Quadratic Least Squares Moving Average - Smoothing + Forecast Introduction
Technical analysis make often uses of classical statistical procedures, one of them being regression analysis, and since fitting polynomial functions that minimize the sum of squares can be achieved with the use of the mean, variance, covariance...etc, technical analyst only needed to replace the mean in all those calculations with a moving average, we then end up with a low lag filter called least squares moving average (lsma) .
The least squares moving average could be classified as a rolling linear regression, altho this sound really bad it is useful to understand the relationship of both methods, both have the same form, that is ax + b , where a and b are coefficients of the model. However in a simple linear regression a and b are constant, while the lsma use variables instead.
In a simple lsma we model the relationship of the closing price (dependent variable) with a linear sequence (independent variable), therefore x = 1,2,3,4..etc. However we can use polynomial of higher degrees to model such relationship, this is required if we want more reactivity. Therefore we can use a quadratic form, that is ax^2 + bx + c , where a,b and c are variables.
This is the quadratic least squares moving average (qlsma), a not so official term, but we'll stick with it because it still represent the aim of the filter quite well. In this indicator i make the calculations of the qlsma less troublesome, therefore one might understand how it would work, note that in general the coefficients of a polynomial regression model are found using matrix calculus.
The Indicator
A qlsma, unlike the classic lsma, will fit better to the price and will be more reactive, this is the advantage of using an higher degrees for its calculation, we can model more complex relationship.
lsma in green, qlsma in red, with both length = 200
However the over/under shoots are greater, i'll explain why in the next sections, but this is one of the drawbacks of using higher degrees.
The indicator allow to forecast future values, the ahead period of the forecast is determined by the forecast setting. The value for this setting should be lower than length, else the forecasts can easily over/under shoot which heavily damage the forecast. In order to get a view on how well the forecast is performing you can check the option "Show past predicted values".
Of course understanding the logic behind the forecast is important, in short regressions models best fit a certain curve to the data, this curve can be a line (linear regression), a parabola (quadratic regression) and so on, the type of curve is determined by the degree of the polynomial used, here 2, which is a parabola. Lets use a linear regression model as example :
ax + b where x is a linear sequence 1,2,3...and a/b are constants. Our goal is to find the values for a and b that minimize the sum of squares of the line with the dependent variable y, here the closing price, so our hypothesis is that :
closing price = ax + b + ε
where ε is white noise, a component that the model couldn't forecast. The forecast of the closing price 14 step ahead would be equal to :
closing price 14 step aheads = a(x+14) + b
Since x is a linear sequence we only need to sum it with the forecasting horizon period, the same is done here with :
a*(n+forecast)^2 + b*(n + forecast) + c
Note that the forecast proposed in the indicator is more for teaching purpose that anything else, this indicator can't possibly forecast future values, even on a meh rate.
Low lag filters have been used to provide noise free crosses with slow moving average, a bad practice in my opinion due to the ability low lag filters have to overshoot/undershoot, more interesting use cases might be to use the qlsma as input for other indicators.
On The Code
Some of you might know that i posted a "quadratic regression" indicator long ago, the original calculations was coming from a forum, but because the calculation was ugly as hell as well as extra inefficient (dogfood level) i had to do something about it, the name was also terribly misleading.
We can see in the code that we make heavy use of the variance and covariance, both estimated with :
VAR(x) = SMA(x^2) - SMA(x)^2
COV(x,y) = SMA(xy) - SMA(x)SMA(y)
Those elements are then combined, we can easily recognize the intercept element c , who don't change much from the classical lsma.
As Digital Filter
The frequency response of the qlsma is similar to the one of the lsma, those filters amplify certain frequencies in the passband, and have ripples in the stop band. There is something interesting about those filters, first using higher degrees allow to greater boost of the frequencies in the passband, which result in greater over/under shoots. Another funny thing is that the peak/valley of the ripples is equal the peak or valley in the ripples of another lsma of different degree.
The transient response of those filters, that is impulse response, step response...etc is related to the degree of the polynomial used, therefore lets denote a lsma of degree p : lsma(p) , the impulse response of lsma(p) is a polynomial of degree p, and the step response is simple a polynomial of order p+1.
This is why it was more interesting to estimate the qlsma using convolution, however we can no longer forecast future values.
Conclusion
I proposed a more usable quadratic least squares moving average, with more options, as well as a cleaner and more efficient code. The process of shrinking the original code is made easier when you know about the estimations of both variance and covariance.
I hope the proposed indicator/calculation is useful.
Thx for reading !
En küçük Kareler Hareketli Ortalaması (LSMA)

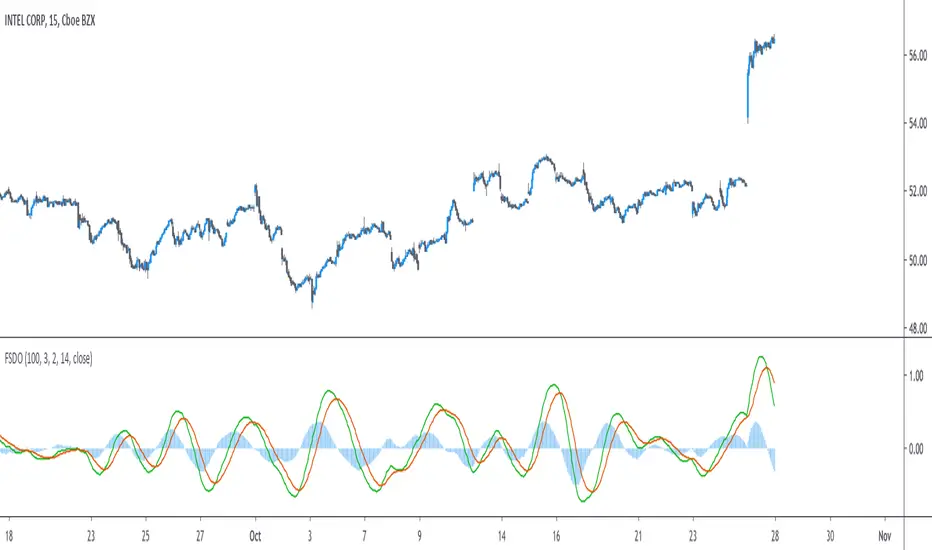
Fast/Slow Degree OscillatorIntroduction
The estimation of a least squares moving average of any degree isn't an interesting goal, this is due to the fact that lsma of high degrees would highly overshoot as well as overfit the closing price, which wouldn't really appear smooth. However i proposed an estimate of an lsma of any degree using convolution and a new sine wave series, all the calculation are described in the paper : "Pierrefeu, Alex (2019): A New Low-Pass FIR Filter For Signal Processing."
Today i want to make use of this filter as an oscillator providing fast entry points. The oscillator would be similar to the MACD in the sense that is consist on the difference between two filters, with one faster than the other, however unlike the MACD which use two moving averages of different length, here i'll use two filters of same length but different degrees.
The Indicator
The indicator consist in 3 elements, one main line (in green) the trigger line (in orange) and the histogram which is the difference between the green line and the red one. The main line is made from the difference between two filters of both period length and different degrees (fast, slow), fast should always be higher than slow. The signal line is just the exponential moving average of the main line, the period of the exponential moving average can be adjusted from the settings.
Both fast/slow determine the degree of the filters, higher values will create a faster filter.
For those who are curious, the filter use a kernel who estimate a polynomial function, this is how an lsma work, the kernel of an lsma of degree p is a polynomial of degree p . I achieved this estimation using a sine wave series.
When fast = 1 and slow = 0, the oscillator appear less periodic, this equivalent to : lsma - sma
Using 2/1 allow the indicator to highlight cycles more easily without being uncorrelated with the price. This is equivalent to qlsma - lsma, where qlsma is a quadratic least squares moving average. This is similar to my old indicator "Linear Quadratic Convergence Divergence Oscillator".
By default the indicator use 3 for fast and 2 for slow, but you can increase both values, here 4/3 :
In general higher values of fast/slow will create way more cyclical results, but they can be uncorrelated with the market price.
