-calculated from UTC)
How it works (non-repainting)
Levels are anchored at session close. Each line is created once on the confirmed closing bar of the session (x2 = session end).
Optional Extend Right keeps the level projecting forward without changing the anchor (no “drifting”).
All drawings are pinned to the right price scale for stable reading.
Inputs
Show HUD — toggle the top-right panel.
Show Levels — master switch for drawing levels.
Draw High/Low — H/L session levels.
Draw Open/Close — O/C session levels.
Extend Right — extend all session lines to the future.
Keep N past sessions per market — FIFO limit per session group (default 12).
ASIA / EUROPE / US / OVERNIGHT — enable/disable specific sessions.
Style & palette
Consistent “Lightning” colors:
ASIA = Cyan, EUROPE = Violet, US = Amber, OVERNIGHT = Teal
Labels are always size: Normal for readability.
HUD uses a dark, subtle two-tone background to stay out of the way.
Recommended use
Timeframes: intraday (1m → 4h).
On 1D and higher, TradingView’s session-window time() filters won’t match intraday windows, so levels won’t plot (by design).
Markets: crypto, indices, FX, equities — any symbol where intraday session context helps.
Notes & limitations
Fixed UTC windows. The US window is set to 13:30–20:00 UTC. Daylight-saving shifts (DST) are not auto-adjusted; if you need region-specific DST behavior, treat this as a consistent UTC model.
The HUD timer counts down to the next US open from the current UTC clock.
Draw limits are capped (500 lines, 500 labels) for performance and stability.
Quick start
Add Lightning Session Levels to your chart.
Toggle Draw High/Low and/or Draw Open/Close.
Turn on Extend Right if you want the levels to project forward.
Enable only the sessions you care about (e.g., just EUROPE and US).
Use Keep N past sessions to control clutter (e.g., 6–12).
Disclaimer
This tool is for educational/informational purposes only and is not financial advice. Past session behavior does not guarantee future results. Always manage risk.