Conclusion
This indicator was rather made to show the filter calculation rather than proposing something interesting. However it can be funny to see how the difference between low lag filters create more cyclical outputs, it often allow indicators to have more predictive capabilities.
I invite you to read the paper made about the filter, codes for both pinescript and python are provided.
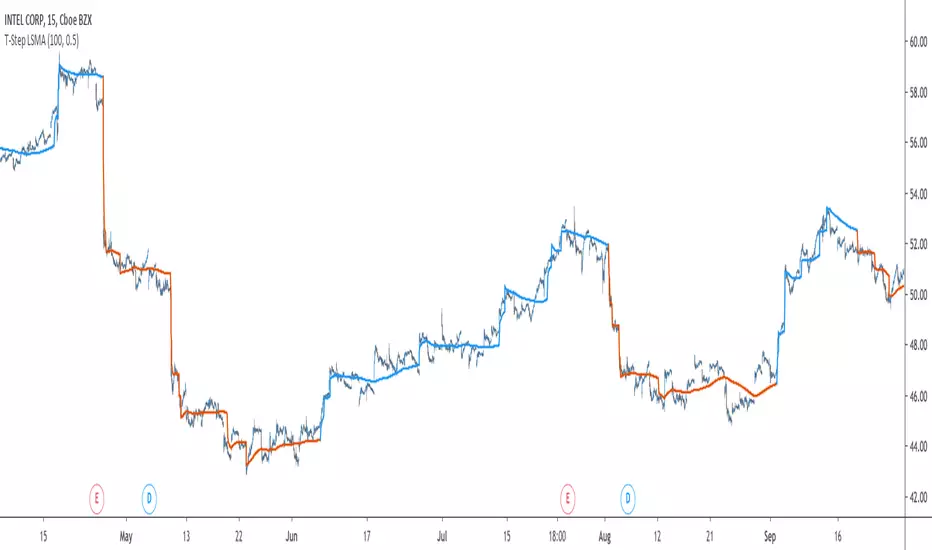
T-Step LSMAIntroduction
The trend step indicator family has produced much interest in the community, those indicators showed in certain cases robustness and reactivity. Their ease of use/interpretation is also a major advantage. Although those indicators have a relatively good fit with the input price, they can still be improved by introducing least-squares fitting on their calculations. This is why i propose a new indicator (T-Step LSMA) which aim to gather all the components of the trend-step indicator family (including the auto-line family).
The indicator will use as a threshold the mean absolute error between the input and the output (T-Channel) scaled with the efficiency ratio (Efficient Trend Step) while using least squares in order to provide a better fit with the price (Auto-Filter).
The Indicator
The interpretation of the indicator is easy, the indicator estimate an up-trending market when in blue, down-trending when in orange, the signal only depend on the trend-step part ( b in the code).
length control the period of the efficiency ratio as well as any components in the lsma calculation. The efficiency ratio allow to provide adaptivity, therefore the threshold will be lower when market is trending and higher when market is ranging.
Sc control the amount of feedback of the indicator, a value of 1 will use only the closing price as input, a value of 0.5 will use 50% of the closing price/indicator output as input, this allow to get smoother results.
It is possible to get the non-smooth version of the indicator by checking "No Smoothing".
This allow the indicator to filter more information.
Least Squares Smoothing - Benefits
One could ask why introducing least squares smoothing, there are several reasons to this choice, we have seen that trend-step indicators are boxy, they filter most of the variational information in the price, introducing least squares smoothing allow to gain back some of this variational information while providing a better fit with the price, the indicator is more noisy but also more practical in certain situations.
For example the indicator in its boxy form can't really be useful as input for other indicators, which is not the case with this version.
Relative strength index of period 14 using the proposed indicator as input.
Down-Sides
The indicator is dependent on the time frame used, larger time frames resulting in an indicator overfitting, sticking with lower time frames might be ideal. The indicator behavior might also change depending on the market in which it is applied.
Setting Up Alerts For The Indicator
Alerts conditions are already set, in order to create an alert based on the indicator follow these steps :
Go to the alert section (the alarm clock) -> create new alert -> select T-Step LSMA in condition -> Below select Up or Dn (Up for a up-trending alert and Dn for a down-trending alert)
In option select "once per bar close", change the message if you want a personalized message.
Conclusion
I don't think i'll post other indicators related to the trend-step framework for the time to comes, nonetheless the ones posted proven to have interesting results as well as many upsides. Although i don't think they would generate positive long-terms returns they could still be of use when using smarter volatility metrics as threshold. The proposed indicator conserve more information than its relatives and might find some use as input for other indicators.
Recommended Use Of The Code
Although i don't put restrictions on the code usage, i still recommend creative and pertinent changes to be made, graphical changes or any minor changes are not necessary, remember that such practice is disrespectful toward the author, you don't want to load up the tradingview servers for nothing right ?
Support Me
Making indicators sure is hard, it takes time and it can be quite lonely to, so i would love talking with you guys while making them :) There isn't better support than the one provided by your friends so drop me a message.
Regression Channel [DW]This is an experimental study which calculates a linear regression channel over a specified period or interval using custom moving average types for its calculations.
Linear regression is a linear approach to modeling the relationship between a dependent variable and one or more independent variables.
In linear regression, the relationships are modeled using linear predictor functions whose unknown model parameters are estimated from the data.
The regression channel in this study is modeled using the least squares approach with four base average types to choose from:
-> Arnaud Legoux Moving Average (ALMA)
-> Exponential Moving Average (EMA)
-> Simple Moving Average (SMA)
-> Volume Weighted Moving Average (VWMA)
When using VWMA, if no volume is present, the calculation will automatically switch to tick volume, making it compatible with any cryptocurrency, stock, currency pair, or index you want to analyze.
There are two window types for calculation in this script as well:
-> Continuous, which generates a regression model over a fixed number of bars continuously.
-> Interval, which generates a regression model that only moves its starting point when a new interval starts. The number of bars for calculation cumulatively increases until the end of the interval.
The channel is generated by calculating standard deviation multiplied by the channel width coefficient, adding it to and subtracting it from the regression line, then dividing it into quartiles.
To observe the path of the regression, I've included a tracer line, which follows the current point of the regression line. This is also referred to as a Least Squares Moving Average (LSMA).
For added predictive capability, there is an option to extend the channel lines into the future.
A custom bar color scheme based on channel direction and price proximity to the current regression value is included.
I don't necessarily recommend using this tool as a standalone, but rather as a supplement to your analysis systems.
Regression analysis is far from an exact science. However, with the right combination of tools and strategies in place, it can greatly enhance your analysis and trading.
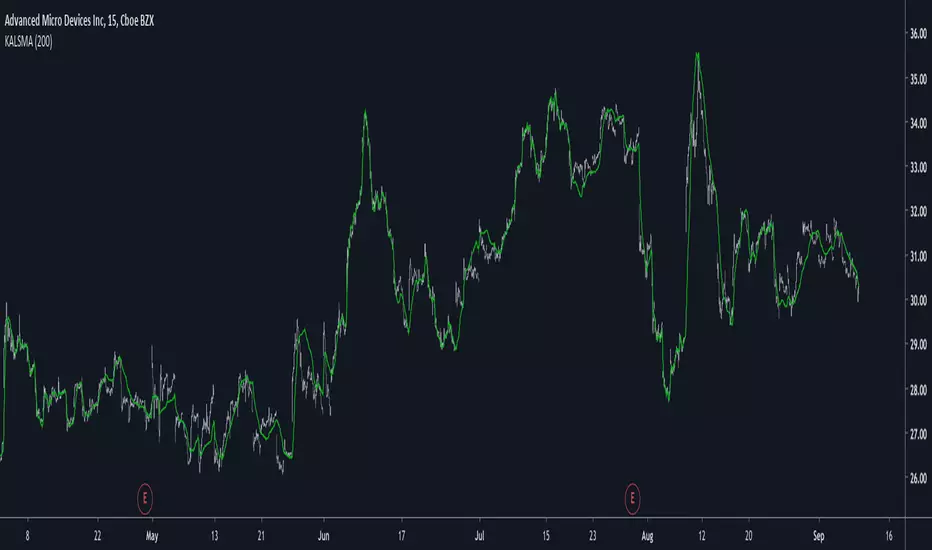
Kaufman Adaptive Least Squares Moving AverageIntroduction
It is possible to use a wide variety of filters for the estimation of a least squares moving average, one of the them being the Kaufman adaptive moving average (KAMA) which adapt to the market trend strength, by using KAMA in an lsma we therefore allow for an adaptive low lag filter which might provide a smarter way to remove noise while preserving reactivity.
The Indicator
The lsma aim to minimize the sum of the squared residuals, paired with KAMA we obtain a great adaptive solution for smoothing while conserving reactivity. Length control the period of the efficiency ratio used in KAMA, higher values of length allow for overall smoother results. The pre-filtering option allow for even smoother results by using KAMA as input instead of the raw price.
The proposed indicator without pre-filtering in green, a simple moving average in orange, and a lsma with all of them length = 200. The proposed filter allow for fast and precise crosses with the moving average while eliminating major whipsaws.
Same setup with the pre-filtering option, the result are overall smoother.
Conclusion
The provided code allow for the implementation of any filter instead of KAMA, try using your own filters. Thanks for reading :)
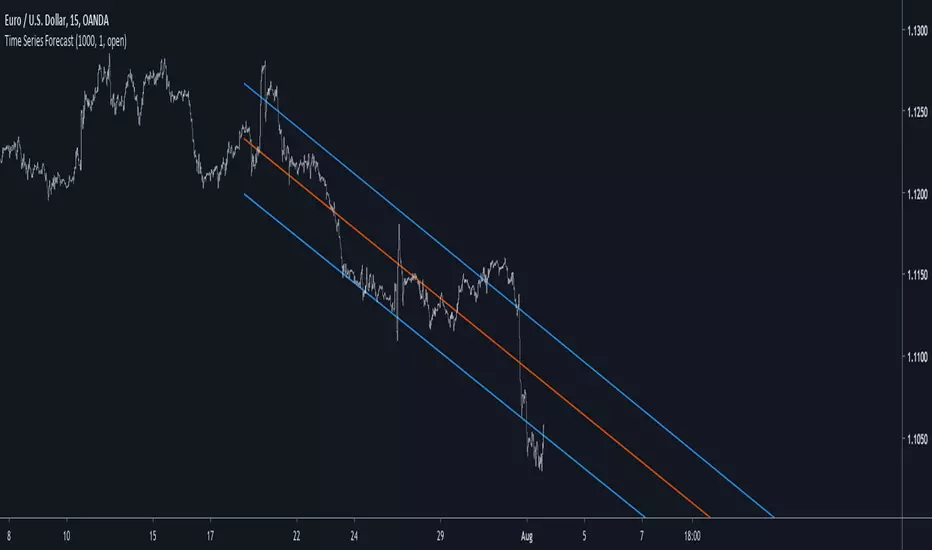
Time Series ForecastIntroduction
Forecasting is a blurry science that deal with lot of uncertainty. Most of the time forecasting is made with the assumption that past values can be used to forecast a time series, the accuracy of the forecast depend on the type of time series, the pre-processing applied to it, the forecast model and the parameters of the model.
In tradingview we don't have much forecasting models appart from the linear regression which is definitely not adapted to forecast financial markets, instead we mainly use it as support/resistance indicator. So i wanted to try making a forecasting tool based on the lsma that might provide something at least interesting, i hope you find an use to it.
The Method
Remember that the regression model and the lsma are closely related, both share the same equation ax + b but the lsma will use running parameters while a and b are constants in a linear regression, the last point of the lsma of period p is the last point of the linear regression that fit a line to the price at time p to 1, try to add a linear regression with count = 100 and an lsma of length = 100 and you will see, this is why the lsma is also called "end point moving average".
The forecast of the linear regression is the linear extrapolation of the fitted line, however the proposed indicator forecast is the linear extrapolation between the value of the lsma at time length and the last value of the lsma when short term extrapolation is false, when short term extrapolation is checked the forecast is the linear extrapolation between the lsma value prior to the last point and the last lsma value.
long term extrapolation, length = 1000
short term extrapolation, length = 1000
How To Use
Intervals are create from the running mean absolute error between the price and the lsma. Those intervals can be interpreted as possible support and resistance levels when using long term extrapolation, make sure that the intervals have been priorly tested, this mean the intervals are more significants.
The short term extrapolation is made with the assumption that the price will follow the last two lsma points direction, the forecast tend to become inaccurate during a trend change or when noise affect heavily the lsma.
You can test both method accuracy with the replay mode.
Comparison With The Linear Regression
Both methods share similitudes, but they have different results, lets compare them.
In blue the indicator and in red a linear regression of both period 200, the linear regression is always extremely conservative since she fit a line using the least squares method, at the contrary the indicator is less conservative which can be an advantage as well as a problem.
Conclusion
Linear models are good when what we want to forecast is approximately linear, thats not the case with market price and this is why other methods are used. But the use of the lsma to provide a forecast is still an interesting method that might require further studies.
Thanks for reading !
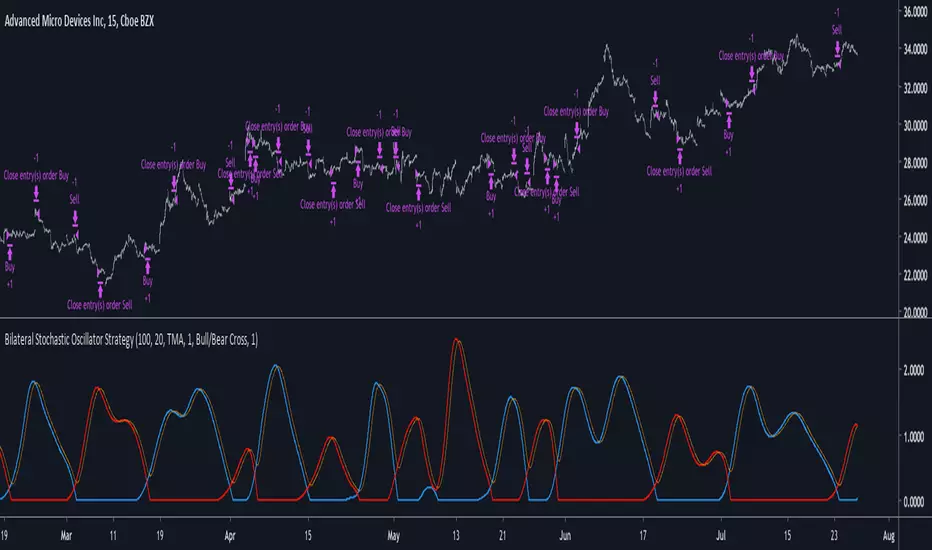
Bilateral Stochastic Oscillator StrategyIntroduction
Strategy based on the bilateral stochastic oscillator, this oscillator aim to detect trends and possible reversal points of the current trend. The oscillator is composed of 1 bull line in blue and 1 bear line in red as well as a signal line in orange, the strategy have many options such as two different strategy framework and a martingale mode. If you require more information about the indicator go check it into my uploaded indicators.
Strategy Frameworks
There are two frameworks available that can be selected from the strategy settings window. Both have the same closing conditions, the "Bull/Bear Cross" entry conditions are :
Buy : when the bull line cross over the bear line
Sell : when the bear line cross over the bull line
The "Signal Cross" entry conditions are :
Buy : when the bull line cross over the signal line
Sell : when the bear line cross over the signal line
Both have the same close conditions that is : close when bull/bear cross under the signal line.
Introduction To Martingale
The martingale money management system consist to double the order size after a loosing trade and can be described as a 2^x where x is the current number of loosing trades since the last win trade, when we win a trade the order size return to the default order size. Therefore our order size function is based on exponential growth.
This system enable the trader to win back his previous losses plus a potential profit, martingales must always be used with stops and sometimes take profits in order to get control in a strategy.
It must always be taken into account that in a series of losses the balance can exponentially decay thus ending to 0 in a matter of trades, this is why it is not recommended to use such system. The strategy allow you to select a martingale multiplier that can be inferior to 2 thus limiting risks, a multiplied of 1 disable the martingale.
Results
Those are the some statistics of the strategy applied to some forex majors by using the default settings in a time frames of 15 minutes.
//-------------------------------------------------------
EURUSD - Order Size 1000 - Spread 0.0002
Profit : $ 21.08
Trades : 19
PP : 57.89 %
Profit Factor : 3.228
Max Drawdown : -$ 3.81
Average Trade : $ 1.11
//-------------------------------------------------------
GBPUSD - Order Size 1000 - Spread 0.0002
Profit : $ 2.31
Trades : 20
PP : 55 %
Profit Factor : 0.938
Max Drawdown : -$ 20.29
Average Trade : $ 0.12
//-------------------------------------------------------
EURAUD - Order Size 1000 - Spread 0.0002
Profit : -$ 9.22
Trades : 20
PP : 40 %
Profit Factor : 0.698
Max Drawdown : -$ 23.44
Average Trade : $ 0.46
//-------------------------------------------------------
EURCHF - Order Size 1000 - Spread 0.0002
Profit : $ 1.58
Trades : 24
PP : 54.17 %
Profit Factor : 1.103
Max Drawdown : -$ 7.23
Average Trade : $ 0.07
//-------------------------------------------------------
Conclusions
Based on the results the strategy does not posses the sufficient performance in order to apply a martingale or any other growth systems as order size. Parameters might be subject to drastic changes depending on the market/time-frame in order to return long-term positive results. I let you draw your conclusions.
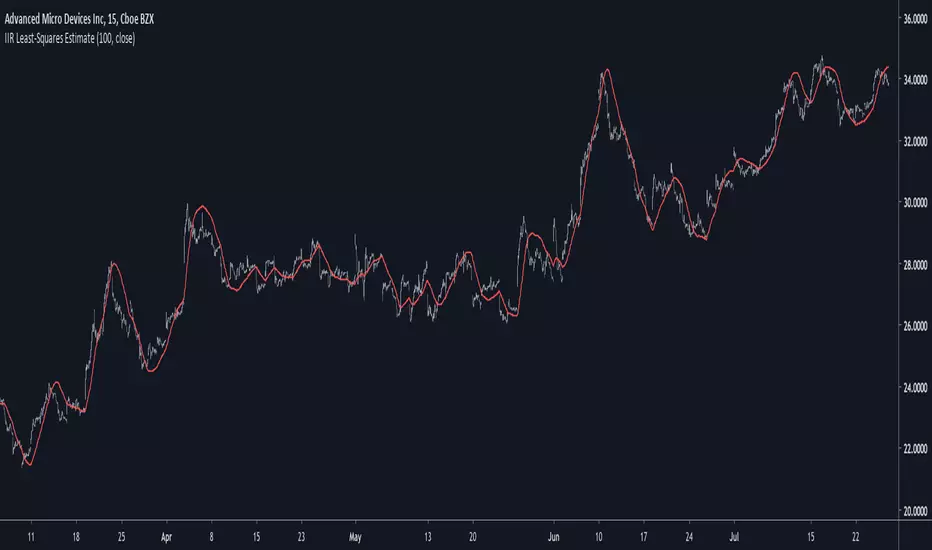
IIR Least-Squares EstimateIntroduction
Another lsma estimate, i don't think you are surprised, the lsma is my favorite low-lag filter and i derived it so many times that our relationship became quite intimate. So i already talked about the classical method, the line-rescaling method and many others, but we did not made to many IIR estimate, the only one was made using a general filter estimator and was pretty inaccurate, this is why i wanted to retry the challenge.
Before talking about the formula lets breakdown again what IIR mean, IIR = infinite impulse response, the impulse response of an IIR filter goes on forever, this is why its infinite, such filters use recursion, this mean they use output's as input's, they are extremely efficient.
The Calculation
The calculation is made with only 1 pole, this mean we only use 1 output value with the same index as input, more poles often means a transition band closer to the cutoff frequency.
Our filter is in the form of :
y = a*x+y - a*ema(y,length/2)
where y = x when t = 1 and y(1) when t > 2 and a = 4/(length+2)
This is also an alternate form of exponential moving average but smoothing the last output terms with another exponential moving average reduce the lag.
Comparison
Lets see the accuracy of our estimate.
Sometimes our estimate follow better the trend, there isn't a clear result about the overshoot/undershoot response, sometimes the estimate have less overshoot/undershoot and sometime its the one with the highest.
The estimate behave nicely with short length periods.
Conclusion
Some surprises, the estimate can at least act as a good low-lag filter, sometimes it also behave better than the lsma by smoothing more. IIR estimate are harder to make but this one look really correct.
If you are looking for something or just want to say thanks try to pm me :)
Thank for reading !
Fisher Least Squares Moving AverageIntroduction
I already estimated the least-squares moving average numerous times, one of the most elegant ways was by rescaling a linear function to the price by using the z-score, today i will propose a new smoother (FLSMA) based on the line rescaling approach and the inverse fisher transform of a scaled moving average error with the goal to provide an alternative least-squares smoother, the indicator won't use the correlation coefficient and will try to adresses problems such as overshoots and lag reduction.
Line Rescaling Method
For those who did not see my least squares moving average estimation using the line rescaling method here is a resume, we want to fit a polynomial function of degree 1 to the price by reducing the sum of squares between the price and the filter, squares is a term meaning the squared difference between the price and its estimation. The line rescaling technique work as follow :
1 - get the z-score of a line.
2 - multiply this z-score with the correlation between the price and a line.
3 - multiply the precedent result with the standard deviation of the price, then sum that to a simple moving average.
This process is shorter than the classical least-squares moving average method.
Z-Score Derivation And The Inverse Fisher Transform
The FLSMA will use a similar approach to the line rescaling technique but instead of using the correlation during step 2 we will use an alternative calculated from the error between the estimate and the price.
In order to do so we must use the inverse fisher transform, the inverse fisher transform can take a z-score and scale it in a range of (1,-1), it is possible to estimate the correlation with it. First lets create our modified z-score in the form of : Z = ma((y - Y)/e) where y is the price, Y our output estimate and e the moving average absolute error between the price and Y and lets call it scaled smoothed error , then apply the inverse fisher transform : r = IFT(Z) = tanh(Z) , we then multiply the z-score of the line with it.
Performance
The FLSMA greatly reduce the overshoots, this mean that the maximas of abs(r) are lower than the maxima's of the absolute correlation, such case is not "bad" but we can see that the filter is not closer to the price than the LSMA during trending periods, we can assume the filter don't reduce least-squares as well as the LSMA.
The image above is the running mean of the absolute error of each the FLSMA (in red) and the LSMA (in blue), we could fix this problem by multiplying the smooth scaled error by p where p can be any number, for example :
z = sma(src - nz(b ,src),length)/e * p where p = 2
In red the FLSMA and in blue the FLSMA with p = 2 , the greater p is the less lag the FLSMA will have.
Conclusion
It could be possible to get better results than the LSMA with such design, the presented indicator use its own correlation replacement but it is possible to use anything in a range of (1,-1) to multiply the line z-score. Although the proposed filter only reduce overshoots without keeping the accuracy of the LSMA i believe the code can be useful for others.
Thanks for reading.

Many Moving AveragesThis script allows you to add two moving averages to a chart, where the type of moving average can be chosen from a collection of 15 different moving average algorithms. Each moving average can also have different lengths and crossovers/unders can be displayed and alerted on.
The supported moving average types are:
Simple Moving Average ( SMA )
Exponential Moving Average ( EMA )
Double Exponential Moving Average ( DEMA )
Triple Exponential Moving Average ( TEMA )
Weighted Moving Average ( WMA )
Volume Weighted Moving Average ( VWMA )
Smoothed Moving Average ( SMMA )
Hull Moving Average ( HMA )
Least Square Moving Average/Linear Regression ( LSMA )
Arnaud Legoux Moving Average ( ALMA )
Jurik Moving Average ( JMA )
Volatility Adjusted Moving Average ( VAMA )
Fractal Adaptive Moving Average ( FRAMA )
Zero-Lag Exponential Moving Average ( ZLEMA )
Kauman Adaptive Moving Average ( KAMA )
Many of the moving average algorithms were taken from other peoples' scripts. I'd like to thank the authors for making their code available.
JayRogers
Alex Orekhov (everget)
Alex Orekhov (everget)
Joris Duyck (JD)
nemozny
Shizaru
KobySK
Jurik Research and Consulting for inventing the JMA.
R2-Adaptive RegressionIntroduction
I already mentioned various problems associated with the lsma, one of them being overshoots, so here i propose to use an lsma using a developed and adaptive form of 1st order polynomial to provide several improvements to the lsma. This indicator will adapt to various coefficient of determinations while also using various recursions.
More In Depth
A 1st order polynomial is in the form : y = ax + b , our indicator however will use : y = a*x + a1*x1 + (1 - (a + a1))*y , where a is the coefficient of determination of a simple lsma and a1 the coefficient of determination of an lsma who try to best fit y to the price.
In some cases the coefficient of determination or r-squared is simply the squared correlation between the input and the lsma. The r-squared can tell you if something is trending or not because its the correlation between the rough price containing noise and an estimate of the trend (lsma) . Therefore the filter give more weight to x or x1 based on their respective r-squared, when both r-squared is low the filter give more weight to its precedent output value.
Comparison
lsma and R2 with both length = 100
The result of the R2 is rougher, faster, have less overshoot than the lsma and also adapt to market conditions.
Longer/Shorter terms period can increase the error compared to the lsma because of the R2 trying to adapt to the r-squared. The R2 can also provide good fits when there is an edge, this is due to the part where the lsma fit the filter output to the input (y2)
Conclusion
I presented a new kind of lsma that adapt itself to various coefficient of determination. The indicator can reduce the sum of squares because of its ability to reduce overshoot as well as remaining stationary when price is not trending. It can be interesting to apply exponential averaging with various smoothing constant as long as you use : (1- (alpha+alpha1)) at the end.
Thanks for reading

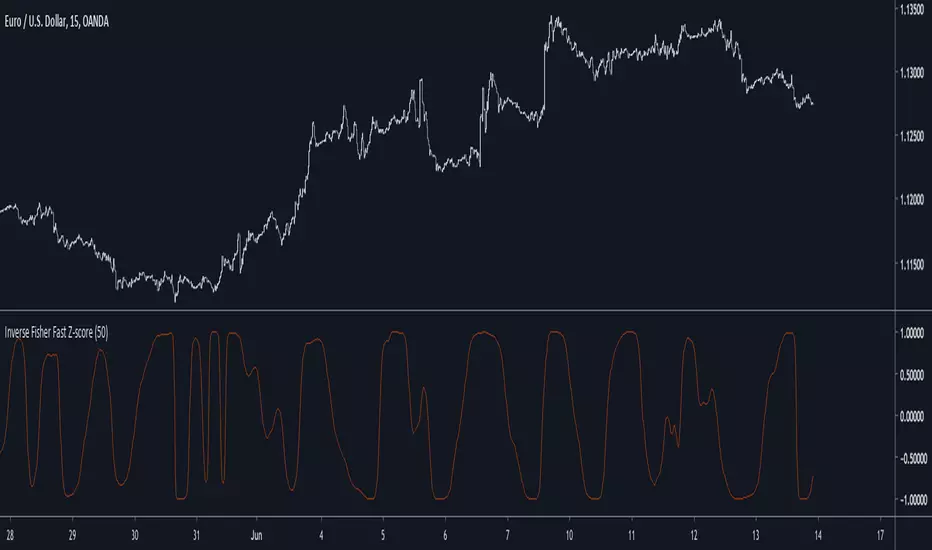
Inverse Fisher Fast Z-scoreIntroduction
The fast z-score is a modification of the classic z-score that allow for smoother and faster results by using two least squares moving averages, however oscillators of this kind can be hard to read and modifying its shape to allow a better interpretation can be an interesting thing to do.
The Indicator
I already talked about the fisher transform, this statistical transform is originally applied to the correlation coefficient, the normal transform allow to get a result similar to a smooth z-score if applied to the correlation coefficient, the inverse transform allow to take the z-score and rescale it in a range of (1,-1), therefore the inverse fisher transform of the fast z-score can rescale it in a range of (1,-1).
inverse = (exp(k*fz) - 1)/(exp(k*fz) + 1)
Here k will control the squareness of the output, an higher k will return heavy side step shapes while a lower k will preserve the smoothness of the output.
Conclusion
The fisher transform sure is useful to kinda filter visual information, it also allow to draw levels since the rescaling is in a specific range, i encourage you to use it.
Notes
During those almost 2 weeks i was even lazier and sadder than ever before, so i think its no use to leave, i also have papers to publish and i need tv for that.
Thanks for reading !
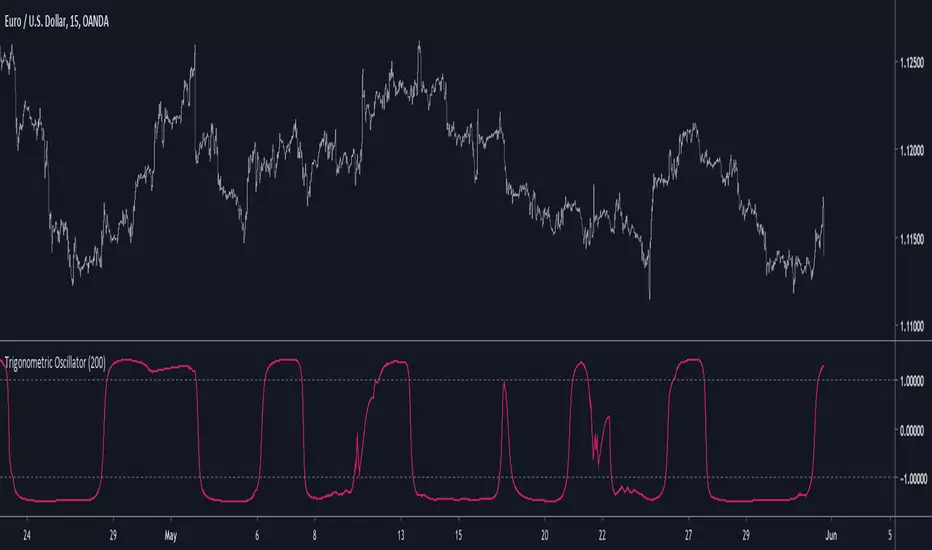
Trigonometric OscillatorIts a pretty old script and i have absolutely no idea how i did it, the code kinda look like the phase wrapping/unwrapping formula. This indicator is an oscillator, sometimes its reactivity is impressive so i think its a good idea to post it, feel free to experiment with it.
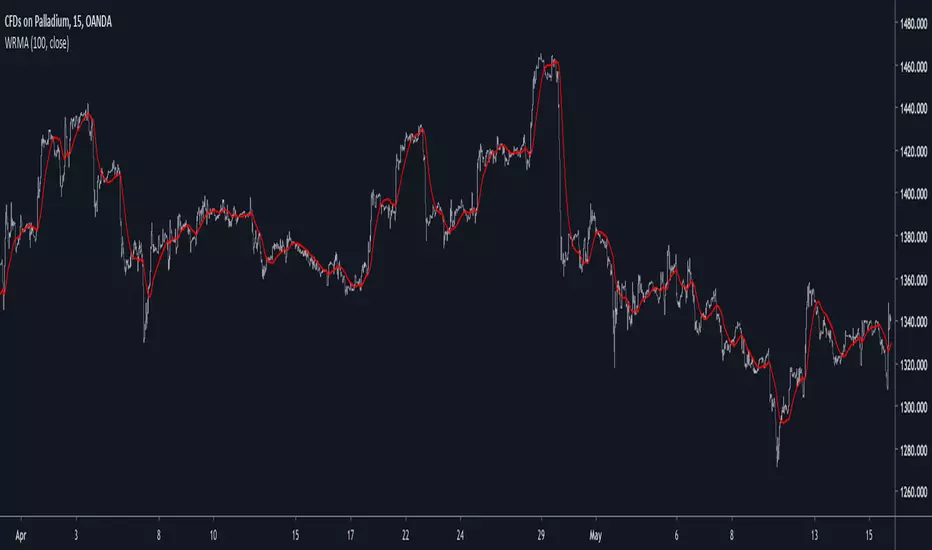
Well Rounded Moving AverageIntroduction
There are tons of filters, way to many, and some of them are redundant in the sense they produce the same results as others. The task to find an optimal filter is still a big challenge among technical analysis and engineering, a good filter is the Kalman filter who is one of the more precise filters out there. The optimal filter theorem state that : The optimal estimator has the form of a linear observer , this in short mean that an optimal filter must use measurements of the inputs and outputs, and this is what does the Kalman filter. I have tried myself to Kalman filters with more or less success as well as understanding optimality by studying Linear–quadratic–Gaussian control, i failed to get a complete understanding of those subjects but today i present a moving average filter (WRMA) constructed with all the knowledge i have in control theory and who aim to provide a very well response to market price, this mean low lag for fast decision timing and low overshoots for better precision.
Construction
An good filter must use information about its output, this is what exponential smoothing is about, simple exponential smoothing (EMA) is close to a simple moving average and can be defined as :
output = output(1) + α(input - output(1))
where α (alpha) is a smoothing constant, typically equal to 2/(Period+1) for the EMA.
This approach can be further developed by introducing more smoothing constants and output control (See double/triple exponential smoothing - alpha-beta filter) .
The moving average i propose will use only one smoothing constant, and is described as follow :
a = nz(a ) + alpha*nz(A )
b = nz(b ) + alpha*nz(B )
y = ema(a + b,p1)
A = src - y
B = src - ema(y,p2)
The filter is divided into two components a and b (more terms can add more control/effects if chosen well) , a adjust itself to the output error and is responsive while b is independent of the output and is mainly smoother, adding those components together create an output y , A is the output error and B is the error of an exponential moving average.
Comparison
There are a lot of low-lag filters out there, but the overshoots they induce in order to reduce lag is not a great effect. The first comparison is with a least square moving average, a moving average who fit a line in a price window of period length .
Lsma in blue and WRMA in red with both length = 100 . The lsma is a bit smoother but induce terrible overshoots
ZLMA in blue and WRMA in red with both length = 100 . The lag difference between each moving average is really low while VWRMA is way more precise.
Hull MA in blue and WRMA in red with both length = 100 . The Hull MA have similar overshoots than the LSMA.
Reduced overshoots moving average (ROMA) in blue and WRMA in red with both length = 100 . ROMA is an indicator i have made to reduce the overshoots of a LSMA, but at the end WRMA still reduce way more the overshoots while being smoother and having similar lag.
I have added a smoother version, just activate the extra smooth option in the indicator settings window. Here the result with length = 200 :
This result is a little bit similar to a 2 order Butterworth filter. Our filter have more overshoots which in this case could be useful to reduce the error with edges since other low pass filters tend to smooth their amplitude thus reducing edge estimation precision.
Conclusions
I have presented a well rounded filter in term of smoothness/stability and reactivity. Try to add more terms to have different results, you could maybe end up with interesting results, if its the case share them with the community :)
As for control theory i have seen neural networks integrated to Kalman flters which leaded to great accuracy, AI is everywhere and promise to be a game a changer in real time data smoothing. So i asked myself if it was possible for a neural networks to develop pinescript indicators, if yes then i could be replaced by AI ? Brrr how frightening.
Thanks for reading :)
Smoothed Delta's Ratio OscillatorIntroduction
Scaled and smoothed oscillators can provide easy to read/use information regarding price, therefore i will introduce a new oscillator who create smooth results and use a fast and practical scaling method. In order to allow for even more smoothness the option to smooth the input with a lsma has been added.
Scaling Using Changes
In this indicator scaling in a range of (1,-1) is achieved through the following calculations :
a = sma(abs(change(src,length)),length)
b = change(sma(src,length),length)
c = b/a
where src is our input. The two elements a and b are quite similar, a smooth the absolute change of the input over length period while b calculate the change of the smoothed input over length period, this make a > b and able us to perform scaling in a range of (1,-1).
The Indicator Parameters
Length control the differencing/smoothing period of the indicator, greater values create smoother and less volatile results, this mean that the oscillator will tend to be equal to 1 or -1 in a longer period of time if length is high. The smooth option allow for even smoother results by enabling the input to be smoothed by a lsma of length period.
Conclusions
I presented a smooth oscillator using a new rescaling technique. Parameters can be separated to provide different results, i believe the code is simple enough for everyone to modify it in order to provide interesting creations.

Linear Quadratic Convergence Divergence OscillatorIntroduction
I inspired myself from the MACD to present a different oscillator aiming to show more reactive/predictive information. The MACD originally show the relationship between two moving averages by subtracting one of fast period and another one of slow period. In my indicator i will use a similar concept, i will subtract a quadratic least squares moving average with a linear least squares moving average of same period, since the quadratic least squares moving average is faster than the linear one and both methods have low-lag this will result in a reactive oscillator.
LQCD In Details
A quadratic least squares moving average try to fit a quadratic function (parabola) to the price by using the method of least squares, the linear least squares moving average try to fit a line. Non-linear fit tend to minimize the sum of squares in non-linear data, this is why a quadratic method is more reactive. The difference of both filters give us an oscillator, then we apply a simple moving average to this oscillator to provide the signal line, subtracting the oscillator and its signal line give us the histogram, those two last steps are the same used in the MACD.
Length control the period of the quadratic/linear moving average. While the MACD use a signal line for plotting the histogram i also added the option to plot the momentum of the quadratic moving average instead, the result is smoother and reduce irregularities, in order to do so just check the differential option in the parameter box.
The period of the signal line and the momentum are both controlled by the signal parameter.
A predictive approach can be made by subtracting the histogram with the signal line, this process make the histogram way more predictive, in order to do so just check the predictive histogram option in the parameter box.
Predictive histogram with simple histogram option. The differential mode can also be used with the predictive parameter, this result in a smoother but less reactive prediction.
Information Interpretation
The amount of information the MACD can give us is high. We can use the histogram as signal generator, or the if the oscillator is over/under 0, combine the oscillator/signal line with histogram, combinations can provide various systems. Some traders use the histogram as signal generator and use the cross between the histogram and the signal line as a stop signal, this method can avoid some whipsaw trades. The study of divergences with the price is also another method.
Conclusion
This oscillator aim to show the same amount of information as the MACD with a similar calculation method but using different kind of filters as well as eliminating the need to use two separates periods for the moving averages calculation, its still possible to use different periods for the quadratic/linear moving average but the results can be less accurate. This indicator can be used like the MACD.

Least Squares Moving Average With Overshoot ReductionIntroduction
The ability to reduce lag while keeping a good level of stability has been a major challenge for smoothing filters in technical analysis. Stability involve many parameters, one of them being overshoots. Overshoots are a common effect induced by low-lagging filters, they are defined as the ability of a signal output to exceed a target input. This effect can lead to major drawbacks such as whipsaw and reduction of precision. I propose a modification of the least squares moving average "Reduced Overshoots Moving Average" (ROMA) to reduce overshoots induced by the lsma by using a scaled recursive dispersion coefficient with the purpose of reducing overshoots.
Overshoots - Causes and Effects
Control theory and electronic engineering use step response to measure overshoots, the target signal is defined as an heaviside step function which will be used as input signal for our filter.
In white an input signal, in blue a least squares moving average with the input signal as source, the circle show the overshoot induced by the lsma, the filter exceed drastically the target input. But why low lag filters often induce overshoots ? This is because in order to reduce lag those filter will increase certain frequencies of the input signal, this reduce lag but induce overshoots because the amplitude of those frequencies have been increased, so its normal for the filter to exceed the input target. The increase of frequencies is not a bad process but when those frequencies are already of large amplitudes (high volatility periods) the overshoots can be seen.
Comparison With ROMA
Our method will use the line rescaling technique to estimate the lsma for efficiency sake. This method involve calculating the z-score of a line and multiplying it by the correlation of the line and the target input (price). Then we rescale this result by adding this z-score multiplied by the dispersion coefficient to a simple moving average. Lets compare the step response of our filer and the lsma.
ROMA (in red) need more data to be computed but reduce the mean absolute error in comparison with the classic lsma, it is seen that instead of following increasing, ROMA decrease thus ending with an undershoot.
ROMA in (red) and an lsma (in blue) with both length = 14, ROMA decrease overshoots with the cost of less smoothing, both filter match when there are no overshoots situations.
Both filters with length = 200, large periods increase the amplitude of overshoots, ROMA stabilize early at the cost of some smoothness.
The running Mean Absolute Error of both filters with length = 100, ROMA (in red) is on average closer to the price than the lsma (in blue)
Conclusion
I presented a modification of the least squares moving average with the goal to provide both stability and rapidity, the statistics show that ROMA do a better job when it comes to reduce the mean absolute error. Alternatives methods can involve decreasing the period it take for the filter to be on a steady state (reducing filter period during high volatility periods) , various filters already exploit this method.
Side Project
I'am not that good when it come to make my post easy to read, this is why i'am currently making an article explaining the basis of digital signal processing. This post will help you to understand signals and things such as lag, frequency transform, cycles, overshoots, ringing, FIR/IIR filters, impulse response, convolution, filter topology and many more. I love to post indicators but also making more educational content as well, so stay tuned :)
Thanks for reading, let me know if you need help with something, i would be happy to assist you.
please be kind to notify me if you find errors about the indicator in order for me to update it as fast as possible.

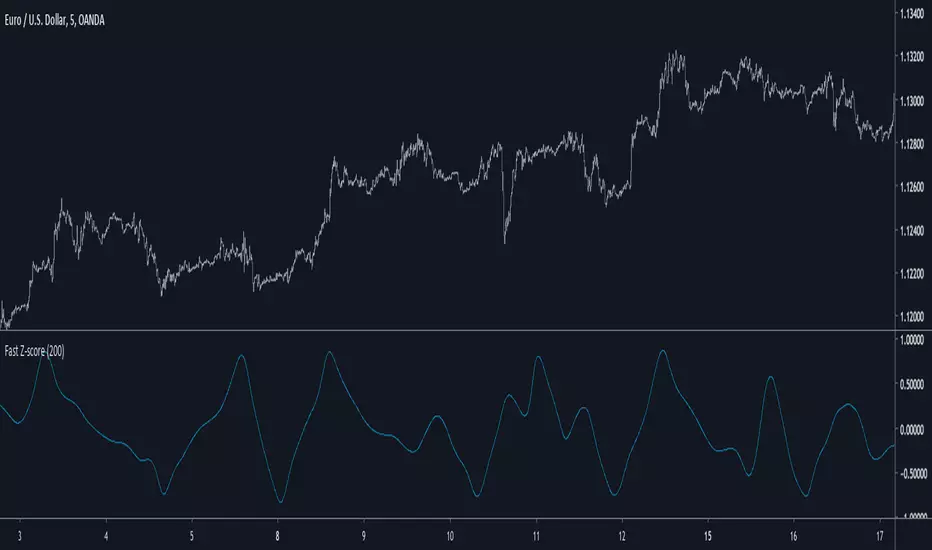
Fast Z-ScoreIntroduction
The ability of the least squares moving average to provide a great low lag filter is something i always liked, however the least squares moving average can have other uses, one of them is using it with the z-score to provide a fast smoothing oscillator.
The Indicator
The indicator aim to provide fast and smooth results. length control the smoothness.
The calculation is inspired from my sample correlation coefficient estimation described here
Instead of using the difference between a moving average of period length/2 and a moving average of period length , we use the difference between a lsma of period length/2 and a lsma of period length , this difference is then divided by the standard deviation. All those calculations use the price smoothed by a moving average as source.
The yellow version don't divide the difference by a standard deviation, you can that it is less reactive. Both version have length = 200
Conclusion
I presented a smooth and responsive version of a z-score, the result could be used to estimate an even faster lsma by using the line rescaling technique and our indicator as correlation coefficient.
Hope you like it, feel free to modify it and share your results ! :)
Notes
I have been requested a lot of indicators lately, from mt4 translations to more complex time series analysis methods, this accumulation of work made that it is impossible for me to publish those within a short period of time, also some are really complex. I apologize in advance for the inconvenience, i will try to do my best !
Linear Regression Curve - AverageIdea is that the average of price has something to do with sudden changes in trend. Finding trend shifts in mundane.
General Filter Estimator-An Experiment on Estimating EverythingIntroduction
The last indicators i posted where about estimating the least squares moving average, the task of estimating a filter is a funny one because its always a challenge and it require to be really creative. After the last publication of the 1LC-LSMA , who estimate the lsma with 1 line of code and only 3 functions i felt like i could maybe make something more flexible and less complex with the ability to approximate any filter output. Its possible, but the methods to do so are not something that pinescript can do, we have to use another base for our estimation using coefficients, so i inspired myself from the alpha-beta filter and i started writing the code.
Calculation and The Estimation Coefficients
Simplicity is the key word, its also my signature style, if i want something good it should be simple enough, so my code look like that :
p = length/beta
a = close - nz(b ,close)
b = nz(b ,close) + a/p*gamma
3 line, 2 function, its a good start, we could put everything in one line of code but its easier to see it this way. length control the smoothing amount of the filter, for any filter f(Period) Period should be equal to length and f(Period) = p , it would be inconvenient to have to use a different length period than the one used in the filter we want to estimate (imagine our estimation with length = 50 estimating an ema with period = 100) , this is where the first coefficients beta will be useful, it will allow us to leave length as it is. In general beta will be greater than 1, the greater it will be the less lag the filter will have, this coefficient will be useful to estimate low lagging filters, gamma however is the coefficient who will estimate lagging filters, in general it will range around .
We can get loose easily with those coefficients estimation but i will leave a coefficients table in the code for estimating popular filters, and some comparison below.
Estimating a Simple Moving Average
Of course, the boxcar filter, the running mean, the simple moving average, its an easy filter to use and calculate.
For an SMA use the following coefficients :
beta = 2
gamma = 0.5
Our filter is in red and the moving average in white with both length at 50 (This goes for every comparison we will do)
Its a bit imprecise but its a simple moving average, not the most interesting thing to estimate.
Estimating an Exponential Moving Average
The ema is a great filter because its length times more computing efficient than a simple moving average. For the EMA use the following coefficients :
beta = 3
gamma = 0.4
N.B : The EMA is rougher than the SMA, so it filter less, this is why its faster and closer to the price
Estimating The Hull Moving Average
Its a good filter for technical analysis with tons of use, lets try to estimate it ! For the HMA use the following coefficients :
beta = 4
gamma = 0.85
Looks ok, of course if you find better coefficients i will test them and actualize the coefficient table, i will also put a thank message.
Estimating a LSMA
Of course i was gonna estimate it, but this time this estimation does not have anything a lsma have, no moving average, no standard deviation, no correlation coefficient, lets do it.
For the LSMA use the following coefficients :
beta = 3.5
gamma = 0.9
Its far from being the best estimation, but its more efficient than any other i previously made.
Estimating the Quadratic Least Square Moving Average
I doubted about this one but it can be approximated as well. For the QLSMA use the following coefficients :
beta = 5.25
gamma = 1
Another ok estimate, the estimate filter a bit more than needed but its ok.
Jurik Moving Average
Its far from being a filter that i like and its a bit old. For the comparison i will use the JMA provided by @everget described in this article : c.mql5.com
For the JMA use the following coefficients :
for phase = 0
beta = pow*2 (pow is a parameter in the Jma)
gamma = 0.5
Here length = 50, phase = 0, pow = 5 so beta = 10
Looks pretty good considering the fact that the Jma use an adaptive architecture.
Discussion
I let you the task to judge if the estimation is good or not, my motivation was to estimate such filters using the less amount of calculations as possible, in itself i think that the code is quite elegant like all the codes of IIR filters (IIR Filters = Infinite Impulse Response : Filters using recursion) .
It could be possible to have a better estimate of the coefficients using optimization methods like the gradient descent. This is not feasible in pinescript but i could think about it using python or R.
Coefficients should be dependant of length but this would lead to a massive work, the variation of the estimation using fixed coefficients when using different length periods is just ok if we can allow some errors of precision.
I dont think it should be possible to estimate adaptive filter relying a lot on their adaptive parameter/smoothing constant except by making our coefficients adaptive (gamma could be)
So at the end ? What make a filter truly unique ? From my point of sight the architecture of a filter and the problem he is trying to solve is what make him unique rather than its output result. If you become a signal, hide yourself into noise, then look at the filters trying to find you, what a challenging game, this is why we need filters.
Conclusion
I wanted to give a simple filter estimator relying on two coefficients in order to estimate both lagging and low-lagging filters. I will try to give more precise estimate and update the indicator with new coefficients.
Thanks for reading !
1LC-LSMA (1 line code lsma with 3 functions)Even Shorter Estimation
I know that i'am insistent with the lsma but i really like it and i'm happy to deconstruct it like a mad pinescript user. But if you have an idea about some kind of indicator then dont hesitate to contact me, i would be happy to help you if its feasible.
My motivation for such indicator was to use back the correlation function (that i had putted aside in the ligh-lsma code) and provide a shorter code than the estimation using the line rescaling method (see : Approximating A Least Square Moving Average In Pine) .
The Method
Fairly simple, lets name y our estimation, we calculate it as follow:
y = x̄ + r*o*1.7
where x̄ is the price moving average, r the correlation between the price and a line (or n) and o the standard deviation. If plotted against a classic lsma the difference would be meaningless at first glance so lets plot the absolute value between the difference of the lsma and our estimation of both period 100.
The difference is under 0.0000 on eurusd, its really low.
In general the longer the period of the estimation, the lower the difference between a normal lsma, but when using shorter period they can differ a little bit.
Why 1.7 ?
We need to multiply the standard deviation by a constant in order to match the overshoot and the rise-time of the original lsma. The constant 1.7 is one that work well but actually this constant should be dependant of the length period of the filter to make the estimation more accurate.
More About Step-Response
Most of the time when a filter have less lag, it mean that he induce overshoot in order to decrease the rise-time . Rise-time is the time the output take to match the target input, its related to the lag. Overshoot mean that the output exceed the target input, you can clearly see those concept in the image above.
Conclusion
I've showed that its possible to be even more concise about the code it take to estimate an lsma. I've also briefly explained the concept of rise-time and overshoot, concepts really important to signal processing and particularly in filter design. I'm sure that it can be even more simplified and i have some ideas for such estimate.
Thanks for reading !

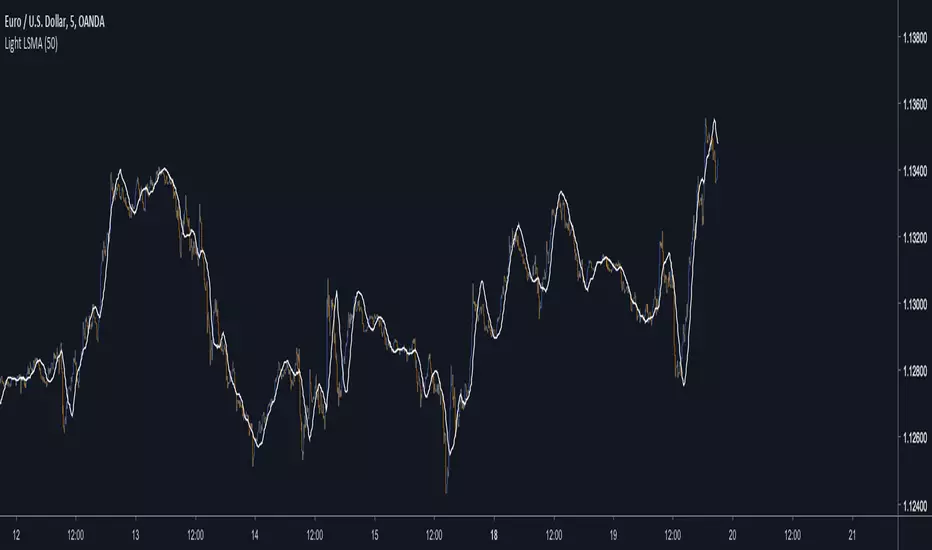
Light LSMAEstimating the LSMA Without Classics Parameters
I already mentioned various methods in order to estimate the LSMA in the idea i published. The parameter who still appeared on both the previous estimation and the classic LSMA was the sample correlation coefficient. This indicator will use an estimate of the correlation coefficient using the standard score thus providing a totally different approach in the estimation of the LSMA. My motivation for such indicator was to provide a different way to estimate a LSMA.
Standardization
The standard score is a statistical tool used to measure at how many standard deviations o a data point is bellow or above its mean. It can also be used to rescale variables, this conversion process is called standardizing or normalizing and it will be the basis of our estimation.
Calculation : (x - x̄)/o where x̄ is the moving average of x and o the standard deviation.
Estimating the Correlation Coefficient
We will use standardization to estimate the correlation coefficient r . 1 > r > -1 so in (y - x̄)/o we want to find y such that y is always above or below 1 standard deviation of x̄ , i had for first idea to pass the price through a band-stop filter but i found it was better to just use a moving average of period/2 .
Estimating the LSMA
We finally rescale a line through the price like mentioned in my previous idea, for that we standardize a line and we multiply the result by our correlation estimation, next we multiply the previous calculation by the price standard deviation, then we sum this calculation to the price moving average.
Comparison of our estimate in white with a LSMA in red with both period 50 :
Working With Different Independents Variables
Here the independent variable is a line n (which represent the number of data point and thus create a straight line) but a classic LSMA can work with other independent variables, for exemple if a LSMA use the volume as independent variable we need to change our correlation estimate with (ȳ - x̄)/ô where ȳ is the moving average of period length/2 of y, y is equal to : change(close,length)*change(volume,length) , x̄ is the moving average of y of period length , and ô is the standard deviation of y. This is quite rudimentary and if our goal is to provide a easier way to calculate correlation then the product-moment correlation coefficient would be more adapted (but less reactive than the sample correlation) .
Conclusion
I showed a way to estimate the correlation coefficient, of course some tweaking could provide a better estimate but i find the result still quite close to the LSMA.
Function for Least Squares Moving AverageThank you to alexgrover for putting me wide to this, after putting up with long conversations and stupid questions. Follow him and behold: www.tradingview.com
What is this?
This is simply the function for a Least Squares Moving Average. You can render this on the chart by using the linreg() function in Pine.
Personally I like to use the slope of the LSMA to help determine what direction to take a trade in, but I'm sure there are other, more exotic ways of using it and, if you know how to get your fingers dirty with Pine, you can create more exotic versions of it by modifying the function provided.
Want to learn?
If you'd like the opportunity to learn Pine but you have difficulty finding resources to guide you, take a look at this rudimentary list: docs.google.com
The list will be updated in the future as more people share the resources that have helped, or continue to help, them. Follow me on Twitter to keep up-to-date with the growing list of resources.
Suggestions or Questions?
Don't even kinda hesitate to forward them to me. My (metaphorical) door is always open.
